はじめに
ChatGPTやGeminiなどの大規模言語モデル(LLM)が、消費者が情報を得る入口として急速に普及している。米国の小売サイトへのLLM経由トラフィックは2024年半ばから2025年半ばにかけて3,500%増加し、消費者の80%が検索の少なくとも40%でAI生成の要約を活用しているというデータもある(参照*1)。私自身、Perplexityを日常的な検索代替として使い始めて以来、従来のGoogle検索との情報到達ルートの違いをはっきり実感している。こうした環境の変化に対応しなければ、自社のブランドや商品がAIの回答に一切登場せず、見込み顧客の目に触れない状態が生まれかねない。
その対策として注目されているのが「LLMO(Large Language Model Optimization)」だ。LLMOとは、AIが生成する回答の中で自社ブランドが言及・引用・推薦されるよう、コンテンツやウェブサイト、ブランドの存在感を最適化する取り組みを指す。この記事では、LLMOの定義から仕組み、SEOとの違い、具体的な最適化手法、導入メリット、そして効果測定の方法まで順を追って解説する。
LLMOの定義と背景
LLMOの基本的な意味
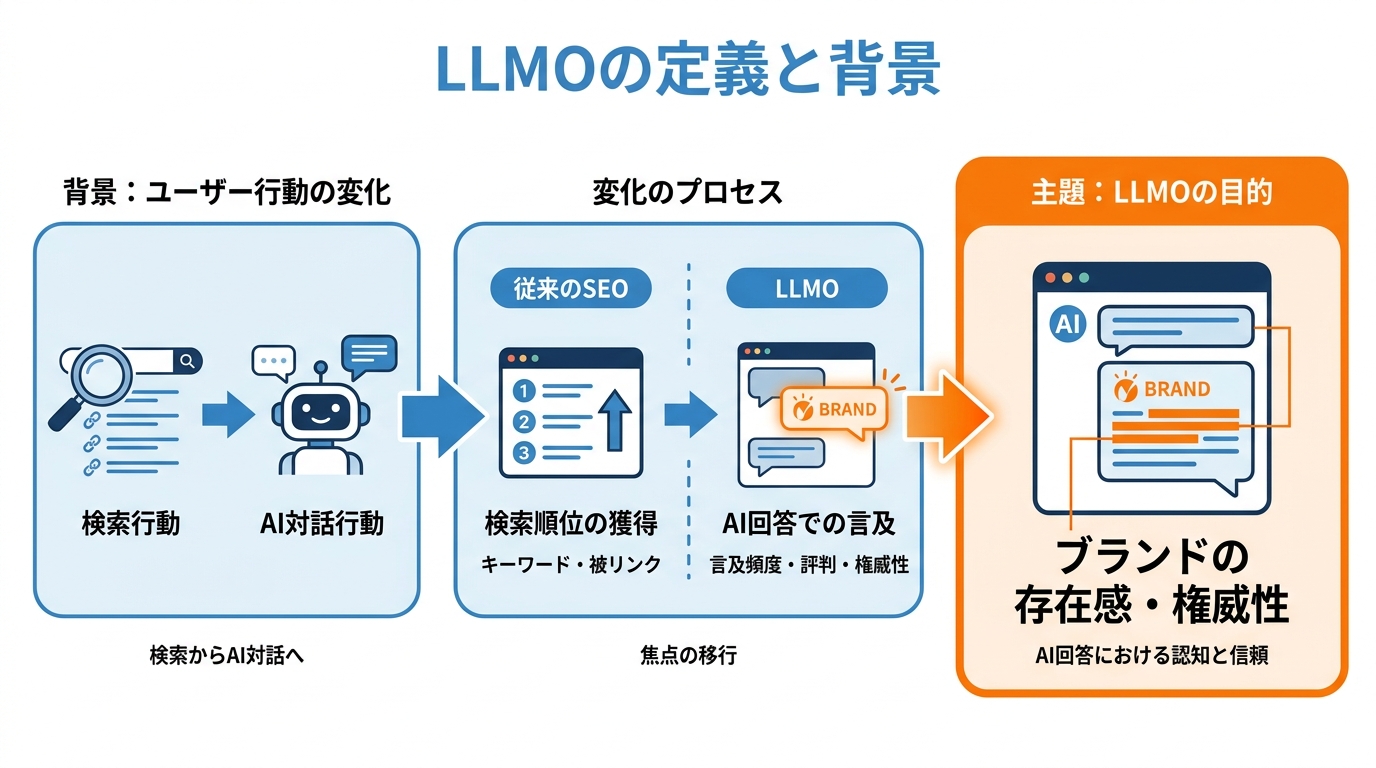
LLMOとは「Large Language Model Optimization」の略で、ChatGPT Search、GoogleのAI Overviews、PerplexityなどのAIツールが生成する回答の中に、自社のコンテンツやブランドが表示されるよう最適化する取り組みだ。従来のSEOが検索結果ページでの「順位」を目指すのに対し、LLMOの目的はAIの会話型回答の中でブランドが言及され、引用され、推薦されることにある(参照*2)。
LLMOが重視するのは、購買プロセス全体を通じたブランドの認知度・信頼・権威性の向上だ。ユーザーがウェブサイトにクリックして訪問しない場合でも、AIの回答にブランド名が登場すれば認知の接点が生まれる。つまり、LLMOとは「検索順位の獲得」ではなく「AIの回答におけるブランドの存在感」を高める施策だといえる。
ユーザーの情報収集行動そのものが変化していることが、LLMOが注目される背景だ。検索エンジンでリンク一覧を確認する従来型の行動から、AIアシスタントに質問して要約された回答を受け取る行動へと移行が進んでいる。LLMOはこの変化に対応するための考え方であり、私が運営するメディアでもAI経由の参照トラフィックが無視できない規模になってきている。
AI検索の台頭と従来SEOの限界
AI駆動の検索やアシスタントの利用は急速に広がっています。2024年半ばから2025年初頭にかけて、生成AIからのトラフィックが1,200%増加したという計測データがあります(参照*3)。LLMを活用した会話型のインターフェースが、情報・商品・サービスを探す消費者にとっての主要な入口になりつつあるのです。
