
はじめに
AIチャットを日本語で使うとき、回答の自然さや正確さに不安を感じたことはないでしょうか。Claudeは多言語に対応した大規模言語モデルとして、日本語でも高い精度を発揮すると報告されています。
この記事では、Claudeの日本語対応の仕組みやベンチマークの数値、実際の使い方のコツ、そして企業や教育機関での導入事例まで、押さえておきたいポイントを順に取り上げます。
Claudeとは?日本語対応の全体像
Claudeの概要と主要モデルの種類
ClaudeはAnthropic社が開発した大規模言語モデルで、テキスト生成や翻訳、コーディング支援など幅広い用途に対応します。モデルには複数のラインナップがあり、用途や予算に応じて使い分けられる点が特徴です。
たとえば日本語のビジュアルノベル翻訳を対象とした検証では、Claude 3 Haikuが速度・価格・翻訳品質の最良のバランスを提供するモデルとして挙げられています。3秒未満の応答を低コストで実現できることから、リアルタイム性が求められる場面にも適用できるとの評価です(参照*1)。
このように、Claudeは目的ごとにモデルを選択できる構成になっています。日本語を扱う場合も、求める応答速度や精度に合わせてモデルを比較することが実践的な第一歩です。
多言語サポートの仕組みと日本語の位置づけ
Claudeは堅牢な多言語能力を備えており、特に言語間のゼロショットタスクで高い性能を示します。ゼロショットタスクとは、事前に例を与えなくても正しい回答を導く処理のことです。広く話される言語だけでなく、学習データが少ない言語でも一貫した相対的パフォーマンスを維持するため、多言語で使うアプリケーションにとって信頼できる選択肢となっています(参照*2)。
日本語は話者数が多く、ビジネス文書や技術文書での需要も高い言語です。Claudeの公式ドキュメントでは、英語を基準(100%)としたMMLU英語テストセットに基づくゼロショット評価スコアとして、日本語の数値が公開されています。日本語の性能を把握するには、次章で扱うベンチマークの数値を確認することが有効です。
Claudeの日本語精度を検証する:ベンチマークと評価データ
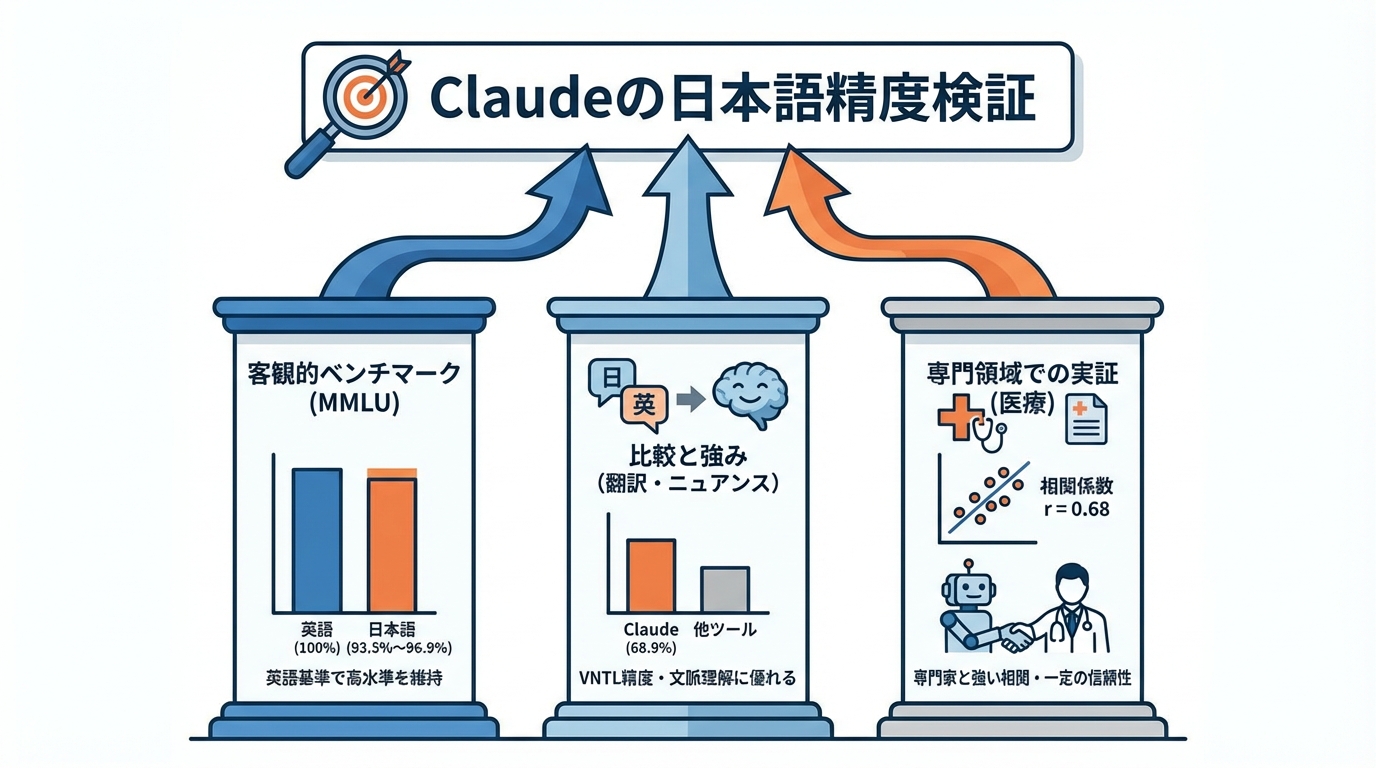
MMLUベンチマークにおける日本語スコア
Claudeの日本語性能を客観的に見る指標として、MMLU英語テストセットに基づくゼロショット評価スコアが公開されています。MMLUは、さまざまな教科や専門知識にわたる問題を解かせることでモデルの理解力を数値化するテストです。
Claudeの公式ドキュメントによると、日本語のスコアはモデルの世代や種類に応じて93.5%から96.9%の範囲に分布しています。数値の並びは96.9%、96.2%、96.8%、95.6%、93.5%です(参照*2)。
