
この記事のまとめ
Preferred Networksが開発した国産大規模言語モデル「PLaMo 3.0 Prime」は、2026年6月22日に正式提供が始まりました。海外モデルを借用せず、学習データからモデル設計まですべてを自社で構築した「フルスクラッチ」の国産モデルです。押さえておきたいポイントは次のとおりです。
- 推論モデル(Reasoning)と、高速応答に特化した非推論モデル(Non-reasoning)の2系統を提供し、業務内容に応じて使い分けられます。
- コンテキスト長は256Kトークンに拡張され、長文処理やAIエージェントとしての活用にも対応します。
- 日本語での指示追従やコーディング、ツール利用などの領域で、Qwen3.6-27BやGPT-5.4 miniといった同規模・同価格帯の海外モデルと同等以上の性能を示しています。
- NICTとの共同研究で得た安全性データを活用し、HELM Safetyで海外モデルと同程度以上の安全性を達成しました。
PFNとPLaMoシリーズの概要
Preferred Networksの事業と強み
Preferred Networksは国産生成AI基盤モデルをフルスクラッチで開発し、その成果をPLaMoシリーズとして提供しています(参照*1)。東京都千代田区に本社を置く日本企業で、代表取締役社長は岡野原大輔氏です。生成AIコンサルティングの現場で各モデルを比較してきた経験から言うと、「国産AI」を名乗るサービスの多くは実態として海外モデルのAPIラッパーであり、基盤モデルから自社開発している企業は数えるほどしかありません。
PLaMoは、Preferred Networksが独自に開発した国産の生成AI基盤モデルです。PLaMoのプラットフォーム上では、このモデルを活用した機能が大きく2つのカテゴリで提供されています(参照*2)。
基盤モデルそのものを完全に独自開発している国内企業はごく少数にとどまります。Preferred Networksはその数少ない企業の一つであり、モデル設計から学習データの構築まで一貫して自社で手がけている点に技術的な強みがあります(参照*3)。私が企業の生成AI導入を支援する際、「国産かどうか」よりも「どこまで自社で制御できるか」を重視するよう伝えています。その観点では、フルスクラッチ開発は単なる国産の証明ではなく、トークナイザー設計からファインチューニングまで自社でコントロールできるという実務上の強みを意味します。
