
はじめに
Claudeを業務や個人の作業に組み込んでいると、突然のサービス停止やエラーに直面することがあります。障害が起きたとき、原因がどこにあるのかを素早く見極め、適切に対処できるかどうかで復旧までの時間は大きく変わります。
この記事では、Claudeで実際に発生している障害の種類や原因の切り分け方、具体的なエラーへの対処法、そして障害に備えるための設計上のポイントまでを順を追って整理しています。
Claudeの障害とは?サービス停止・エラーの基本知識
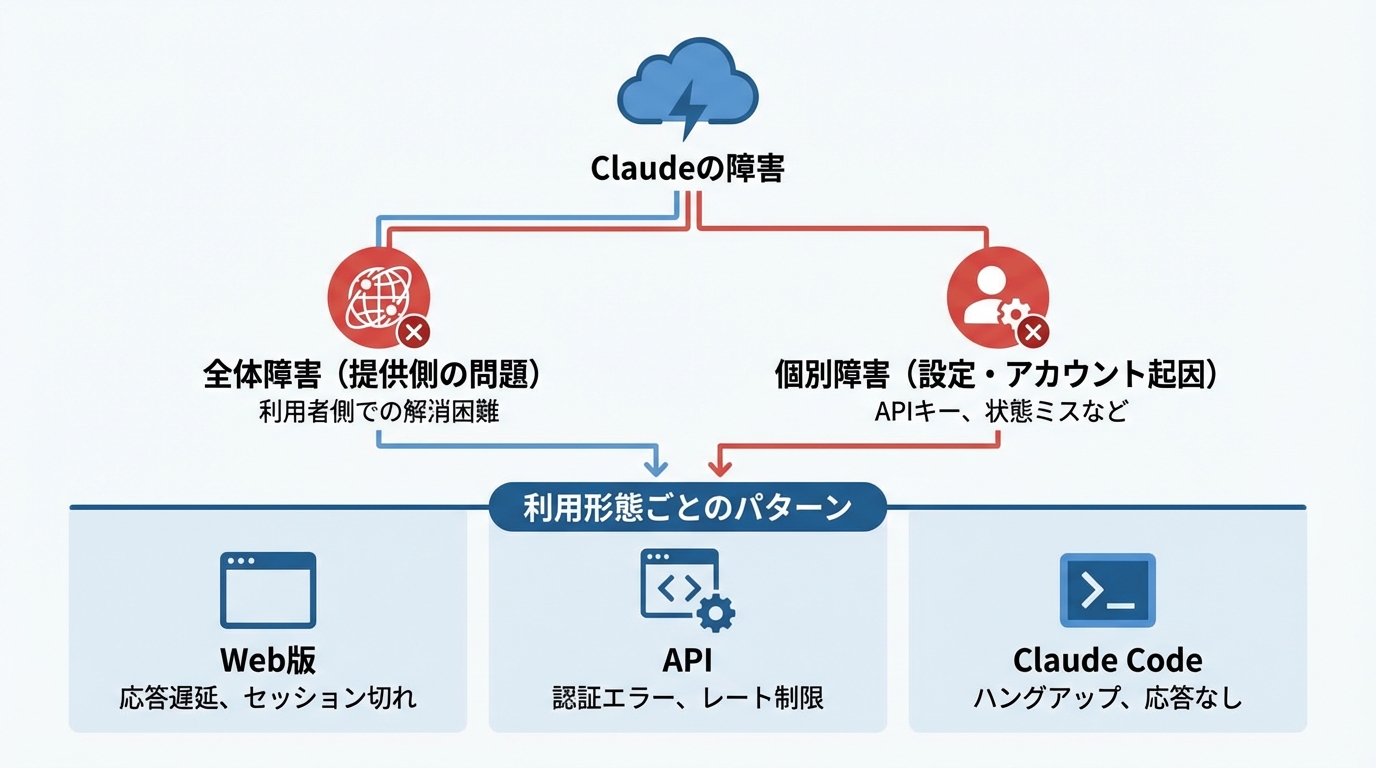
Claudeで発生する障害の種類と影響範囲
Claudeの障害は大きく分けて、サービス全体に波及するものと、個別のアカウントや環境だけに影響するものがあります。全体障害の場合は提供側の問題であることが多く、利用者自身で解消することは難しいことがあります。一方、個別の障害はAPIキーの設定ミスやアカウントの状態に起因するケースが多く、対処法が異なります。
たとえば、Claude Pro/Maxの有効なサブスクリプションを持つユーザーがClaude Code CLIで「This organization has been disabled」エラーを受け取る事例が報告されています。このケースではclaude.aiのWeb版では問題なく動作しており、影響範囲がCLIに限定されていました(参照*1)。このように、同じアカウントでも利用する手段によって障害の現れ方が異なる点を把握しておくと、原因の絞り込みが早くなります。
Web版・API・Claude Codeそれぞれの障害パターン
利用形態ごとに、Claudeで遭遇する障害のパターンには違いがあります。Web版のclaude.aiでは、ブラウザのセッション切れやサーバー側の一時的な負荷増大による応答遅延が主な問題になります。API経由では、認証エラーやレート制限によるリクエスト拒否が典型的です。
Claude Codeでは特有の障害パターンも確認されています。Explore Taskサブエージェントを生成した後、ツール呼び出しを完了したにもかかわらずサブエージェントが停止し、スピナーが回り続けたままLLMの応答が届かないという現象が報告されています。この状態ではタイムアウトやエラーの表示がなく、セッションが永遠にハングする形になります(参照*2)。利用形態ごとに障害の表れ方が異なるため、自分がどの経路でClaudeを使っているかを意識して状況を確認することが出発点になります。