この変化によって、従来のSEOだけでは対応しきれない課題が浮き彫りになっている。Googleの検索結果で1位に表示されていても、ChatGPTの回答にまったく登場しないケースがあり、その逆も起こり得る(参照*4)。検索結果の順位とAIの回答で言及されるかどうかは、評価される仕組みが根本的に異なるからだ。私自身、ChatGPTやPerplexityに同じ質問を投げて、どの情報源が引用されているかを確認する作業を定期的に行っている。その結果、SEOで上位表示されているコンテンツと、AIに引用されるコンテンツとは、かなりの頻度でズレがあると感じている。
従来のSEOがキーワードと被リンクに焦点を当てるのに対し、LLMOはブランドの言及頻度、評判、そしてLLMが学習に使う多様な情報源での権威性に焦点を当てる。AI検索の台頭が続く限り、LLMOの考え方を取り入れなければ、見込み顧客との接点を逃すリスクは高まる一方だ。
LLMOの仕組み
LLMが情報を選ぶプロセス
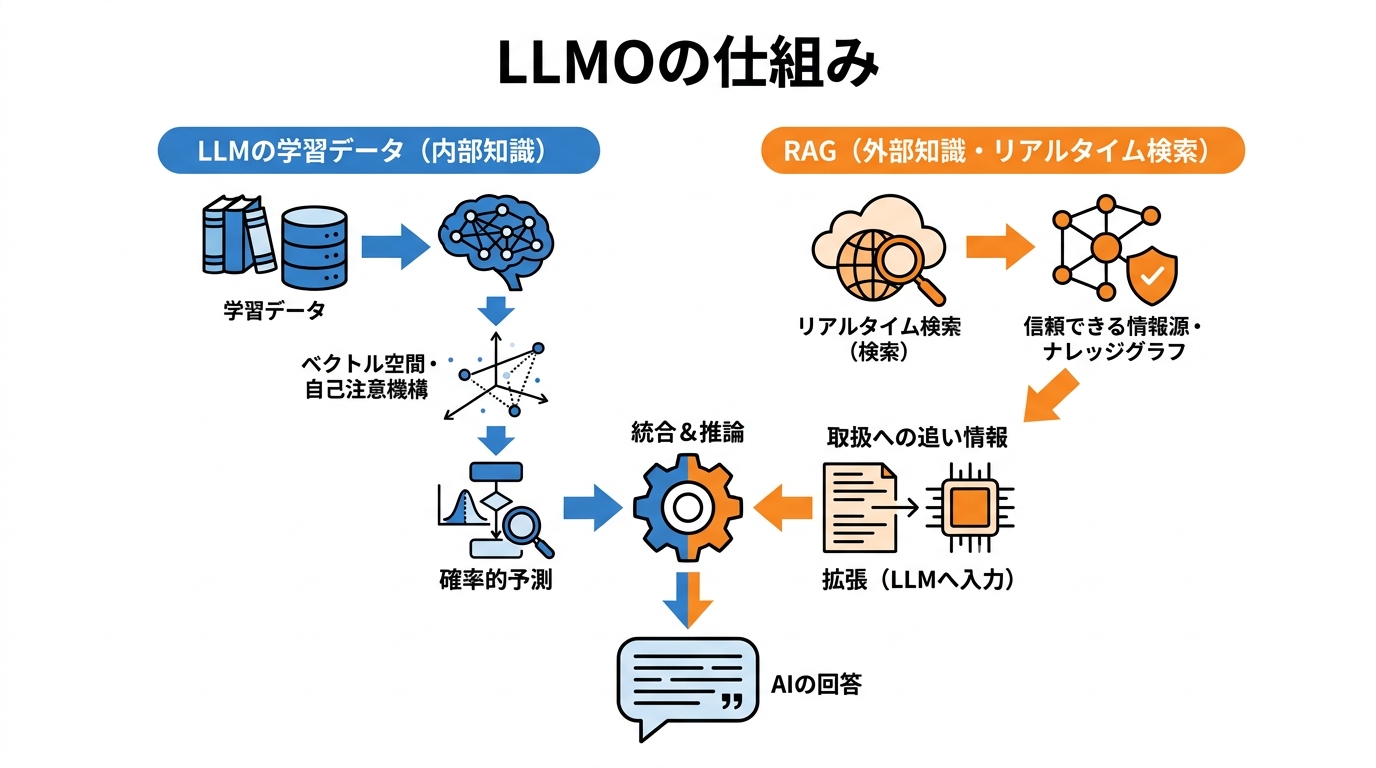
大規模言語モデルは、言語を複数の段階で処理する仕組みを持っています。入力されたテキストはまず「トークン」と呼ばれる最小単位に分割されます。次に、各トークンが意味を表す数値の並び(ベクトル)に変換されます。その後、変換器型のモデル構造(Transformer)が「自己注意機構」を使い、どの入力が回答にとって最も重要かを判断します(参照*5)。
この処理は確率的な予測に基づいており、モデルは膨大な学習データの中で頻繁に、かつ信頼性の高い文脈で登場していた情報を優先的に出力する傾向がある。そのため、LLMOではLLMの学習データに含まれる可能性が高い情報源、たとえば権威あるメディアや専門性の高いサイトに自社の情報を掲載しておくことが重要になる。逆に言えば、自社サイトだけに閉じて情報を発信しても、LLMには「存在しない」に等しい状態になりかねない。
つまり、LLMが回答を生成する際の「情報の選別」は、検索エンジンのリンク評価とは異なる仕組みで行われている。ベクトル空間での意味の近さや、学習時にどの情報源が重み付けされていたかが、回答に含まれるかどうかを左右する。SEOのように「クローラーに正しく読ませる」だけでは不十分で、LLMが学ぶに値する情報として扱われるかどうかが問われる。
RAGによるリアルタイム検索と生成
一部のAIシステムは「RAG(Retrieval-Augmented Generation/検索拡張生成)」と呼ばれる仕組みを組み合わせて回答を生成しています。RAGには2つのステップがあります。まず「検索」のステップでは、ユーザーの質問に基づいて外部のデータベースやナレッジグラフ(事実と概念をつなぐネットワーク)、精選された情報源から関連する情報を取得します。次に「拡張」のステップで、取得した情報をLLMに入力し、より正確で文脈に合った回答を生成させます(参照*3)。
具体的な流れとしては、生成エンジンがまず検索エンジンのインデックスに対して複数のリクエストを送り、関連性・信頼性・正確性が高いウェブページを取得します。取得されたページ群がAIの一時的な参照資料となり、生成エンジンがそれらを読み込み、推論・統合して最終的な回答を作成し、根拠としての引用を付与します(参照*6)。