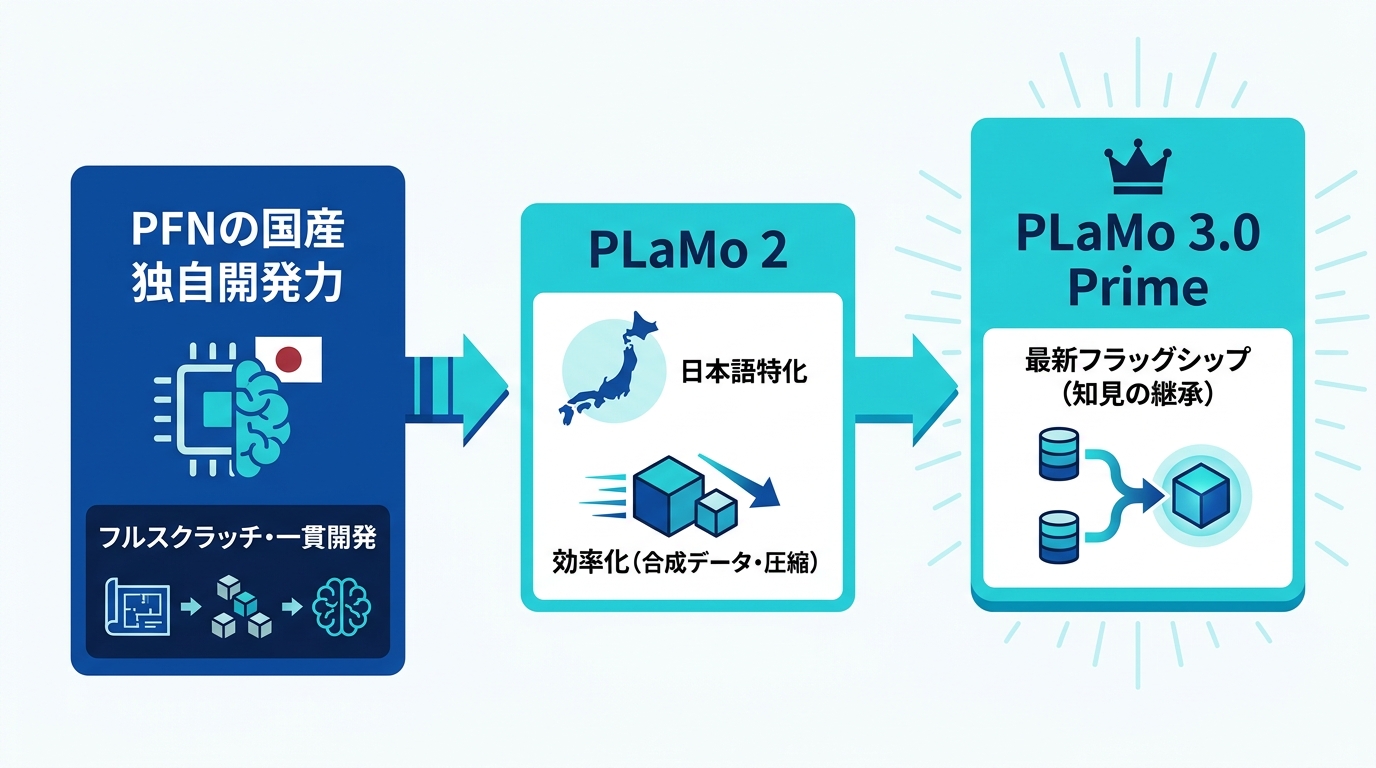
PLaMoシリーズの開発経緯
PLaMoシリーズは段階的に進化を遂げてきました。前世代のPLaMo 2は、日本語に焦点を当てた大規模言語モデル群であり、Sambaベースのハイブリッド構造を採用しています。継続事前学習によって完全な注意機構へ移行し、32Kトークンのコンテキスト長に対応しました。学習では、データ不足を克服するために大規模な合成コーパスを活用し、重みの再利用や構造化された枝刈りによって計算効率を確保しています。この効率的な手法により、8Bパラメータのモデルが以前の100Bパラメータのモデルと同等の性能を達成しました(参照*4)。
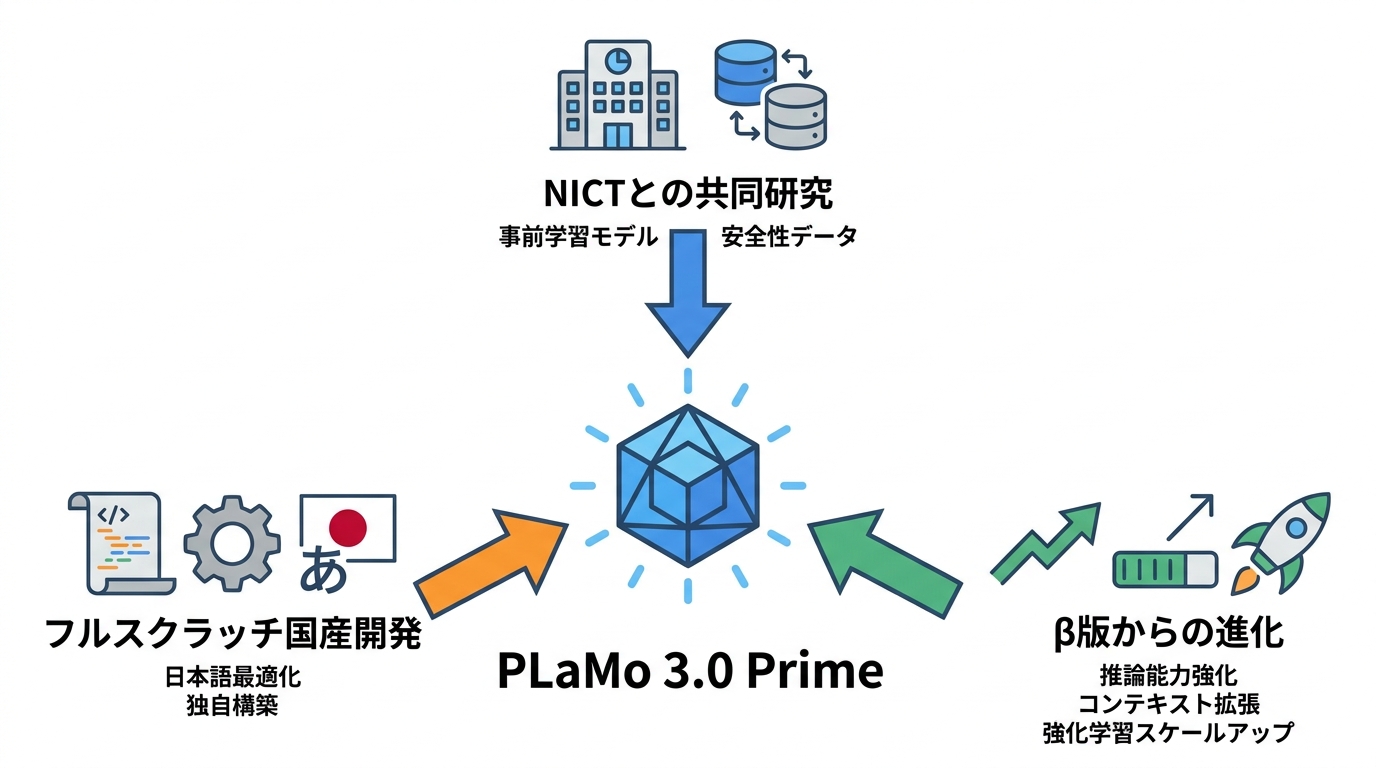
PLaMo 3.0 Primeは最新のフラッグシップモデルとして位置づけられています。NICTとの共同研究で得られた事前学習モデルをベースに開発され、2026年6月22日に正式提供が開始されました(参照*1)。前世代で培った合成データ活用やモデル圧縮の知見が、最新モデルの開発基盤として機能しています。
PLaMo 3.0 Primeの全体像
フルスクラッチ国産開発の意義
「フルスクラッチ」とは、既存の海外モデルを借用・改良するのではなく、学習データからモデル設計まですべてを自社で構築することを指します。ChatGPTやClaudeをベースにした国産AIサービスは多数存在しますが、基盤モデルを完全に独自開発しているケースは国内では非常に少なく、PLaMoはその数少ない例の一つです(参照*3)。私自身、ChatGPT、Claude、Gemini、Perplexityなど複数のモデルを業務タスクで比較してきましたが、日本語の処理品質はモデルのアーキテクチャよりも、学習データとトークナイザーの設計に大きく左右される印象があります。
