
はじめに
AIでアニメを作る手法が広がり、個人でも短編アニメーションを完成させられる環境が整いつつあります。私自身、生成AIを毎日のように業務へ使い、画像生成や動画生成のモデルを一通り触ってきましたが、映像領域の進化スピードは文章生成以上に速いと感じています。一方で、ツール選びや制作手順を誤ると、キャラクターの見た目がカットごとに変わったり、品質が安定しなかったりといった問題に直面します。
こうした失敗を避けるには、画像生成から動画変換、カット編集に至る基本フローを正しく押さえ、目的に合ったツールを選ぶことが欠かせません。ここで重要なのは、AIに任せる工程と人間が判断する工程を最初に切り分けておくことです。本記事では、AIでアニメを作るための全体像から具体的な手順、品質を高めるコツ、そして注意すべきリスクまでを順を追って解説します。
AIアニメ制作の全体像
従来アニメとAIアニメの違い
従来のアニメ制作では、熟練したアニメーターが1枚ずつ原画や動画を描き上げ、膨大な工数をかけて映像を仕上げます。AIでアニメを作る場合は、テキストや参照画像をもとにAIが静止画や動画を自動生成するため、絵を描くスキルがなくても映像制作に取り組めます。
ただし、AIがすべてを自動で仕上げるわけではありません。Anime GenSysは「熟練したアニメーターをより速く、より大きな影響力を持ち、疲弊させないための精密ツールを構築する」と掲げており、すべてのフレームの中心に人間の技術を置き続ける姿勢を示しています(参照*1)。AIでアニメを作るといっても、構図やストーリーの設計、仕上げの調整には人間の判断が不可欠であり、AIは制作の一部を加速させる道具として位置づけるのが現実的です。私は生成AIを「100%正解を出す装置」ではなく「候補を大量に生む装置」として扱うべきだと考えていますが、アニメ制作にも同じ発想が当てはまります。
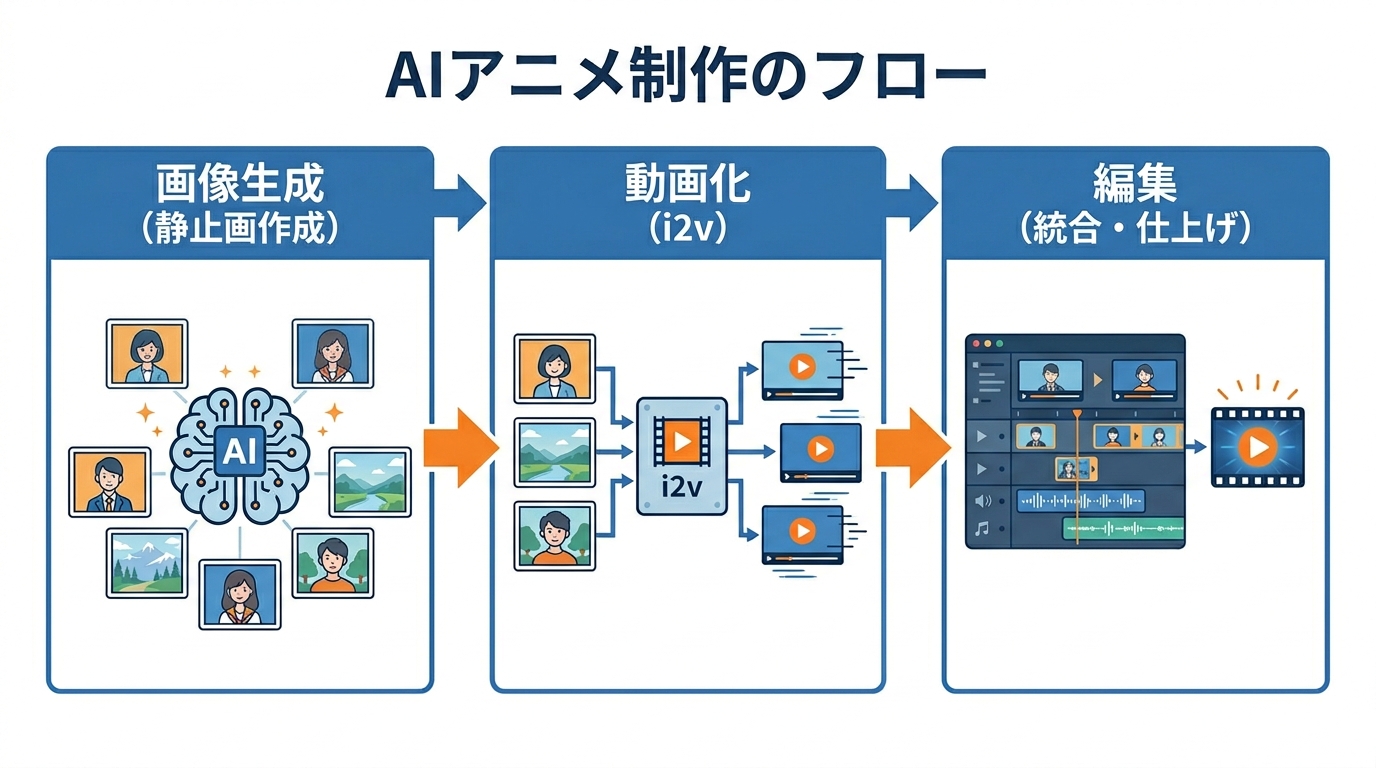
画像生成→動画化→編集の基本フロー
AIでアニメを作るとき、制作工程は大きく3つに分かれます。最初のステップは、ChatGPTやMidjourneyなどの画像生成AIを使い、ストーリーに沿った静止画を1カットずつ作ることです。次のステップでは、生成した静止画をKlingなどの動画生成AIに読み込み、i2v(Image to Video)機能で映像に変換します(参照*2)。