これらのスコアは英語のパフォーマンスを基準(100%)とした相対値であり、日本語でも英語に近い水準で評価スコアを維持していることを示します。実務で日本語の回答品質を見極める際には、こうしたベンチマーク数値を基準の1つとして把握しておくと判断材料になります。
他言語との比較から見る日本語の強みと弱み
Claudeの日本語性能を理解するうえで、他の言語との比較も手がかりになります。日本語のビジュアルノベル翻訳に特化したリーダーボード「VNTL」では、Claude 3 Haikuが68.9%の精度と評価されました。同じリーダーボードで、Sugoi Translatorは60.9%、Google Translateは53.9%であり、Claude 3 Haikuはこれらの従来型の機械翻訳ツールを大幅に上回っています(参照*1)。
さらに利用者からのフィードバックとして、Claudeモデルは対話の「語調・スタイル・ニュアンス」を捉えるのに優れているとの声があります。カジュアルな話し方、敬語、主語の省略といった日本語特有の表現を含むコンテンツでも、文脈を読み取る能力が高いと評価されています。こうした強みを踏まえると、日本語での創作的な文章や会話文の翻訳においてClaudeがどの程度使えるのか、実際のタスクで試してみることが判断の近道です。
日本語医療情報評価における実証研究の結果
日本語の精度は一般的な言語タスクだけでなく、専門性の高い領域でも検証されています。医療情報の評価に関する実証研究では、大規模言語モデルによる評価と専門家による評価の相関が調べられました。
この研究によると、Claudeと専門家の評価の相関係数はr = 0.68で、中程度から強い相関を示しています。比較対象として、ChatGPTと専門家の相関係数はr = 0.65でした。また、大規模言語モデルは専門評価者よりもわずかに高いスコアを付ける傾向が確認されています(参照*3)。
この結果から読み取れるのは、Claudeが日本語の医療情報という専門的な文脈でも、一定の信頼性を持って評価を行えるという点です。ただし、モデルが専門家より高めにスコアを付ける傾向がある点は、最終判断を人間が行う運用設計とセットで考える必要があります。
Claudeを日本語で使いこなす方法とベストプラクティス
日本語プロンプトの書き方と精度向上のコツ
Claudeに日本語で指示を出す際、ちょっとした書き方の工夫で回答の精度が変わります。公式ドキュメントでは、いくつかの実践的な指針が示されています。
まず、Claudeは入力の言語を自動検出できますが、入力と出力の言語を明示的に指定すると信頼性が高まります。また、ネイティブスピーカーのような慣用的な表現を使うよう促すことで、より自然な日本語の出力を引き出せます。テキストはローマ字などの音写ではなく、漢字やひらがなといった元のスクリプトで提出するのが最適です(参照*2)。