フルスクラッチで開発することには、モデルの内部構造やトークナイザーを日本語に最適化できるという利点があります。日本語は英語と比べて同じ文章をトークンに変換した際の数が多くなりやすいため、独自のトークナイザーでこの効率を改善すると、日本語業務文書を大量に処理する場合の実際のコストに直接影響します(参照*5)。海外モデルの上に構築する方式では、こうしたレベルの最適化は困難です。企業がAPIコストを試算するとき、日本語処理の多いタスクでは英語前提で設計されたモデルより割高になるケースが多く、この点はあまり注目されていないわりに実務上の影響が大きいと感じています。
β版からの進化ポイント
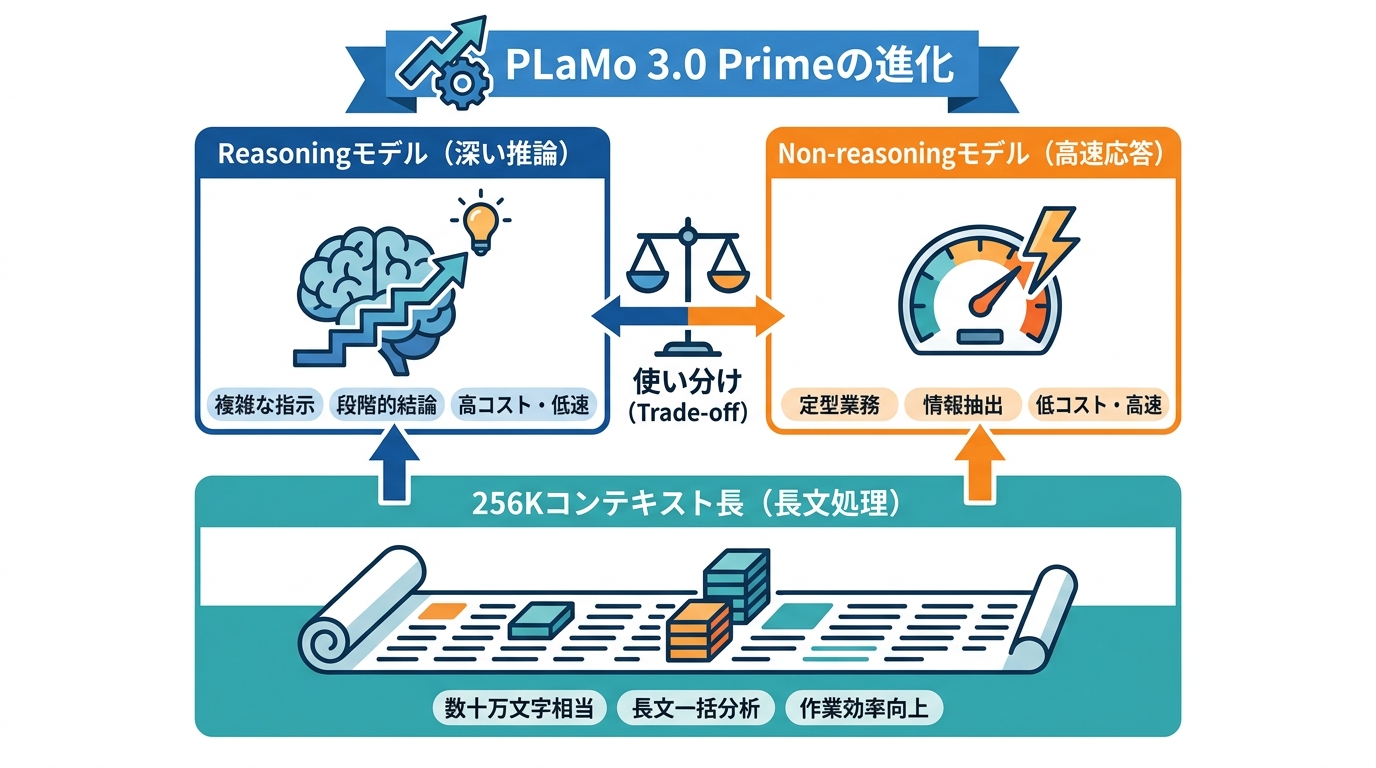
PLaMo 3.0 Primeは、β版をベースにモニター企業などからのフィードバックを踏まえ、さまざまな性能向上と安定化を施したモデルです。β版で初めて導入された推論能力がさらに強化され、同時に高速な応答が求められるユースケースに向けた非推論モデルも新たに開発されました。対応するコンテキスト長は64Kから256Kへと4倍に拡張されています(参照*6)。
強化学習についても大幅にスケールアップされています。β版と比べてデータをコーディング、長コンテキスト、対話性能など多方面にわたって増強し、強化学習のステップ数もおよそ2倍に拡大されました(参照*6)。β版からの変更は「微調整」にとどまらず、モデルの根幹にかかわる訓練量の拡充を伴うものです。
NICTとの共同研究の役割
PLaMo 3.0 Primeは、国立研究開発法人情報通信研究機構(NICT)との共同研究で得られた事前学習モデルをベースに開発されています(参照*1)。NICTとの連携は、モデルの基礎的な能力を築く事前学習段階で活用されており、国の研究機関が蓄積したデータや知見がモデルの土台を支えています。
NICTから提供を受けた安全性に関するデータは、PLaMo 3.0 Primeの安全性向上にも活用されました(参照*1)。API経由とオンプレミスの両方で利用可能なほか、Amazon Bedrock MarketplaceとSnowflakeでの提供も予定されています(参照*5)。