最後のステップは、生成された各カットの動画をつなぎ合わせ、音声やBGMを乗せて1本のアニメーションに仕上げる編集作業です。Animon Studioのように、画像編集・フレーム編集・動画出力の3つの主要工程をワンストップで扱える統合型のツールも登場しています(参照*3)。この3段階のフローを意識しておくと、どの工程にどのツールを使うかを判断しやすくなります。
逆に言えば、この3工程のどこに自分の時間とお金を投じるかを決めないまま着手すると、便利な実験で終わります。まずは「画像で詰まっているのか、動きで詰まっているのか、編集で詰まっているのか」を切り分けてから、ツール選定に進むのが現実的な順序です。
主要ツールの種類と特徴
画像生成AI(ChatGPT・Midjourney等)
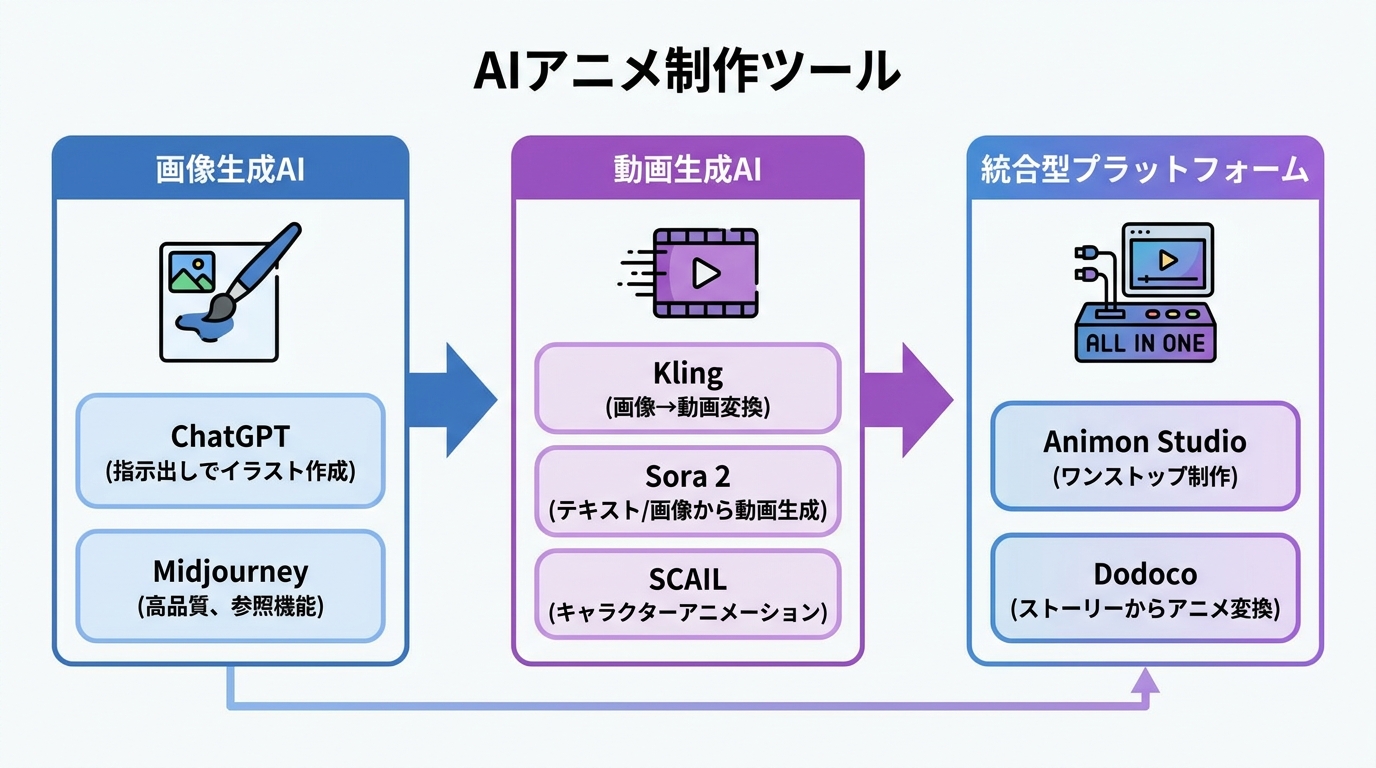
AIでアニメを作る第一歩は、キャラクターや背景の静止画を生成する工程です。ChatGPTの画像生成機能は、テキストで指示を出すだけでイラストを作れるため、絵を描く技術がなくても取り組みやすい入口になります。実際の制作事例では、ChatGPTでフェルト風の静止画やリアルな折り紙風のビジュアルを1カットずつ生成する手法が紹介されています(参照*2)。
Midjourneyは高品質なビジュアル表現に強みを持つ画像生成AIです。2025年5月、Midjourney v7に参照画像を使う機能(Omni-Reference)が登場しました。これは特定の画像を参照しながら一貫性のあるビジュアルを維持しつつ新しい画像を生成できる機能で、人物だけでなく物体や乗り物にも対応しています(参照*4)。キャラクターの見た目を揃えたい場面で役立つ選択肢です。
動画生成AI(Kling・Sora 2・SCAIL等)
静止画を映像に変えるのが動画生成AIの役割です。Klingはi2v(画像を動画に変換する機能)を備えており、生成した画像を1カットずつ読み込んでストップモーション風の映像に仕上げることができます(参照*2)。
Sora 2の動画生成ツール(Sora 2 Video Generator)は、テキストの指示や画像からAIが動画を生成するツールです。画像をアップロードするか詳しいテキストを入力し、AIの動画モデルを選んで生成ボタンを押すだけで映像を作れます(参照*5)。SCAILはオープンソースのキャラクターアニメーションの枠組みで、大きな動きの変化やスタイルの異なるキャラクター、複数キャラクターの掛け合いにも対応できます。