実際の作業としては、プロンプトの冒頭に「日本語で回答してください」と明記し、求める文体や口調を具体的に指定することが有効です。敬語で書いてほしいのか、カジュアルな表現がよいのか、用途に応じて条件を絞り込むと意図通りの結果を得やすくなります。
個人設定・プロジェクト機能の活用
Claudeには個人設定やプロジェクト単位の設定機能があり、日本語での利用効率を大きく高められます。これらの設定は、毎回の会話で繰り返し同じ指示を書く手間を省くための仕組みです。
Claudeの個人設定に入力した内容は、システムプロンプトのように扱われます。つまり、一度ここに方針を書き込めば、その後のすべての会話に自動で反映されるということです。ある解説では「ここでの1つの更新は、後の1000件の明確化メッセージに相当します」と表現されています(参照*4)。
日本語を常用する場合、「回答はすべて日本語で」「敬語を使う」「専門用語にはカッコ内に英語表記を添える」といったルールを個人設定に入れておくと、会話のたびに指示を繰り返す必要がなくなります。プロジェクト機能を使えば、特定の案件ごとに異なる日本語の文体やルールを設定することもできます。
翻訳・文書作成・コーディング支援の具体的な使い方
Claudeの日本語対応は、翻訳や文書作成、コーディング支援などさまざまな実務で活用されています。使い方の工夫次第で、出力の品質を大きく引き上げることができます。
翻訳の分野では、孤立した1行ずつの機械翻訳から、文脈を考慮した連続的なバッチ翻訳へ移行し、さらにマルチパスの見直しプロセスや自動的に維持される翻訳の一貫性ガイドを組み合わせたアプローチが報告されています。こうした工程を経ることで、翻訳の品質は主観的に大幅に向上したとのことです(参照*5)。
日本語学習の用途としては、Claude Proの契約者が日本語学習プラグインを自作し、日々の先生としてClaude Codeを使っている事例もあります(参照*6)。翻訳では文脈付きのバッチ処理と見直し工程を組む、文書作成では個人設定で文体を固定する、コーディング支援では日本語のコメントを添えて指示を出す、というように用途ごとにアプローチを切り替えることで実用性が高まります。
日本語利用時の注意点と技術的課題
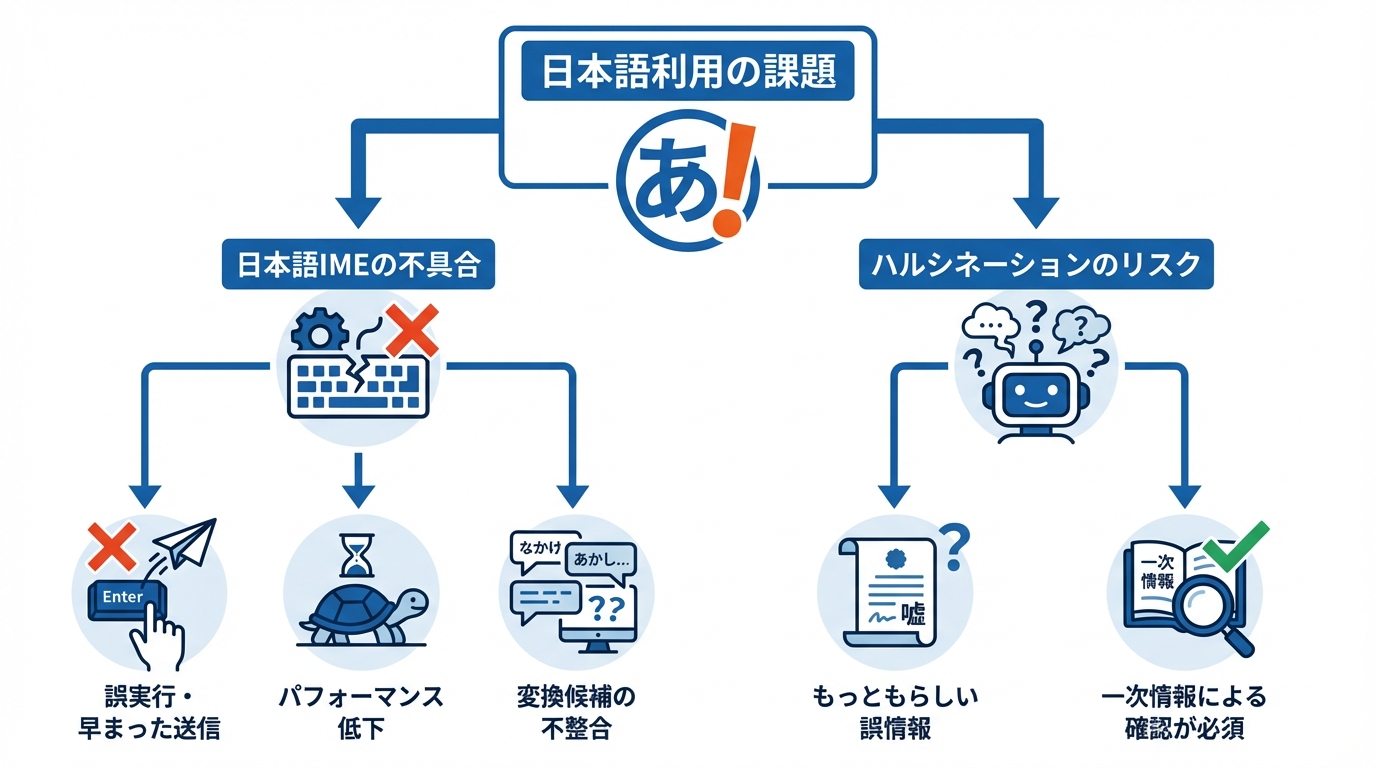
日本語IME入力に起因するClaude Codeの不具合
Claudeを日本語で使う際に見過ごせないのが、日本語入力システム(IME)とClaude Codeの互換性に関する不具合です。複数の問題がGitHub上のIssueとして報告されています。