障害発生時の原因確認と状況把握の手順
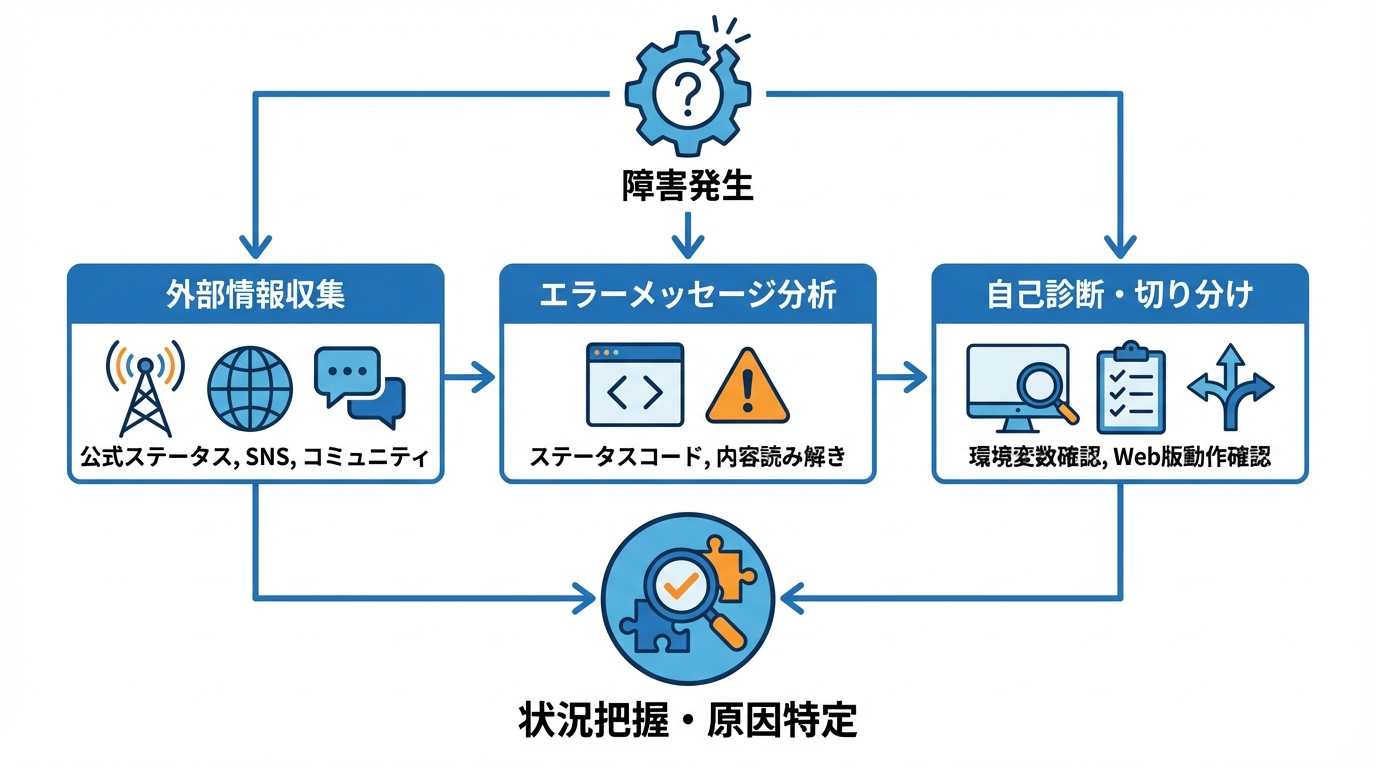
公式ステータスページとSNSでの情報収集
Claudeで障害が疑われる場合、最初に確認すべきはAnthropicの公式ステータスページです。ここにはサービスごとの稼働状況がリアルタイムで表示されるため、全体障害なのか自分の環境固有の問題なのかを素早く判断できます。併せてX(旧Twitter)などのSNSで同様の報告が出ていないかを確かめると、障害の規模感を把握する材料になります。
実際に「This organization has been disabled」エラーに遭遇したユーザーは、メールサポート、Account Ban Appealフォーム、claude.aiのAIチャットサポートと複数の窓口に問い合わせを試みたものの、返答を受けられなかったと報告しています(参照*3)。公式チャネルの応答に時間がかかる場合もあるため、コミュニティフォーラムやGitHubのIssueページも情報源として活用し、同じ症状を報告している他のユーザーがいないかを並行して確認します。
エラーメッセージの読み解き方と原因の切り分け
エラーメッセージは障害の原因を特定する最も直接的な手がかりです。Claudeが返すエラーには、APIのHTTPステータスコードとともに具体的な説明文が含まれることが多く、その内容を正確に読み取ることが重要になります。
代表的な例として、ANTHROPIC_API_KEY環境変数が設定されている場合、特に以前に無効化された組織のキーが残っていると、ユーザーの有効なMax/Proサブスクリプション認証を上書きしてしまう問題があります。この状態ではClaude Codeがアクティブなサブスクリプションではなく、無効化されたAPIキーで認証を試みるため、「API Error: 400 This organization has been disabled」が返されます(参照*1)。
エラーメッセージを確認する際は、まずステータスコード(400番台は利用者側の問題、500番台はサーバー側の問題)を確認し、次に説明文のキーワードから認証系なのか、制限系なのか、インフラ系なのかを切り分けます。この手順を踏むことで、対処法の方向性が定まります。
自分の環境起因か全体障害かを判断するチェックリスト