フレームごとの構造的な指示を必要としない点が従来手法との違いです(参照*6)。私が動画生成モデルを比較するときに見ているのは、宣伝動画の派手さではなく、同じ静止画を入力したときの破綻の少なさと、再生成の安定性です。新モデルが出るたびに、手元の代表カットでテストするのが結局のところ一番早いと感じています。
統合型プラットフォーム(Animon Studio等)
画像生成から動画出力までを1つの環境で完結させたい場合、統合型プラットフォームが選択肢になります。Animon Studioは「大量生産」「制作効率」「芸術性」の3要素を両立させる制作支援システムで、画像編集・フレーム編集・動画出力をワンストップで扱えます。独自の画像生成モデル「Aniframe」は2K解像度に対応し、多彩なカメラワークやスタイルをカバーしています(参照*3)。
もう1つの選択肢として、Dodocoというアプリも存在します。AIが生成したストーリーをワンクリックで利用でき、既存のストーリーをAIでアニメ動画に変換する機能を備えています。複数話にまたがる連載形式の制作にも対応しており、音声選択やボイスクローン、BGM選択、AI自動カバー生成といった機能も搭載しています(参照*7)。
初心者向け制作手順
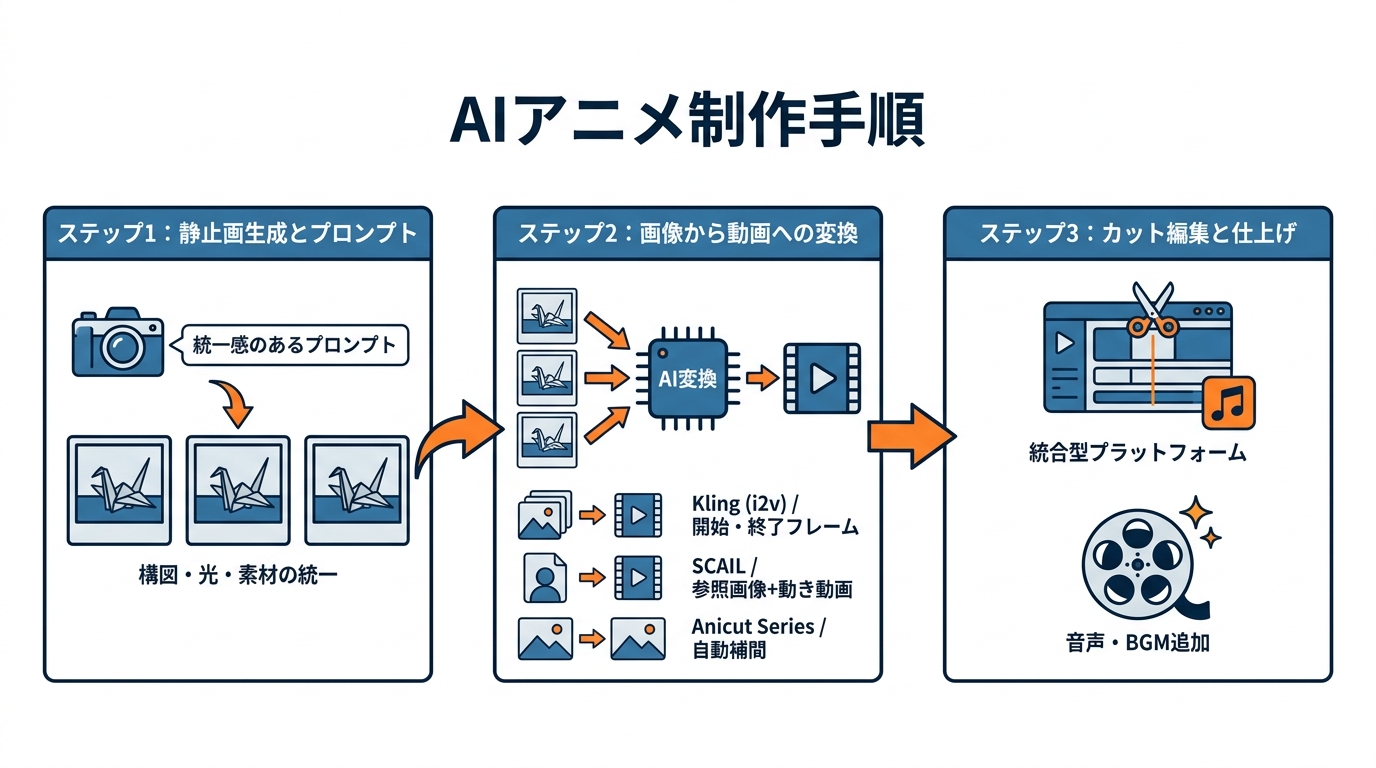
ステップ1:静止画の生成とプロンプト設計
AIでアニメを作るとき、最初にやるべきことはストーリーに沿った静止画を1カットずつ生成する作業です。ここでのポイントは、すべてのカットで構図・光の色温度・背景素材を統一し、つなぎ合わせたときに違和感が出ないようにすることです(参照*2)。
具体的な制作事例として、ChatGPTで折り紙風のリアルなビジュアルを生成する方法があります。この事例では「平面に置かれた白い折り紙」「鶴の形に折られた状態(灰色背景)」「青空を飛ぶ鶴の構図」という3種類のカットを生成しています(参照*8)。プロンプトでは、表現したい要素を具体的な質感や素材の言葉で記述することが品質の安定につながります。たとえばフェルト風のアニメでは「液体」ではなく「フェルトの糸、層、渦巻き」といった表現で指示を出す工夫が紹介されています(参照*2)。ここはテキストプロンプトでも同じですが、抽象語に逃げると出力も抽象的になります。具体的な回答を得るには、具体的な問いと材料を渡す。これがAIに対する基本姿勢だと考えています。