macOSの日本語入力で漢字変換を確定するとき、意図せずコマンドが実行されてしまう問題が報告されています(参照*7)。また、VS Code拡張機能のチャット入力欄では、IMEで文字変換を確定するためにEnterキーを押すとプロンプトが早まって送信される現象が起きています。文を作成中であっても送信されてしまうため、複数回の変換を要する複雑な日本語の質問を入力するのが非常に難しくなります(参照*8)。
さらに、macOSデフォルトのIMEを使って日本語を入力すると、Claude Codeが著しく遅くなり、重複した変換候補が表示される問題も確認されています。変換候補がClaude Codeの入力欄と適切に連携せず、別のシステムポップアップに表示されることでパフォーマンスが低下します(参照*9)。日本語で日常的にClaude Codeを使う場合は、これらのIssueの進捗を確認しながら運用環境を調整することが求められます。
ハルシネーションと事実確認の重要性
Claudeに限らず、大規模言語モデルにはハルシネーション(事実に基づかない情報の生成)のリスクがあります。日本語で専門的な質問をした場合でも、もっともらしいが誤った回答が返ってくる可能性を常に意識する必要があります。
慶應義塾大学は、生成型AIの利用に関するガイドラインの中で、生成された情報は原著論文や信頼できる資料などの一次情報と照合して事実確認を行うことを強く推奨しています(参照*10)。
日本語の出力は一見して流暢に見えるため、内容の正誤に気づきにくいという落とし穴があります。業務や研究でClaudeの回答を利用する際は、出力をそのまま採用するのではなく、必ず一次情報との突き合わせを行う手順を組み込んでおくことが欠かせません。
企業・教育機関における日本語でのClaude導入事例
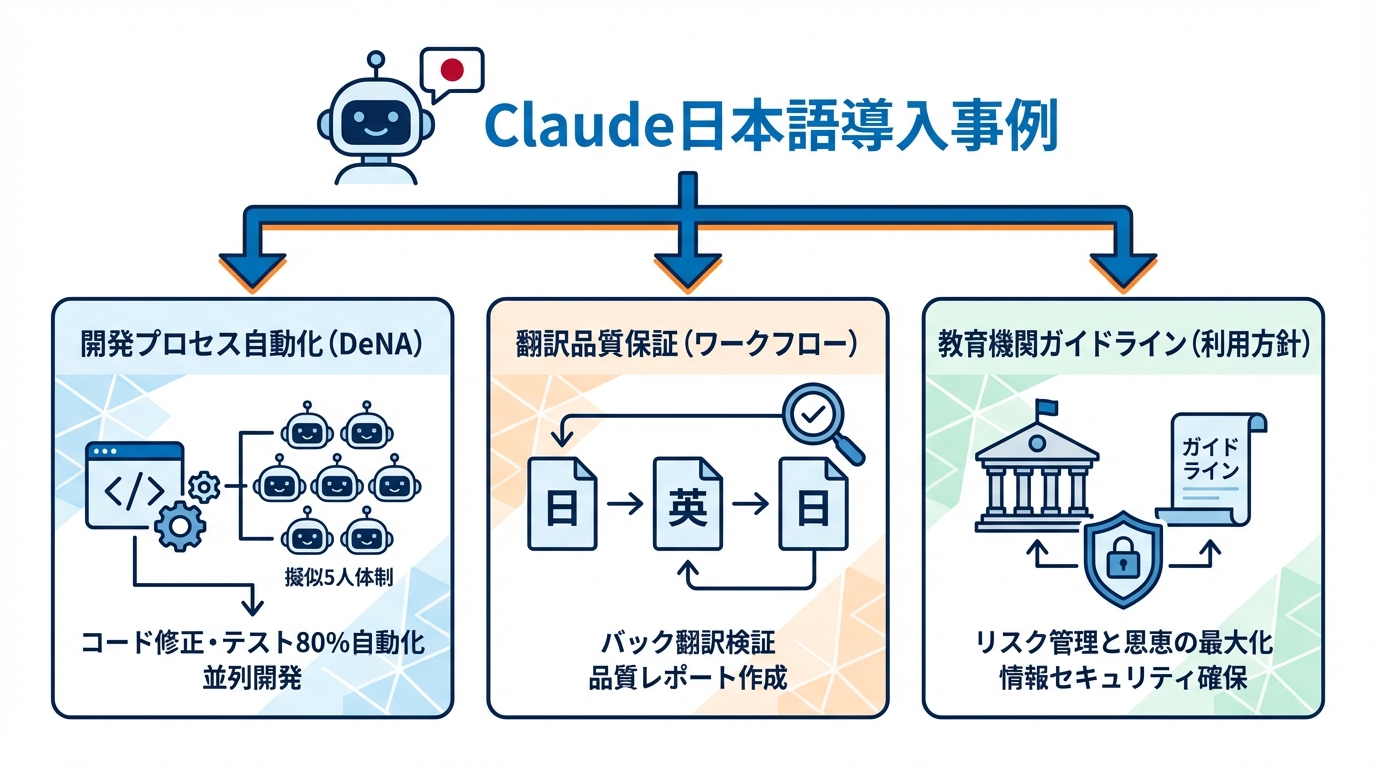
DeNAの全社AI活用とClaudeの役割
企業がClaudeを日本語環境でどのように活用しているか、具体的な事例を見ていきます。DeNAでは、全社的なAI活用の一環としてClaudeを開発プロセスに組み込んでいます。
Claudeと自律型エージェントを組み合わせることで、コード修正やテストの80%を自動化した事例が報告されています。Gitのブランチを「多窓」で運用し、1人のエンジニアが擬似的に5人体制で並列開発を進める仕組みを実現しています(参照*11)。
このような運用では、日本語でのコードコメントやドキュメント作成もClaudeが担うことになります。開発の自動化率を高めつつ、日本語での指示やレビューをどう設計するかが導入時の検討事項となります。
翻訳品質保証ワークフローへの組み込み
翻訳業務でClaudeを品質管理の仕組みに組み込む事例も登場しています。日本語文書を英語に翻訳し、その品質を自動で検証するワークフローが構築されています。