障害に遭遇したとき、問題が自分の環境にあるのかClaude全体の障害なのかを見極めるための確認項目を整理しておくと、無駄な待ち時間を減らせます。以下の順に確認を進めます。
- 公式ステータスページに障害情報が出ていないかを確認する
- claude.aiのWeb版に直接アクセスして、同じアカウントで正常に動作するかを試す
- 環境変数ANTHROPIC_API_KEYに古い、または無効なキーがセットされていないかを確認する
- ブラウザの拡張機能やネイティブメッセージングホストの状態を確認する
実際にClaude Codeの/chromeコマンドでStatusがDisabledと表示され、Reconnect extensionを選択してもChromeが一瞬開いてすぐ閉じ、Enabledに切り替わらないという事例も報告されています(参照*4)。このような手元の環境固有の問題を先に排除してから、全体障害の可能性を検討する流れが効率的です。
よくあるエラーと具体的な対処法
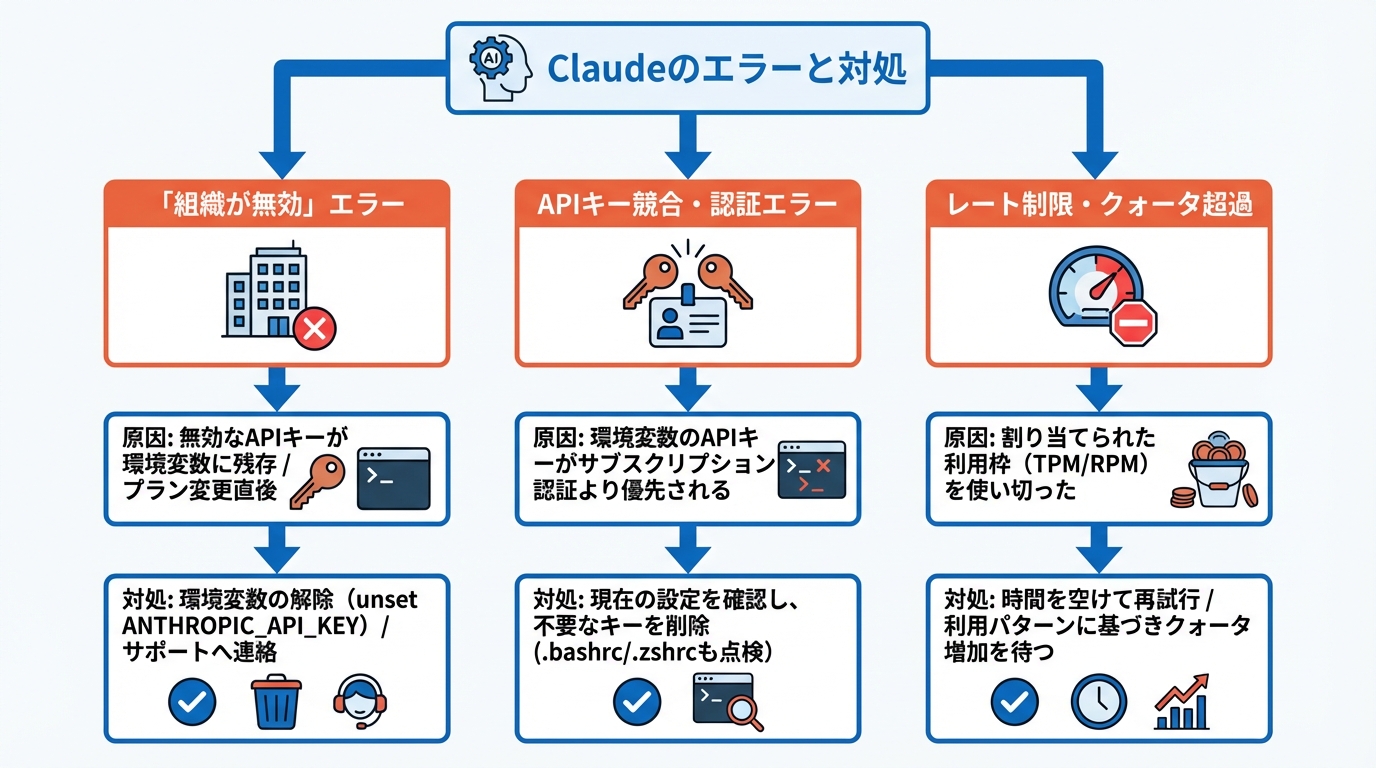
「This organization has been disabled」エラーへの対応
「This organization has been disabled」はClaude利用者が遭遇する代表的なエラーの1つです。このエラーが表示されても、必ずしもアカウントが停止されたわけではなく、認証経路の競合が原因であるケースがあります。
具体的な再現手順と解消法が報告されています。無効化された組織のAPIキーが環境変数に残った状態でclaude –printコマンドを実行すると「API Error: 400 This organization has been disabled」が返されます。一方、unset ANTHROPIC_API_KEYでAPIキーの環境変数を解除してからMaxサブスクリプションの認証で同じコマンドを実行すると、正常に動作します(参照*1)。
また、プラン変更のタイミングで同じエラーが発生するケースもあります。Claude Code Max 20xプランに加入後、ニーズに合わないと感じてMax 5xプランへダウングレードしたユーザーが、プラン更新タイミングで支払いを行った直後にClaude CodeとClaude.aiの両方へアクセスできなくなったと報告しています(参照*3)。プラン変更直後にこのエラーが出た場合は、環境変数の確認に加えてサポートへの連絡も視野に入れます。