ステップ2:画像から動画への変換
静止画が揃ったら、動画生成AIを使って映像に変換します。Klingのi2v機能を使う場合、生成した画像を1カットずつ読み込み、動きを付けていきます。折り紙アニメの事例では、Klingで3枚の画像を開始フレームと終了フレームに設定し、「折り紙→鶴→飛翔」の流れを自然にアニメーション化しています(参照*8)。
SCAILを使う場合は手順が少し異なります。まずキャラクターの参照画像(JPGまたはPNG形式を推奨)をアップロードし、次に動きの元となる動画をアップロードします。必要に応じてテキストで補足指示を加え、解像度を480pまたは720pから選択して生成を開始します(参照*6)。Animon Studioの動画生成モデル「Anicut Series」では、開始フレームと終了フレームを指定すると、その間の動きを自動で生成します。フレームレートは16fpsで固定され、超解像アルゴリズムとの組み合わせにより480p 16fpsから1080p 24fpsへ画質を向上させることもできます(参照*3)。
ステップ3:カット編集と仕上げ
各カットの動画が完成したら、それらをつなぎ合わせて1本のアニメーションに仕上げる作業に入ります。Animon Studioのような統合型プラットフォームを使えば、画像編集・フレーム編集・動画出力を同じ環境で進められるため、ツール間でファイルをやり取りする手間を省けます(参照*3)。
音声やBGMを付ける段階では、Dodocoのように音声選択・ボイスクローン・BGM選択・動画プレビューの機能を一通り備えたアプリを活用する方法もあります(参照*7)。カット編集の段階で、ステップ1で意識した構図や光の統一感が効いてきます。逆に、編集で違和感が出るときは、たいてい上流の静止画生成で粒度が揃っていません。私は文章の編集でも同じ経験をしますが、下流での修正は上流の設計不足を補いきれないことが多いのです。
品質を高めるコツ
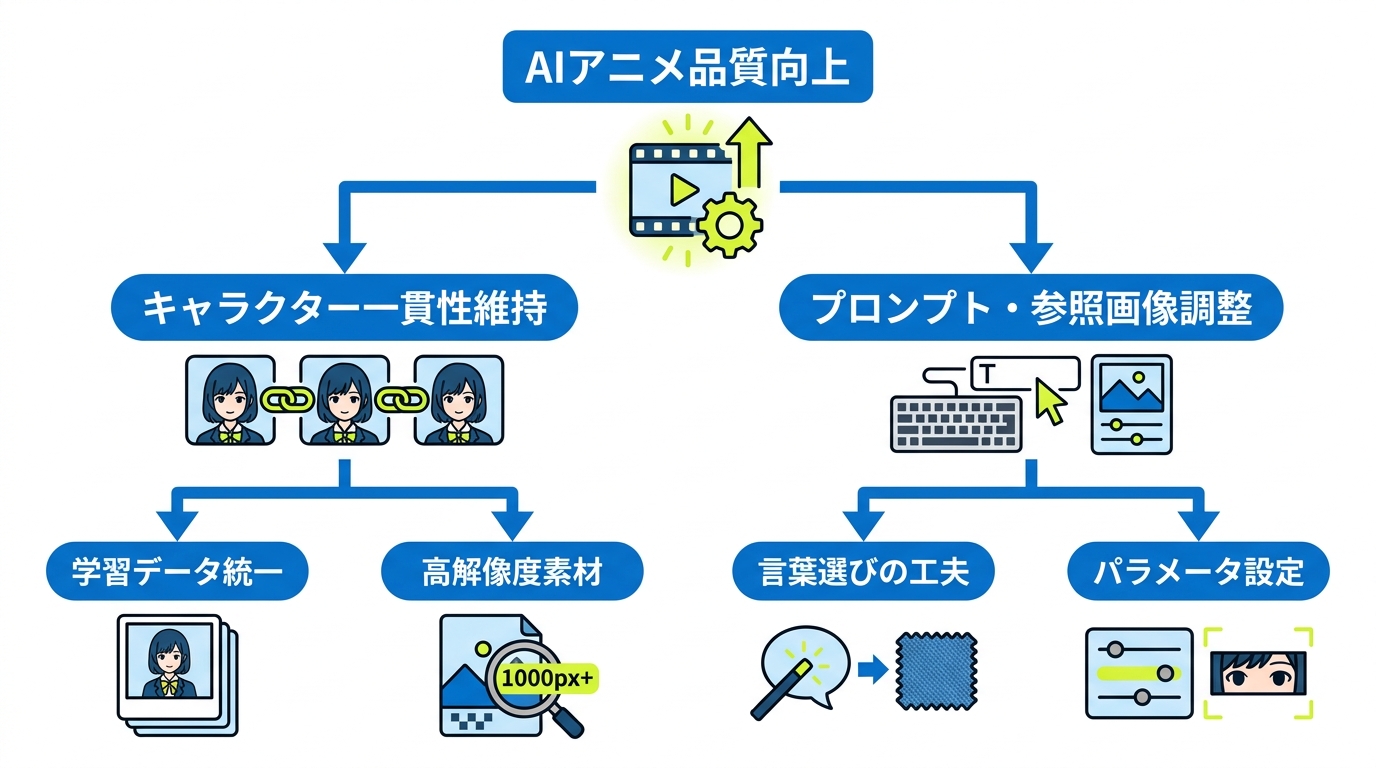
キャラクター一貫性の維持方法
AIでアニメを作る際に最も苦労しやすいのが、カットごとにキャラクターの顔や衣装が変わってしまう問題です。Midjourney v7のOmni-Reference機能を使うと、特定の画像を参照しながら新しいカットを生成できるため、キャラクターの見た目の一貫性を保ちやすくなります(参照*4)。