2系統モデルと256Kコンテキスト
Reasoningモデルの特徴と用途
Reasoningモデルは、複数の条件を整理しながら段階的に結論を導く能力に優れています。複雑な指示への対応、数理・アルゴリズム問題、専門性の高い質問応答、業務上の意思決定支援などの用途に適したモデルです(参照*1)。
Reasoningモードを有効にすると、内部で消費されるトークン数が大幅に増加します。ある検証では、Reasoning ONにするとトークン消費量が約35倍に膨らみ、応答までの時間も6倍から17倍に伸びました(参照*7)。推論の質と応答速度はトレードオフの関係にあるため、タスクの複雑さに応じてReasoningモデルとNon-reasoningモデルを使い分けることが実運用では欠かせません。私がOpenAIのo3系モデルやClaude Sonnetを業務で使う際も、同じ判断をしています。深い推論が必要な場面とそうでない場面を混同すると、コストだけが膨らんで処理速度も落ちるという状況になりがちです。
Non-reasoningモデルの特徴と用途
Non-reasoningモデルは、深い推論よりも応答速度が求められる用途に向けて設計されています。社内文書の要約、定型的な問い合わせ対応、情報抽出、分類、チャットボットなど、幅広い業務で効率的に活用できます(参照*1)。
Reasoningモードをオフにした場合、同じ質問でも応答トークン数は大幅に抑えられます。ある検証では、軽い質問に対して出力トークン数が60程度に収まったのに対し、Reasoning ONでは754まで増加しました(参照*7)。大量の定型業務を短時間で処理する場面では、Non-reasoningモデルを選ぶことでコストと速度の両面で有利に働きます。
256Kコンテキスト長の業務的価値
PLaMo 3.0 Primeでは、コンテキスト長が従来の64Kから256Kトークンへ拡張されました。これにより、長文の処理やAIエージェントとしての利用にも十分耐えうる仕様となっています(参照*8)。