APIキー競合・認証エラーの解消手順
APIキーの競合は、Claudeの障害と誤認されやすい典型的なトラブルです。特にClaude Codeを利用している場合、環境変数に設定されたAPIキーがサブスクリプション認証より優先されるため、意図しない認証経路で接続してしまうことがあります。
ANTHROPIC_API_KEY環境変数が設定されているとき、それがユーザーの有効なMax/Proサブスクリプション認証を上書きする仕組みになっています。以前に無効化された組織のキーが残っている場合、Claude Codeはアクティブなサブスクリプションの代わりに無効化されたAPIキーで認証を試みます(参照*1)。
対処手順としては、まずターミナルでecho $ANTHROPIC_API_KEYを実行して現在の設定値を確認します。不要なキーが見つかった場合はunsetコマンドで削除し、シェルの設定ファイル(.bashrcや.zshrcなど)にも古いexport文が残っていないかを点検します。複数のAPIキーを用途別に使い分けている場合は、プロジェクトごとに.envファイルで管理し、グローバルな環境変数との競合を防ぐ運用に切り替えます。
レート制限・クォータ超過による利用停止への対策
Claudeを高頻度で利用していると、レート制限やクォータの超過によりリクエストが拒否されることがあります。この状態はサービス障害ではなく、割り当てられた利用枠を使い切ったことが原因です。
各組織にはアカウント履歴と利用パターンに基づいてデフォルトのクォータが割り当てられます。クォータはtokens per minute(TPM)およびrequests per minute(RPM)で測定されます。Claude Sonnet 4.5やClaude Haiku 4.5の場合、クォータは通常慎重なレベルから開始され、実際の需要と利用パターンに基づいて増加できる仕組みです(参照*5)。
レート制限に頻繁に引っかかる場合は、リクエストの頻度を分散させるか、利用量の増加が見込まれる時点で事前にクォータの引き上げを申請する対応が求められます。申請にあたっては、現在のTPM・RPMの実績値を把握しておくとスムーズです。
障害中の代替手段と復旧後の確認ポイント
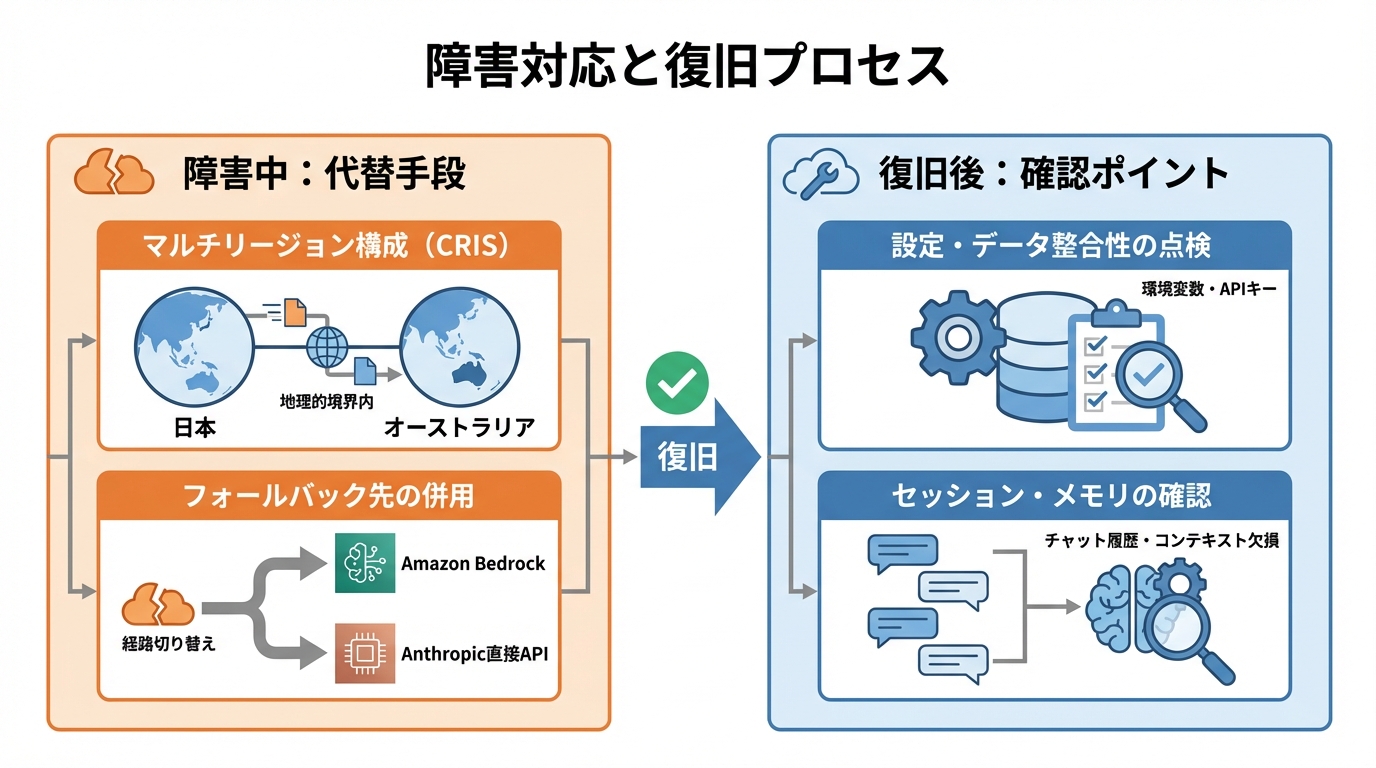
Amazon Bedrockなどマルチリージョン構成による可用性確保