AIに特定のキャラクターや画風を学習させたい場合は、異なる見た目の画像を混ぜないことがポイントです。キャラクター学習では、同じキャラクターが同じ衣装を着た画像を使います。衣装を混ぜると出力結果で要素が混ざり合ってしまうため、複数の衣装を扱いたい場合は衣装ごとに別々のモデルを作るのが有効です(参照*9)。さらに、学習に使う画像は短辺1000px以上が推奨されています。解像度が低く細部がつぶれた画像を使うと、AIがその粗さを「正しい情報」として学習してしまい、出力がぼやけたり精細さに欠けたりする原因になります(参照*9)。
プロンプトと参照画像の調整術
プロンプトの書き方を工夫するだけで、AIでアニメを作るときの品質は大きく変わります。フェルト風アニメの制作事例では、背景と影の光温度を固定し、液体のような表現を「フェルトの糸、層、渦巻き」に置き換えるなど、素材感に合わせた言葉選びで映像の統一感を高めています(参照*2)。
参照画像の調整も品質向上の鍵を握ります。Midjourney v7のOmni-Referenceでは、試行錯誤の結果、パラメータow 200〜400が最適という結論が得られています。この範囲であれば、元のキャラクターの面影を残しつつMidjourneyらしい美しい描写が可能とされています。一方、参照が強すぎると自由な表現が制限されるため、服装を自由にしたい場合は顔のみの画像を添付し、髪型まで変えたい場合は目元中心の画像にするなど、参照範囲を絞る工夫が有効です(参照*4)。
つまり、プロンプトも参照画像も、一度決めて使い回すものではなく、テスト対象として扱うべきです。ある1カットでうまくいった設定が、別のカットで破綻することは普通に起きます。代表的なシーンを3〜5パターン用意し、設定を変えたときの出力を並べて比較する。この地味な検証が、最終的な品質を決めると私は考えています。
ツール比較と選び方
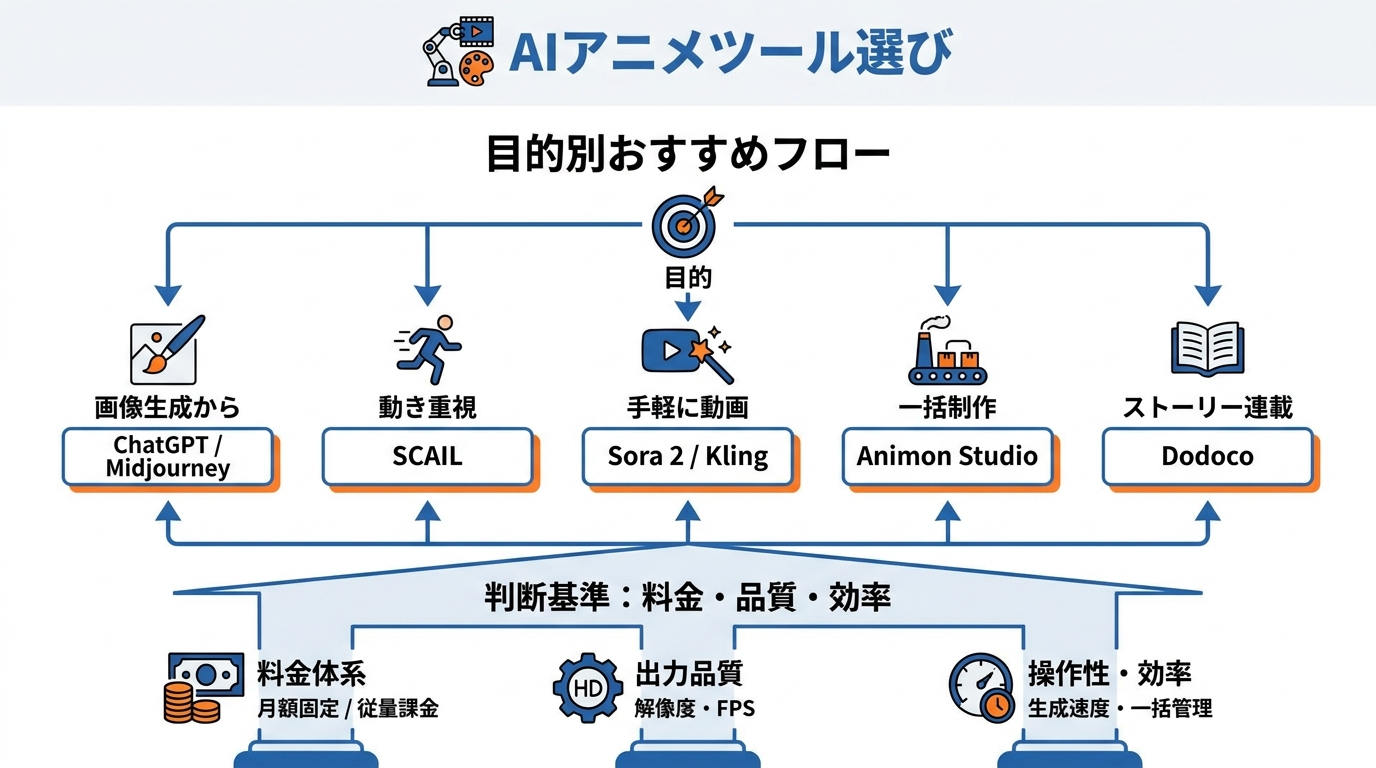
目的別おすすめツール早見表
AIでアニメを作るツールは、用途によって適した選択肢が変わります。以下に主なツールの特徴を目的別にまとめます。
- 画像生成から始めたい場合:ChatGPTの画像生成機能やMidjourney(Omni-Referenceでキャラクター一貫性を確保しやすい)
- キャラクターの動きを重視する場合:SCAIL(大きな動きの変化や複数キャラクターの掛け合いに対応)