RAGの仕組みを踏まえると、LLMOでは「学習データに含まれること」だけでなく「リアルタイムの検索で取得されること」も同時に意識する必要がある。検索エンジンのインデックスに正しくクロールされ、信頼できる情報源として評価されていることが、AIの回答に引用される前提条件となる。ここで重要なのは、RAGによるリアルタイム検索の対象になるには、結局のところ従来のSEO的な技術基盤も無視できないという点だ。LLMOとSEOは対立する概念ではなく、土台の上に積み上げる構造になっている。
SEOとLLMOの違い
目的・評価指標の比較
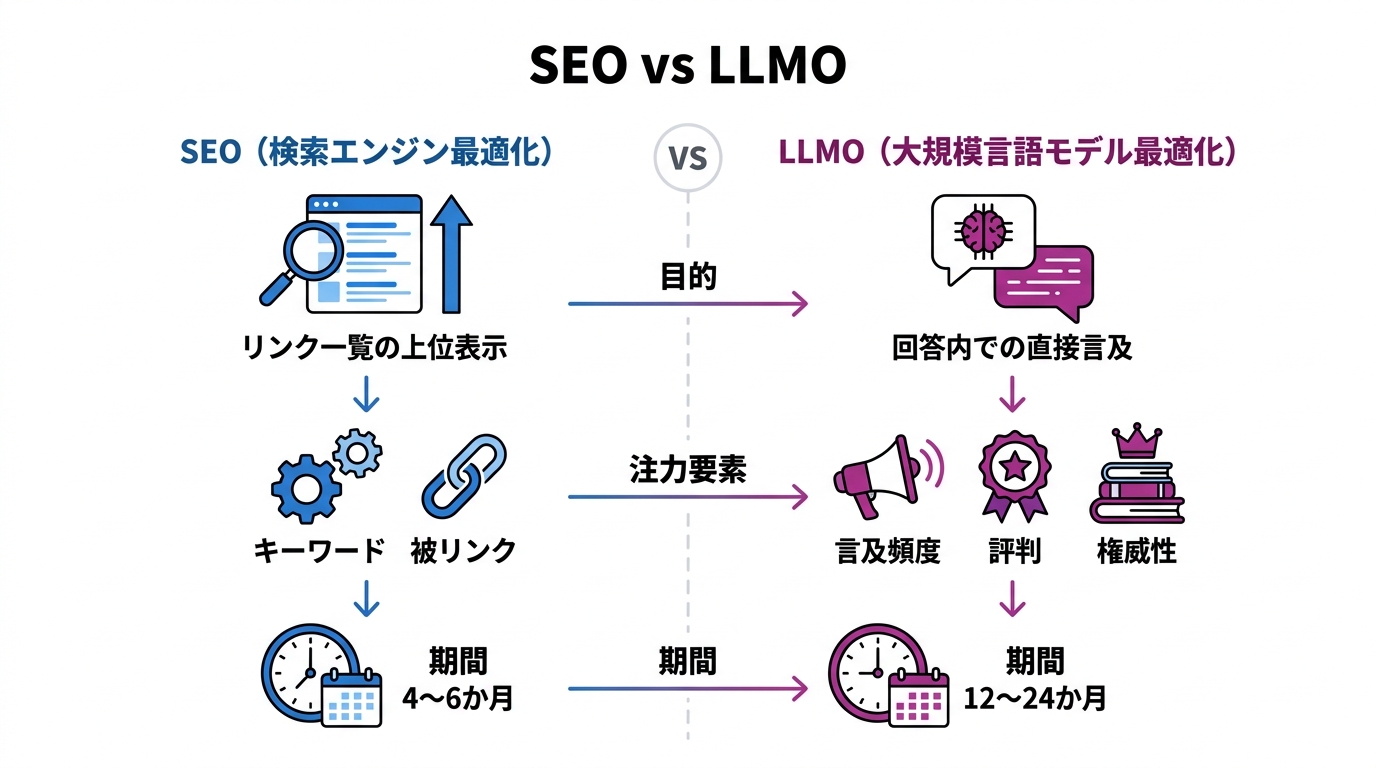
SEOとLLMOは、目的も評価の対象も大きく異なる。SEOはGoogleの順位付けアルゴリズムに最適化して、10件のリンク一覧に表示されることを目指す。一方、LLMOはLLMの推薦アルゴリズムに最適化して、会話型の回答の中で直接ブランド名が挙げられることを目指す(参照*4)。
注力する要素にも違いがある。SEOがキーワードと被リンクに焦点を当てるのに対し、LLMOはブランドの言及頻度、評判、そしてLLMが学習する情報源全体での権威性を重視する。効果が現れるまでの期間も異なり、SEOは4〜6か月が目安であるのに対し、LLMOは12〜24か月という長い期間が想定されている(参照*7)。この期間の長さは、取り組みの優先順位を下げる理由にはならない。むしろ早く始めた企業ほど、蓄積量で差をつけやすい領域だと考えている。
この期間の差は、LLMが新しい情報を取り込んで処理し、回答に反映するまでに時間がかかることに起因します。Googleの検索結果で1位であってもChatGPTに言及されないことがあるため、SEOとLLMOは補完関係として捉え、両方に取り組む姿勢が求められます。
GEO・AEOとの関係整理
LLMO以外にも、AI時代の最適化を指す用語がいくつか存在します。GEO(Generative Engine Optimization)はAI生成の要約での表示を目指す取り組みで、ウェブコンテンツ・ソーシャルシグナル・サイトのクロール可能性を重視し、効果の目安は6〜12か月です。AEO(Answer Engine Optimization)はAI回答エンジンに表示されることを目標とし、構造化データ・権威あるコンテンツ・引用が焦点で、同じく6〜12か月の期間が見込まれます(参照*7)。
LLMOは、LLMの内部メカニズムであるベクトル埋め込みや意味の明確さ、LLMが学習に使う権威ある情報源での掲載に焦点を当てるという特徴を持ちます(参照*8)。GEOやAEOがリアルタイムの検索結果やAI要約への表示を中心にするのに対し、LLMOはモデルの学習段階から回答生成の段階までを広くカバーする概念だといえます。
これらの用語は重なる部分も多いため、厳密に分離するよりも、それぞれが何に焦点を置いているかを理解した上で、自社のコンテンツ戦略に必要な施策を選択することが実務上は有効だ。用語の定義に時間をかけるより、「今AIに質問したとき、自社は登場しているか」を確認する作業のほうが先決である。