Claudeに障害が発生した際の影響を最小限にとどめるには、単一の接続経路に依存しない構成が有効です。Amazon Bedrockのクロスリージョン推論(CRIS)を活用すると、特定のリージョンに障害が発生した場合でも、地理的境界内の別リージョンで処理を継続できます。
CRISを使用すると、ローカルな地理的領域内でClaude Sonnet 4.5またはClaude Haiku 4.5に呼び出しを行えます。推論要求は地理的境界内で処理され、全推論要求のライフサイクルを通じて日本またはオーストラリアを経由する仕組みになっています(参照*5)。
マルチリージョン構成を導入する場合は、データの所在地に関する法的要件や社内規定との整合性を事前に確認しておく必要があります。Anthropicの直接APIとAmazon Bedrock経由の両方をフォールバック先として併用する設計も選択肢の1つです。障害時にどの経路へ切り替えるかを事前に決めておくことで、復旧までの空白時間を短縮できます。
復旧後に確認すべき設定とデータ整合性
障害が解消された後は、設定値やデータの整合性を点検することがポイントです。特にClaude Codeのようなツールでは、セッションが中断された場合に同じパターンの障害が再発することがあります。
ハング状態のセッションをCtrl+Cで中断した後にセッションを再開しても、新しいExplore Taskが生成されたものの再び0ツール呼び出しで停止する、という再発事例が報告されています(参照*2)。復旧後は、環境変数やAPIキーの設定が障害前と変わっていないか、チャット履歴やメモリの状態に欠損がないかを確認します。Claudeはチャット履歴に基づくメモリを生成する機能を持っているため、障害によってコンテキストが失われた場合は、必要に応じてメモリの内容を見直すことも検討します(参照*6)。
障害に備えるためのベストプラクティスと注意点
タイムアウト・リトライ設計の重要性
Claudeを利用するアプリケーションやツールでは、タイムアウトとリトライの設計が障害時の挙動を左右します。これらの設定が不十分だと、障害が発生した際にセッションが無反応のまま長時間止まり続ける事態に陥ります。