- テキストや画像から手軽に動画を作りたい場合:Sora 2 Video GeneratorやKling
- 画像生成から動画出力まで一括で行いたい場合:Animon Studio(画像編集・フレーム編集・動画出力をワンストップで提供)
- ストーリーの連載形式で制作したい場合:Dodoco(複数話にまたがる制作や音声・BGM選択に対応)
自分がどの工程に一番力を入れたいかを軸に、ツールを選ぶのがコスト面でも作業効率面でも合理的です。
料金・解像度・操作性の判断基準
ツールを選ぶうえで、料金体系と出力品質のバランスは見逃せないポイントです。Animon Studioは月額49.9ドルで、画像・動画の生成タスクを無制限にリクエストできます。生成待ち時間を短縮する優先ルートも備えており、最大1080p/24fpsのHD解像度で動画を出力できます。500GBのクラウドストレージも付属し、3日間0.99ドルのトライアルも用意されています(参照*3)。
SCAILは従量課金制を採用しています。480pの場合は5秒あたり0.20ドル(1秒あたり0.04ドル)、720pの場合は5秒あたり0.40ドル(1秒あたり0.08ドル)で、最長120秒まで生成できます。5秒未満の動画でも最低5秒分が課金されます(参照*6)。月額固定で大量に生成したいか、必要なカットだけ従量課金で抑えたいかによって、最適なツールは異なります。私の経験では、検証段階は従量課金、量産段階は定額制という切り替え方が無駄が少ないやり方です。
失敗例と注意点
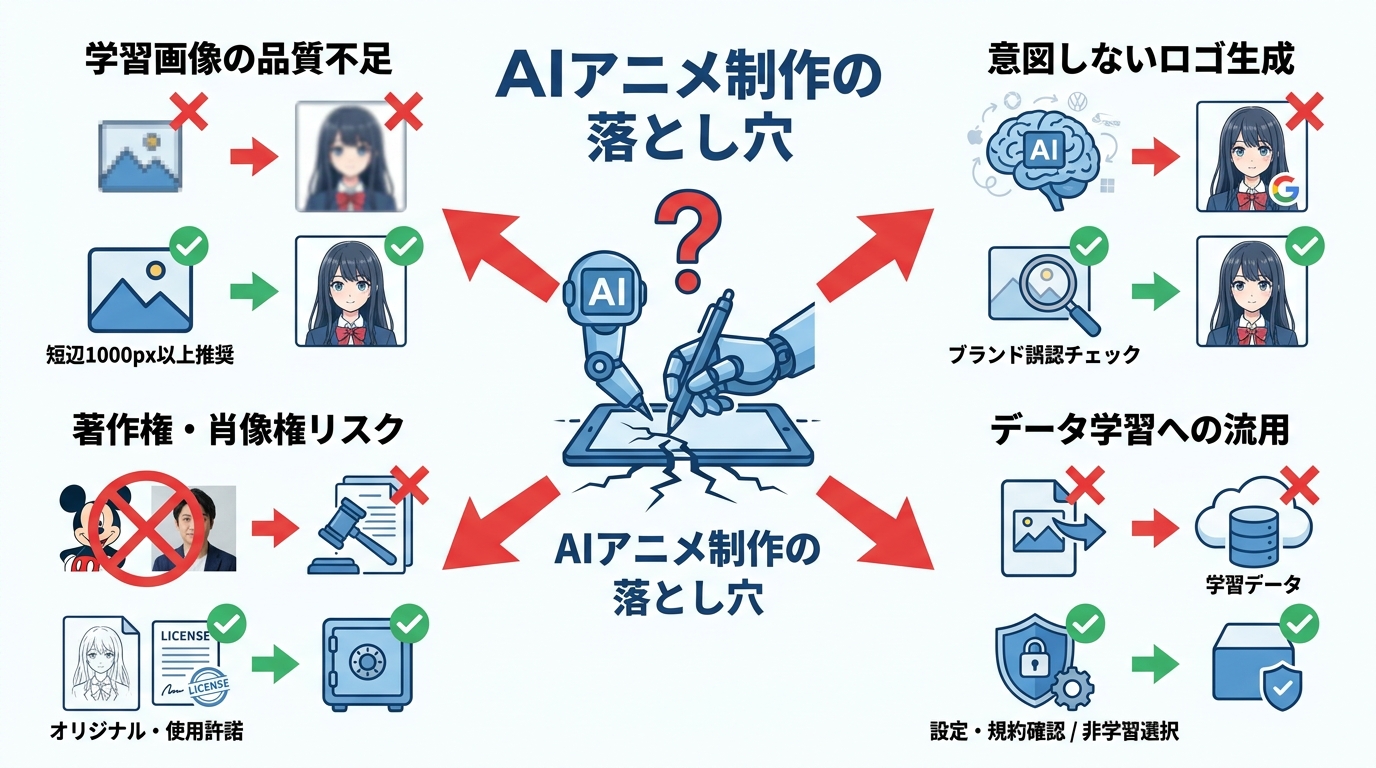
よくある失敗とその対策
AIでアニメを作る過程で起きやすい失敗の1つが、学習用画像の品質不足です。解像度が低く細部がつぶれた画像をAIに与えると、その粗さを「正しい情報」として学習してしまいます。出力がぼやけたり精細さに欠けたりする原因になるため、短辺1000px以上の画像を使うことが推奨されています(参照*9)。
もう1つ注意すべきなのが、AIが意図せず実在の企業ロゴを生成してしまうケースです。学習データの影響で、指示していなくても実在のロゴや製品デザインに似た部分が出力に含まれることがあります。公開や利用の前に、ブランドロゴと誤認される要素がないか注意深くチェックし、意図しない商標上の問題を避ける必要があります(参照*10)。
著作権・肖像権のリスク管理