LLMOの5つの柱と最適化手法
情報ゲインとオリジナルコンテンツ
LLMOにおいて、独自のデータや統計を含むコンテンツは大きな強みになる。LLMは権威あるコンテンツや専門的な知見の発信(thought leadership)を好む傾向があり、独自データや統計を持っている場合はさらに優位に立てる(参照*9)。私自身、会社設立以来15年近く、広告やPRに頼れない状況で1次情報を発信し続けてきた。最初はブログを毎日更新するという非効率なやり方だったが、無名で資金も乏しい状態では、自分たちが見聞きしたこと・試したこと・考えたことを出す以外に手段がなかった。その経験から言えば、1次情報の発信は資金が少ない会社でも始められる、インパクトの大きい施策だ。
実際に、引用・統計・信頼性の高いデータソースへのリンクを含むコンテンツは、最適化されていないコンテンツと比較してLLMに言及される頻度が30〜40%高かったという調査結果があります(参照*2)。
他サイトでは手に入らない一次情報や調査結果を発信することは、LLMにとっての「情報ゲイン」、つまり既存の情報に上乗せされる新しい価値となる。自社で蓄積したデータや顧客調査の結果を積極的にコンテンツ化することが、LLMOの基盤になる。顧客アンケート、やってみた記録、現場でよく受ける質問、社内に蓄積された判断基準——こうした素材は多くの企業がすでに持っている。重要なのは、それを型に当てはめて読者に伝わる形へ編集する仕組みを持てるかどうかだ。
エンティティ最適化とE-E-A-T
LLMOでは、ブランドや人物が「エンティティ(固有の存在)」としてLLMに正しく認識されることが欠かせません。LLMはメディア、Wikipedia、LinkedIn、さらにはRedditなど、信頼性の高い第三者サイトの情報を好む傾向があり、何らかの審査や編集を経た情報源を重視します(参照*9)。
RedditのコンテンツはGPTの学習データにおいて約22%を占め、2.9倍の重要度の重み付けがされていたとする分析があります。2024年7月にはGoogleがRedditのコンテンツをAI学習に使用する6,000万ドルの契約を結び、OpenAIも同様の契約を行いました(参照*7)。
これは、自社のウェブサイトだけでなく、第三者のプラットフォームにおいてもブランドに関する正確かつ好意的な情報が存在することの重要性を示している。E-E-A-T(経験・専門性・権威性・信頼性)の要素を自社サイト内だけでなく外部の情報源にも広げていくことが、LLMOの実践では欠かせない。業界メディアへの寄稿、LinkedInでの専門的な発信、コミュニティでの対話——こうした地道な積み上げが、LLMに「信頼できるブランド」と認識されるための土台になる。
構造化データとセマンティック設計
AIがコンテンツを正しく理解するためには、まずそのコンテンツを正確に解析できる必要があります。構造化データと整然としたセマンティックHTMLは、コンテンツにあいまいさのない構造を与え、ウェブページを完全に解析可能な状態にします。これはAIがコンテンツを理解・信頼する前に必ず通る、見落とされがちな第一歩です(参照*6)。