実際に報告されている問題として、設定スキーマ上ではデフォルトのタイムアウト値が300000ms(5分)と記載されているものの、.optional()で定義されており.default()呼び出しがないため、設定正規化時にデフォルトが適用されないケースがあります。省略時にはtimeoutの値がundefinedとなり、タイムアウトのガード処理が完全にスキップされます(参照*2)。
リトライの設計にも注意が必要です。セッションレベルのリトライ処理では、上限なしでattemptがインクリメントされ、retryable()がメッセージを返す限りバックオフを伴って無限にループする実装も確認されています。バックオフは基底2秒、係数2倍、試行ごとに最大30秒となっています(参照*2)。自前のアプリケーションにClaudeを組み込む場合は、タイムアウト値を明示的に設定し、リトライ回数に上限を設けることで、障害時の無限ループを防ぎます。
クォータ監視と事前申請による予防策
レート制限やクォータ超過による突然の利用停止を防ぐには、日常的な監視と計画的な枠の確保が欠かせません。障害が起きてから対処するのではなく、利用量の傾向を把握しておくことが予防の基本です。
AWSはリアルタイムでクォータの利用状況を追跡するCloudWatch指標を提供しており、利用が定義済みの閾値に近づいた際にアラートを設定できます(参照*5)。クォータの使用状況を監視することでクォータ制限の発生を抑え、リソース配分の最適化にもつなげられます。
需要の増加が見込まれる場合は、事前にクォータの引き上げを申請しておきます。各組織にはアカウント履歴と利用パターンに基づいてデフォルトのクォータが割り当てられ、実際の需要に基づいて増加申請が可能です(参照*5)。閾値アラートの設定と定期的な利用実績の確認を運用フローに組み込むことで、クォータ起因の障害リスクを下げることができます。
おわりに
Claudeの障害は、サービス全体のインフラ問題から環境変数の設定ミスまで、原因の幅が広い点が特徴です。障害に遭遇した際は、まずステータスページとエラーメッセージで状況を把握し、自分の環境固有の問題を先に排除する手順が復旧への近道になります。
日頃からタイムアウト・リトライの設計を見直し、クォータの監視体制を整え、マルチリージョン構成やフォールバック経路を準備しておくことで、障害発生時の影響を抑えられます。この記事で取り上げた具体的なエラー事例と対処法を、自身の運用環境に照らし合わせて活用してみてください。
監修者
安達裕哉(あだち ゆうや)