AIでアニメを作るとき、法的なリスクへの配慮も欠かせません。元となる画像に実在の人物や有名キャラクターが含まれている場合、肖像権やパブリシティ権に関わる法的リスクが生じる可能性があります。安全に制作を進めるには、自分のオリジナルイラストを使う、使用許諾を得た素材を使う、判断に迷う場合は個人利用の範囲にとどめる、といった対策が有効です(参照*10)。
さらに、アップロードした画像がAIモデルの学習に使われる可能性にも注意が必要です。一部のAIサービスでは、設定や利用条件によってアップロード画像がモデルの訓練に利用される場合があります。未公開のキャラクターデザインや商用プロジェクトの素材を扱う場合は、プライバシーポリシーや設定を慎重に確認するか、データを学習に使用しないサービスを選ぶ対策が求められます(参照*10)。AIの出力をそのまま外に出すというのは、文章でも映像でも、制作の問題というよりリスク管理の問題です。誰が確認し、どの素材を使い、何かあったときに誰が責任を取るのか。ここを曖昧にしたまま公開すると、便利さの裏で大きな代償を払うことになります。
おわりに
AIでアニメを作るには、画像生成・動画変換・カット編集の3ステップを軸に、目的に合ったツールを選び、キャラクターの一貫性やプロンプトの精度を意識することが大切です。著作権やデータの取り扱いに関するリスクも、制作の初期段階から視野に入れておく必要があります。
まずは1カットだけでも静止画から動画に変換する体験をしてみると、AIでアニメを作る流れを肌で理解できます。小さく始めて少しずつ工程を広げることで、自分に合った制作スタイルが見えてくるはずです。AIを使うこと自体が価値になる時期は、おそらく長くは続きません。やがて問われるのは、何を作ったか、どこに自分の判断を入れたか、です。だから今のうちに、手を動かして自分なりの型を作っておくべきだと私は考えています。
監修者
安達裕哉(あだち ゆうや)
デロイト トーマツ コンサルティングにて品質マネジメント、人事などの分野でコンサルティングに従事しその後、監査法人トーマツの中小企業向けコンサルティング部門の立ち上げに参画。大阪支社長、東京支社長を歴任したのち2013年5月にwebマーケティング、コンテンツ制作を行う「ティネクト株式会社」を設立。ビジネスメディア「Books&Apps」を運営。