256Kトークンは日本語に換算するとおよそ数十万文字に相当し、長大な契約書や技術文書、複数の資料を一括で投入して分析するといったタスクへの対応力が大きく向上します。β版の64Kでは分割して入力する必要があったケースでも、一度のやりとりで完結できる可能性が高まります。業務で扱う文書量が多い企業にとって、コンテキスト長の拡大は作業効率に直結する改善点です。
ベンチマーク結果と競合比較
日本語・英語ベンチマークの評価結果
PLaMo 3.0 Primeは、英語と日本語の両方にまたがる幅広いベンチマークで評価されています。評価軸には、IFBench、JFBench、MT-bench、Japanese MT-bench、BFCL v4(ツール利用)、BrowseComp-Plus、LongBench v1およびv2、AIME 2024、GPQA-Diamond、LiveCodeBench、lawqa_jp、MedRECT、医師国家試験、HELM Safetyが含まれます(参照*7)。
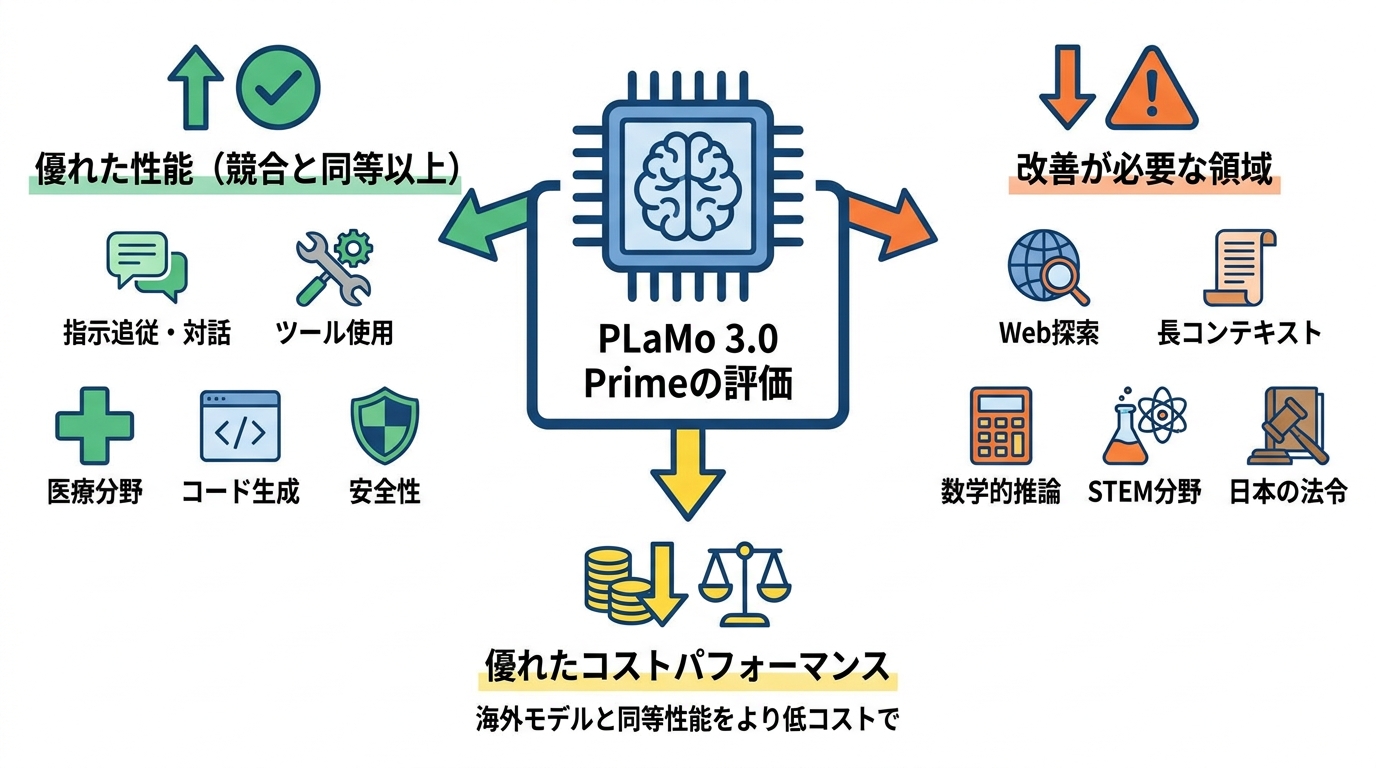
Qwen3.6-27B、gpt-oss-120b、GPT-5.4 Mini、Claude Haiku 4.5との比較では、多くのベンチマークで同等程度の性能を示しています。特に指示追従、対話、ツール使用、医療分野、コード生成能力、安全性ではより優れた性能を発揮している場合もあります。一方で、Web探索、長コンテキスト、数学的推論、STEM分野の質問応答、日本の法令分野では劣っており、今後の改善が必要であるとされています(参照*6)。得意領域と課題領域が明確に示されている点は評価できます。ベンチマーク全体で優劣を語るよりも、自社の主なタスクがどの領域に当たるかを確認するほうが実務判断としては正しく、その意味でこうした情報開示は導入側にとって有益です。
海外モデルとのコスト性能比較
PLaMo 3.0 Primeは、Qwen3.6-27Bのような同サイズのモデルだけでなく、GPT-5.4 mini、Claude Haiku 4.5などの同価格帯のモデルと比較して、複数の日本語ベンチマークにおいて同等以上の性能を示しています。推論にかかるコストは極めて低い水準にあり、同様の能力をより安く利用できるコストパフォーマンスに優れたモデルとされています(参照*9)。