デロイト トーマツ コンサルティングにて品質マネジメント、人事などの分野でコンサルティングに従事しその後、監査法人トーマツの中小企業向けコンサルティング部門の立ち上げに参画。大阪支社長、東京支社長を歴任したのち2013年5月にwebマーケティング、コンテンツ制作を行う「ティネクト株式会社」を設立。ビジネスメディア「Books&Apps」を運営。
2023年7月に生成AIコンサルティング、およびAIメディア運営を行う「ワークワンダース株式会社」を設立。ICJ2号ファンドによる調達を実施(1.3億円)。
著書「頭のいい人が話す前に考えていること」 が、82万部(2025年3月時点)を売り上げる。
(“2023年・2024年上半期に日本で一番売れたビジネス書”(トーハン調べ/日販調べ))
参照
- (*1) GitHub – [Bug/Documentation] 'Organization has been disabled' error when ANTHROPIC_API_KEY overrides Max/Pro subscription · Issue #8327 · anthropics/claude-code
- (*2) GitHub – Explore subagent hangs indefinitely with Anthropic Claude Opus 4.6 — no timeout or recovery · Issue #13841 · anomalyco/opencode
- (*3) GitHub – Claude Account Disabled After Payment for Claude Code Max 5x Plan · Issue #5088 · anthropics/claude-code
- (*4) GitHub – Native Messaging Host not installing (Windows) · Issue #15336 · anthropics/claude-code · GitHub
- (*5) Amazon Web Services – Introducing Amazon Bedrock cross-Region inference for Claude Sonnet 4.5 and Haiku 4.5 in Japan and Australia
- (*6) Use Claude’s chat search and memory to build on previous context