2023年7月に生成AIコンサルティング、およびAIメディア運営を行う「ワークワンダース株式会社」を設立。ICJ2号ファンドによる調達を実施(1.3億円)。
著書「頭のいい人が話す前に考えていること」 が、82万部(2025年3月時点)を売り上げる。
(“2023年・2024年上半期に日本で一番売れたビジネス書”(トーハン調べ/日販調べ))
参照
- (*1) アニメ制作の未来
- (*2) note(ノート) – Animating Felt Art with Generative AI | How to Create Handmade-Style Felt Animations Using ChatGPT × Kling
- (*3) Saiga NAK – AI animation production support system "Animon Studio" was officially released on July 29!
- (*4) KINTO Tech Blog – [Hands-On] How I Unified a Character's Appearance Using Midjourney v7's Omni-Reference
- (*5) KomikoAI – Sora 2 Video Generator
- (*6) SCAIL | Studio-Grade Character Animation with In-Context Learning | WaveSpeedAI
- (*7) Apps on Google Play
- (*8) note(ノート) – Creating Origami Animation with Generative AI | How to Make AI Origami Animations Using ChatGPT and Kling
- (*9) copainter Learn|AIを活用した漫画・アニメ制作を支援するメディア – Tips for Creating High-Accuracy, Company-Specific AI Models with copainter’s Training Feature
- (*10) copainter Learn|AIを活用した漫画・アニメ制作を支援するメディア – How can you create figure-style images with AI? A guide to using nano banana.