前世代のPLaMo 3.0 Prime βおよびPLaMo 2.2 Primeと比較しても、主要ベンチマークで大幅な性能向上が確認されています。日本語での指示追従、コーディング、ツール利用などの領域で競争力のある結果を示しており、とりわけ日本語業務に重点を置く企業にとっては、海外モデルと同等の性能をより低コストで得られる選択肢として位置づけられます(参照*1)。
安全性評価とHELM Safety

大規模言語モデルを業務に導入する際、性能と同じくらい安全性の担保が欠かせません。PLaMo 3.0 Primeは、NICTから提供を受けた安全性に関するデータを活用して安全性向上に取り組みました。その結果、スタンフォード大学基盤モデル研究所が開発・運用する安全性評価ベンチマークスイート「HELM Safety」において、海外モデルと同程度以上の安全性能を達成しています(参照*1)。
HELM Safety v1.0は、暴力、詐欺、差別、性的コンテンツ、ハラスメント、欺瞞の6つのリスクカテゴリにまたがる5つの安全性ベンチマークで構成されています。24の主要な言語モデルを評価対象とし、安全性評価の標準化を目的とした継続的な取り組みとして運用されています(参照*10)。スタンフォード大学のAI Index Report 2026でも、HELM Safetyは責任あるAIと安全性の指標を横断的に評価するための数少ない標準化されたスイートの一つとして取り上げられています(参照*11)。
PLaMo 3.0 Primeは他のモデルと同程度以上の高い安全性能を示す一方、いくつかのカテゴリでは非推論モデルが過剰に拒否してしまったり、危険なプロンプトに応答してしまったりするケースが確認されており、さらなる改善が必要であるとされています(参照*6)。安全性はモデルのリリース時点だけでなく継続的に検証すべき領域であり、こうした課題が公開されていること自体が、導入を検討する側にとっては判断材料になります。私が企業の導入支援をする際も、安全性に関しては「問題がないモデル」を前提にするより、「どの種類のリスクがどの程度残っているか」を把握したうえで運用設計を組むよう伝えています。