見出し構造も重要な要素だ。H1、H2、H3と順序立てた見出し構造を持つコンテンツは、ChatGPTに引用される頻度が約3倍に上がるという調査結果がある。さらに、ChatGPTが引用する記事の約80%にはリスト形式のセクションが含まれているのに対し、Googleの上位表示ページでリストを含むのは28.6%にとどまる(参照*2)。ここは人間の読者向けの設計とAI向けの設計が一致する部分で、見出しで論点を分け、箇条書きで整理するという基本が、そのままLLMOにも効く。
加えて、文章の流暢さや読みやすさを改善するだけでも、最適化されていないコンテンツと比較して15〜30%の可視性向上が確認されたとする研究もあります(参照*2)。構造と読みやすさの両方を整えることが、LLMOの技術面での柱となります。
第三者引用と権威性の構築
LLMOでは、自社で発信するコンテンツの質に加え、外部からの言及や引用がブランドの権威性を支えます。LLMが好むのは、メディア、Wikipedia、LinkedIn、Redditといった、何らかの編集プロセスや審査を経た第三者サイトの情報です(参照*9)。
LLMOの効果が現れるまでの期間は12〜24か月と見込まれており、その施策範囲にはウェブサイトのコンテンツだけでなく、アーンドメディア(報道やレビューなど自然に獲得するメディア露出)やRedditでの存在感も含まれます(参照*7)。
自社サイトの中だけで完結するのではなく、業界メディアへの寄稿、専門家としてのLinkedInでの発信、ユーザーコミュニティでの対話など、複数の信頼ある場所でブランドの情報を積み上げていくことが、LLMの回答に選ばれるための土台となる。プラットフォームは中立ではない。どこに情報を置くかで、LLMに読まれる可能性が変わる。配信面の設計を意識することは、LLMOにおいても重要な視点だ。
導入メリットと注意点
LLMO導入で得られるメリット
LLMOに取り組むことで、AI回答における自社ブランドの可視性が高まります。最適化されたコンテンツは、ChatGPTやGeminiがユーザーに回答する際に引用・参照される可能性が高くなります。ユーザーがAIアシスタントに質問する会話型検索が増えるなか、LLMOはこうした新しいチャネルでブランドの存在感を維持する手段となります(参照*10)。
さらに、LLMOに早期から取り組むことで、AIが情報発見の主要チャネルとなる環境において競合に先んじることができる。AIがツールを3つ推薦した場合、その3つには大幅なトラフィック増加が見られる一方で、推薦されなかったツールはほぼ認知されないという状況が生じ得る(参照*11)。私がコンサルティングの現場で見ていても、AIに「〇〇のおすすめツールは?」と聞いたときに登場するブランドと登場しないブランドとでは、その後の商談数に明確な差が出始めている。