このワークフローでは、まずGoogleドライブから日本語ファイルを読み取り、Claude AIで英語に翻訳します。次に英語版を日本語に再翻訳し、元の日本語テキストと再翻訳された日本語を比較します。この比較を通じて翻訳の不一致を特定し、包括的な品質レポートを作成する流れです(参照*12)。
バック翻訳検証と呼ばれるこの手法は、翻訳の正確性を客観的に見る方法として用いられることがあります。日本語を起点とする翻訳業務にClaudeを導入する場合は、翻訳と品質検証の両方をワークフローに組み込むことで、人手によるチェック負担を削減できます。
教育機関でのガイドラインと利用方針
教育機関ではClaudeを含む生成型AIの利用に関して、ガイドラインの整備が進んでいます。学生や研究者がAIを活用する際のルールを明確にすることで、リスクを抑えながら恩恵を引き出す方針です。
慶應義塾大学は、生成型AIが学習・研究・仕事の効率を著しく向上させる可能性があるとしたうえで、その使用に伴うリスクを正しく理解し、情報セキュリティを確保しながら利点を最大化することをガイドラインの目的に掲げています。大学の各構成員にはガイドラインの内容を遵守し、責任を持って利用することを求めています(参照*10)。
日本語環境でClaudeを教育に取り入れる際は、出力内容の事実確認や機密情報の取り扱いについて、組織としての方針を先に定めておくことが実務上の前提になります。ガイドラインの策定にあたっては、先行する大学の事例を参照しながら自組織に合った運用ルールを設計する流れが実践的です。
おわりに
Claudeの日本語対応は、英語を基準(100%)としたMMLU英語テストセットに基づくゼロショット評価スコアで93.5%から96.9%という数値が示すように、高い水準を備えています。翻訳や医療情報評価など専門領域でも実用的な結果が確認されており、企業の開発自動化や翻訳品質保証にも導入が広がっています。
一方で、日本語IMEとの互換性の課題やハルシネーションへの対策は依然として必要です。Claudeを日本語で活用する際は、プロンプトの設計や個人設定の最適化、そして出力の事実確認を組み合わせたうえで、自分の用途に合った運用方法を検証していくことが大切です。
監修者
安達裕哉(あだち ゆうや)
デロイト トーマツ コンサルティングにて品質マネジメント、人事などの分野でコンサルティングに従事しその後、監査法人トーマツの中小企業向けコンサルティング部門の立ち上げに参画。大阪支社長、東京支社長を歴任したのち2013年5月にwebマーケティング、コンテンツ制作を行う「ティネクト株式会社」を設立。ビジネスメディア「Books&Apps」を運営。
2023年7月に生成AIコンサルティング、およびAIメディア運営を行う「ワークワンダース株式会社」を設立。ICJ2号ファンドによる調達を実施(1.3億円)。