API・料金・導入形態
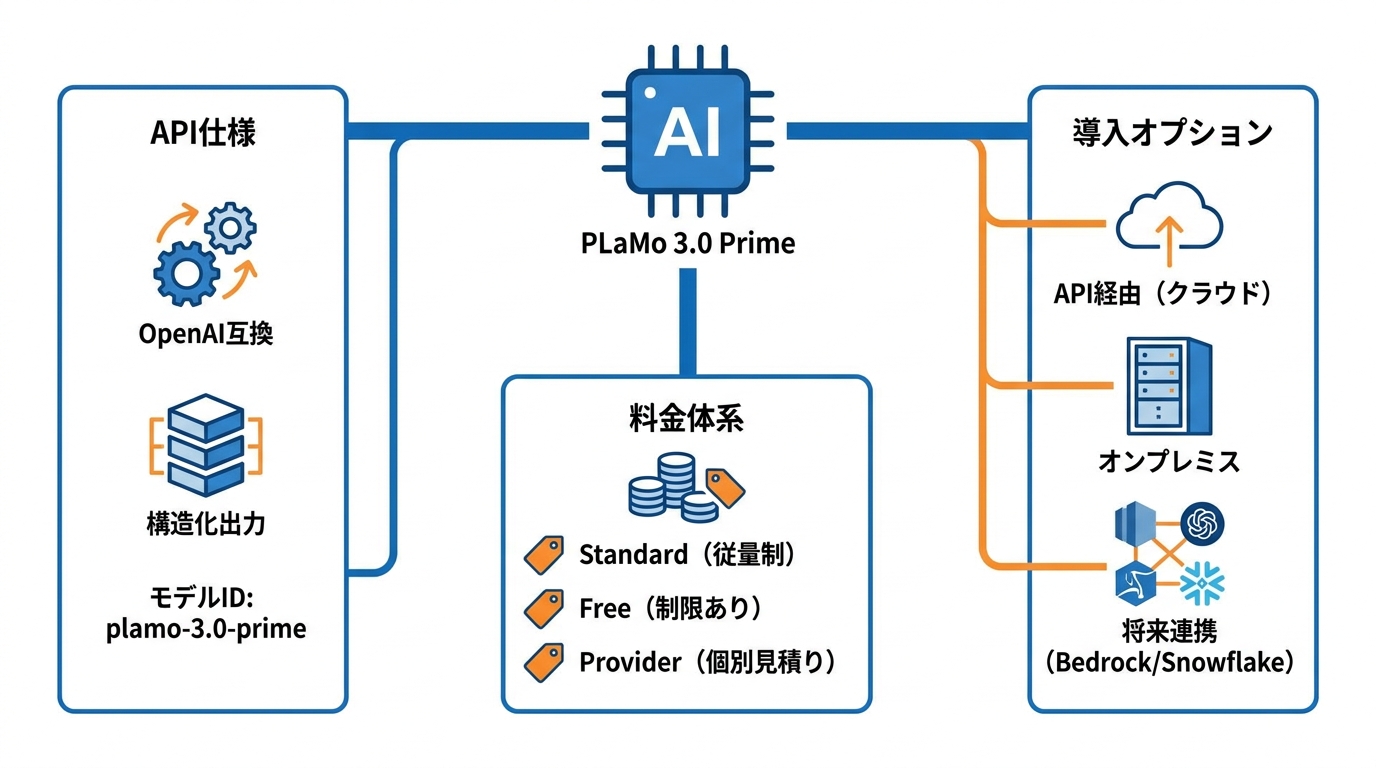
OpenAI互換APIと構造化出力
PLaMo 3.0 PrimeのAPIはOpenAI互換であり、エンドポイントとAPIキー、モデルID「plamo-3.0-prime」を指定すれば、既存のOpenAIクライアントからそのまま呼び出すことができます(参照*12)。モデルIDは「plamo-3.0-prime」で、コンテキスト長は262,144トークン、最大出力トークン数は20,000トークン、Reasoning機能にも対応しています(参照*13)。
構造化出力(Structured Output)にも対応しており、LLMからのレスポンスをユーザーが指定したデータ構造に必ず準拠する形で出力できます。従来のプロンプトによる形式指定では出力の安定性に課題がありましたが、この機能によって既存のシステムや外部APIと連携するアプリケーションの構築が大幅に容易になります(参照*6)。
料金プランとオンプレミス対応
PLaMo 3.0 Primeの料金は3プランで構成されています。Standardプランは入力60円/100万トークン、出力250円/100万トークンです。Freeプランは利用量制限つきで提供されており、Providerプランは個別見積りとなっています(参照*7)。
導入形態としては、API経由の利用に加え、オンプレミス(自社サーバー内)での利用にも対応しています。さらにAmazon Bedrock MarketplaceとSnowflakeでの提供も予定されています(参照*5)。セキュリティ上の理由でデータを外部に出せない企業でも導入を検討できる設計であり、クラウドとオンプレミスの選択肢が用意されている点は法人向けモデルとしての実用性を高めています。
社内利用事例と導入時の注意点
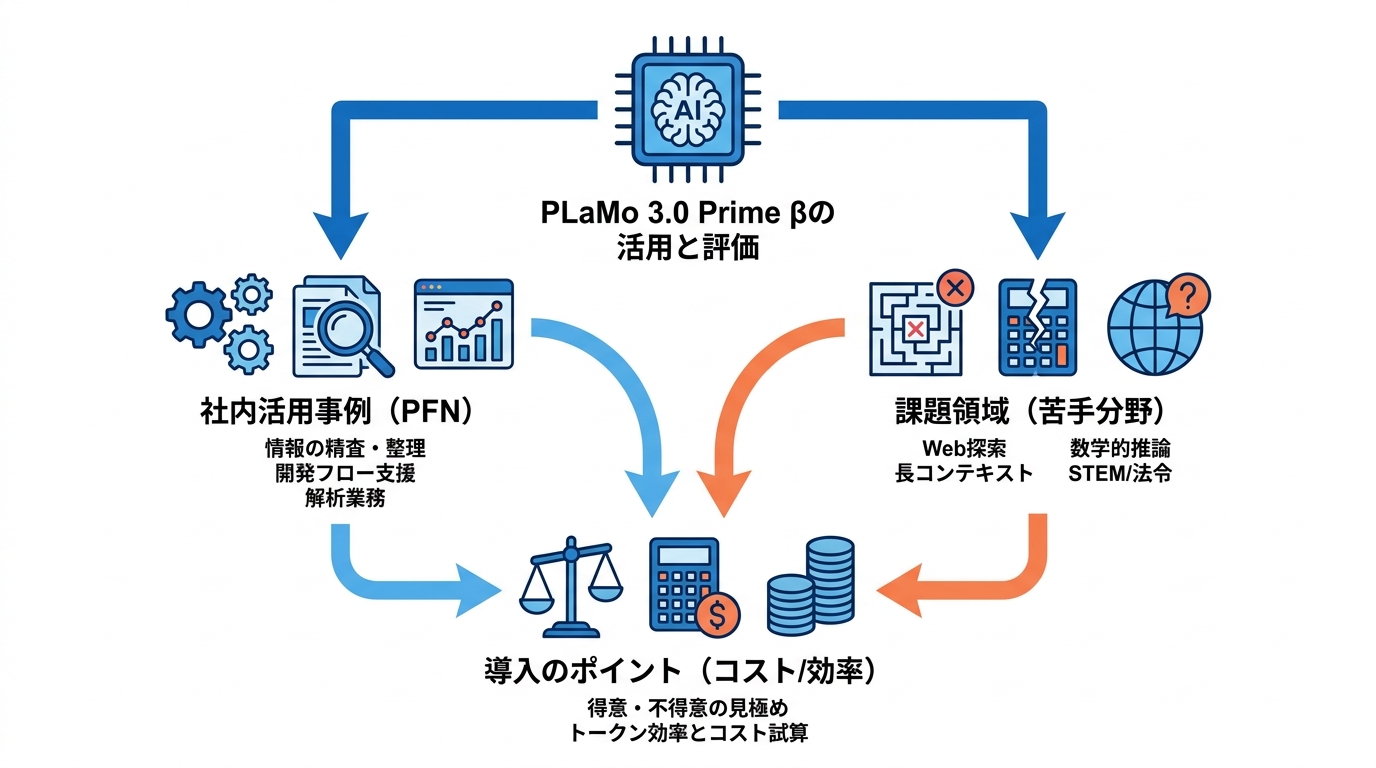
PFN事前学習チームの活用事例