AIの回答に登場するかどうかが、見込み顧客に認知されるかどうかを分ける時代において、LLMOへの早期着手は実質的な競争優位につながります。
よくある失敗と回避策
LLMOに取り組む企業がまず陥りやすいのが、即座のトラフィック増加を期待してしまうことだ。しかし、多くのAIモデルは新しい情報を取得してから処理・反映するまでに数か月単位の時間がかかる。LLMOは年単位の取り組みとして捉える必要があり、一貫性と忍耐が成果を出す上で欠かせない(参照*12)。短期的なトラフィック指標しか見ていない組織では、LLMOの評価が難しい。だからこそ、測定の設計を最初から決めておくことが重要になる。
もう1つのよくある失敗は、従来のSEO手法を捨ててLLMOに全面移行してしまうことです。この極端な方針変更は、かえってオンラインでの可視性を損なう恐れがあります。キーワードの適切な使用、質の高い被リンク、良好なユーザー体験といったSEOの基本要素は、AIモデルがコンテンツを解釈し引用する際にも依然として影響を与えます(参照*12)。
LLMOとSEOは二者択一ではなく、並行して取り組むべき施策だ。SEOの基盤を維持しながら、LLMOで求められる独自コンテンツの発信やエンティティの整備、構造化データの導入を段階的に加えていく進め方が、失敗を防ぐ現実的な方法である。従来のSEOはそのまま継続しつつ、発信する情報の質を1次情報中心に切り替えていく——この順序が、現場での定着を考えると最も現実的だと私は考えている。
活用事例とデータ
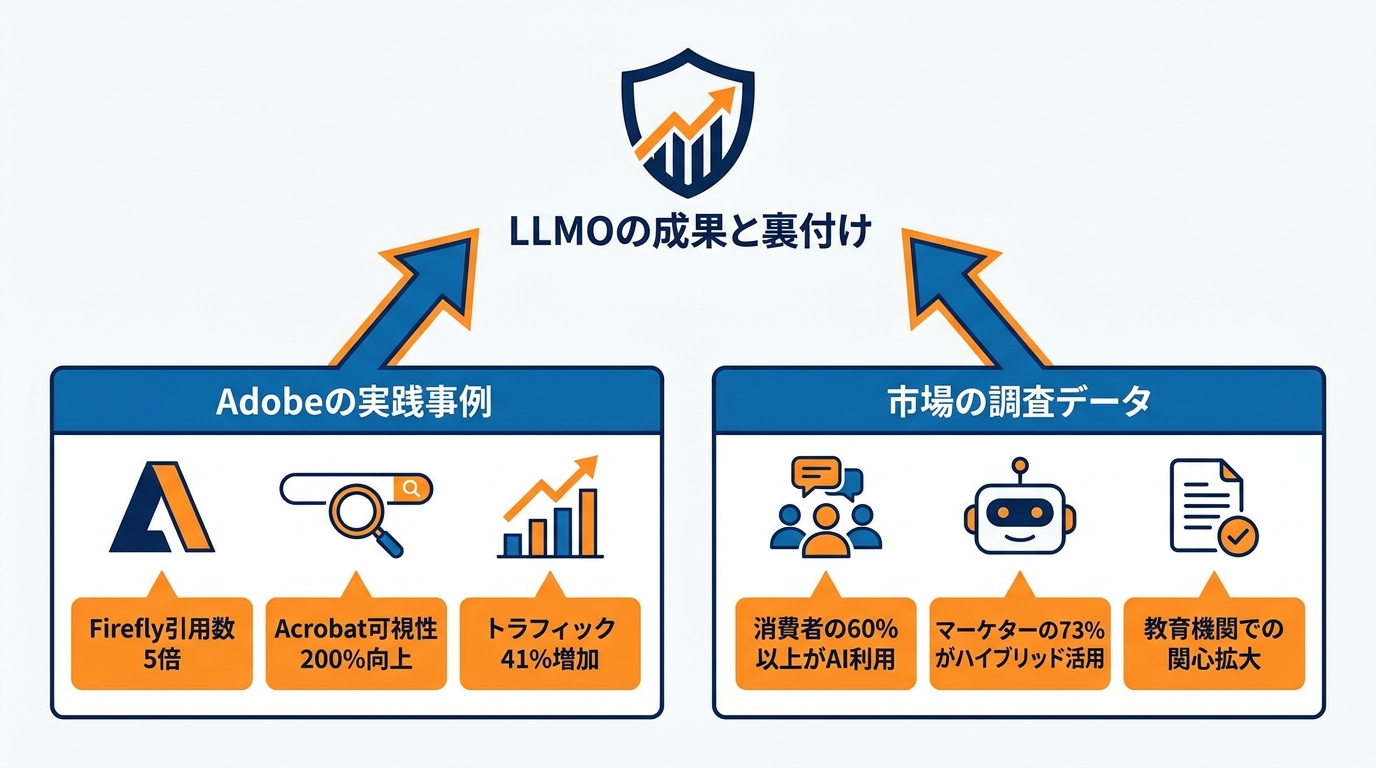
Adobeの可視性向上事例
LLMOの実践事例として、Adobeの取り組みが具体的な数値とともに公表されています。Adobeは自社をLLM発見可能性の最初のテスト対象とし、Adobe FireflyとAdobe Acrobatのランディングページに新しいソリューションを適用しました。その結果、1週間以内にFireflyのLLM回答での引用数が5倍に増加しました。さらにAcrobatのページではLLMでの可視性が200%向上し、LLMからの参照トラフィックが41%増加しました(参照*1)。
Adobeの事例は、LLMOの施策を適切に行えば比較的短期間で引用数や可視性に変化が現れることを示している。ただし、Adobeはもともとブランドの権威性や豊富なコンテンツ資産を持つ企業であり、どのような条件の企業でも同じスピードで成果が出るとは限らない。ここを誤解すると、「やったのに効果が出ない」という判断につながる。
自社のブランド力やコンテンツの蓄積量に応じて、効果が表れるまでの期間や規模は異なると考えるのが現実的です。Adobeの事例は、LLMOが実際にAI回答内の可視性を変える手段として機能し得ることを裏付ける一つの根拠です。
調査データが示す効果
LLMOの背景にある消費者行動の変化を示すデータも蓄積されつつあります。調査によると、消費者の60%以上が購入の意思決定の前にAIチャットボットを商品調査に利用しています(参照*11)。AIの推薦に入るかどうかが、購買行動に直接影響を及ぼしている状況です。