著書「頭のいい人が話す前に考えていること」 が、82万部(2025年3月時点)を売り上げる。
(“2023年・2024年上半期に日本で一番売れたビジネス書”(トーハン調べ/日販調べ))
参照
- (*1) Skerritt.blog – Best OpenRouter models for real-time visual novel translation
- (*2) Claude API Docs – Multilingual support
- (*3) SpringerLink – Assessing the quality of Japanese online breast cancer treatment information using large language models: a comparison of ChatGPT, Claude, and expert evaluations – Breast Cancer
- (*4) the chatGPT and Claude settings i can’t live without (and how to steal them)
- (*5) (r,d) => blog() – How Not to Translate a Videogame (2025 ver.)
- (*6) Claude Code: My Sensei
- (*7) GitHub – [BUG]Japanese IME kanji conversion clicks trigger unintended command execution · Issue #8466 · anthropics/claude-code
- (*8) GitHub – [BUG] Pressing Enter to confirm IME (Japanese) conversion unintentionally sends the prompt · Issue #8405 · anthropics/claude-code
- (*9) GitHub – [BUG] IME input causes performance issues and duplicate conversion candidates · Issue #1547 · anthropics/claude-code
- (*10) Guideline for Generative AI Usage at Keio University
- (*11) note(ノート) – DeNAが“AIにオールイン”──現場突撃レポートで解明!リサーチ・デザイン・開発を3~4倍加速させる実践術|FPわっきー@FP×副業×AI
- (*12) Japanese Translation Quality Checker