マーケティング担当者側の動向にも変化が見られます。マーケティング担当者の73%がAI生成コンテンツと人間の監修を組み合わせており、このハイブリッドなアプローチを採用している企業はトラフィックの緩やかな増加を経験しているという報告があります(参照*7)。
教育機関でもLLMOへの関心は高まっています。ウォートン・スクールのエグゼクティブ教育プログラムでは「AIとマーケティング」のカリキュラムにおいて、SEOからLLMOへの移行をセッションの一つに組み込んでいます(参照*13)。消費者行動、マーケティング実務、そしてビジネス教育の各領域でLLMOの存在感が拡大しています。
効果測定と主要KPI
LLMOの効果を測定するには、従来のSEO指標とは異なるKPIが必要だ。主要な指標として、AIプラットフォーム全体でのブランド言及頻度、AI回答における発言占有率(share of voice)、AI言及の文脈と感情のトーン、AIからの参照トラフィックとコンバージョン率、そしてトピック権威性の拡大状況の5つが挙げられている(参照*2)。いずれも単独で成果を断定する指標ではなく、複数の弱いシグナルを組み合わせて傾向を見るものだという理解が重要だ。
別の分類では、AI回答への掲載頻度、AI出力でのブランド名の言及数、引用された事実の正確さ、関連するプロンプト全体での文脈再現性、ソース表示があるプラットフォームでの引用とURL言及、AI経由のトラフィックと参照シグナルの6つが主要指標とされています(参照*5)。
実際の測定方法としては、関連するプロンプトをLLMに入力し、自社ブランドが言及されているか、推薦リストの何番目に表示されているか、どのような文脈で紹介されているか、どの競合が一緒に表示されているか、どの情報源が引用されているかを追跡する(参照*4)。まずはツールに頼らず、代表的なユーザープロンプトを20〜30本ほど手動で作り、ChatGPT・Perplexity・Gemini・Google AI Overviewなど複数のエンジンで月次確認するところから始めるのが現実的だ。数か月の観察を経てから、どこを自動化するかを判断すればよい。
おわりに
LLMOとは、AIが生成する回答の中で自社ブランドが言及・引用・推薦されることを目指す最適化の取り組みだ。従来のSEOとは異なるメカニズムで評価が行われるため、独自コンテンツの発信、構造化データの整備、第三者メディアでの権威性構築、そして年単位での継続が求められる。
LLMからの参照トラフィックが急増している現在、LLMOの施策を始めるかどうかが、今後のブランド認知と集客に大きな差を生む可能性がある。まずは自社に関連するプロンプトをAIに入力し、現状の可視性を把握するところから取り組んでほしい。測定できなければ改善もできない。手を動かすことが先決だ。
監修者
安達裕哉(あだち ゆうや)
デロイト トーマツ コンサルティングにて品質マネジメント、人事などの分野でコンサルティングに従事しその後、監査法人トーマツの中小企業向けコンサルティング部門の立ち上げに参画。大阪支社長、東京支社長を歴任したのち2013年5月にwebマーケティング、コンテンツ制作を行う「ティネクト株式会社」を設立。ビジネスメディア「Books&Apps」を運営。
2023年7月に生成AIコンサルティング、およびAIメディア運営を行う「ワークワンダース株式会社」を設立。ICJ2号ファンドによる調達を実施(1.3億円)。
著書「頭のいい人が話す前に考えていること」 が、82万部(2025年3月時点)を売り上げる。
(“2023年・2024年上半期に日本で一番売れたビジネス書”(トーハン調べ/日販調べ))
参照
- (*1) Adobe.com is “customer zero” for LLM discoverability
- (*2) Search Engine Land – What Is LLMO? Optimize Content for AI & Large Language Models
- (*3) LLMO Meaning: Boost your content’s AI visibility
- (*4) BrandViz – What is LLMO? LLM Optimization Explained
- (*5) Search Atlas – Advanced SEO Software – What is LLMO and How to Optimize LLMs for AI Answers?
- (*6) Beyond the 'Engine': Applying the Complete SEO Ontology to Master Search Experience and AI Search
- (*7) SEO and SEM Actionable Strategies for Generative AI Search in 2025
- (*8) Figment Agency – What is the difference between LLMO, GEO & AI Optimisation?
- (*9) Built In – Why LLMO Is Replacing SEO
- (*10) Arimetrics – Definition, Characteristics, Techniques, and Strategies
- (*11) Netpeak Journal — Best articles and case studies on marketing and business development – What Is LLM Optimization (LLMO) and How to Get Recommended in AI Product Comparisons
- (*12) LLMO: What Companies Get Wrong and How to Fix It
- (*13) News – Wharton Executive Education Launches AI in Marketing: Creating Customer Value in an AI-Driven Enterprise