Preferred Networksの事前学習チームは、PLaMo 3.0 Prime βを実際の開発フローに組み込んで利用してきました。営業日1日あたり入力30〜40Mトークン、出力1〜2Mトークンを使用しており、月単位では約700Mトークンに達する見込みです。膨大な規模とまでは言えないものの、単発のデモではなく、なくなると困る程度には開発フローに定着している数値とされています(参照*14)。
具体的な利用例としては、ベンチマーク評価結果の解析、CI(継続的インテグレーション)やワークフローの失敗原因の解析、開発ワークフローの支援、LLMエージェントのテストベッドといった用途が挙げられています。主に情報の精査・整理のためのLLMとして活用されています(参照*14)。開発チーム自身が日常業務で使い込む構造は重要です。外部向けのデモだけで完成度を測るより、内部の実務フローに組み込んで使われた結果として見えてくる課題のほうが、モデル改善につながりやすいからです。
導入時の注意点と課題領域
PLaMo 3.0 Primeは多くの領域で海外モデルと競争力のある結果を示していますが、すべてのタスクで上回っているわけではありません。Web探索、長コンテキスト処理、数学的推論、STEM分野の質問応答、日本の法令分野では性能が劣っており、今後の改善が必要な領域として公表されています(参照*6)。
日本語は英語と比べて同じ文章をトークンに変換した際の数が多くなりやすい特性を持っています。AI利用の料金はトークン数で決まるため、日本語の処理コストは英語より割高になりがちです。PLaMo 3.0 Primeの独自トークナイザーはこの効率を改善しており、日本語業務文書を大量に処理する場合の実際のコストに直接影響する要素です(参照*5)。導入を検討する際は、自社の主な用途が得意領域と課題領域のどちらに該当するかを見極めたうえで、トークン効率も含めた総合的なコスト試算をすることがポイントです。ベンチマークの数字だけを比較するのではなく、実際に自社の典型的なタスクを与えて挙動を確認するというステップを省かないようにしてください。
おわりに
Preferred NetworksのPLaMo 3.0 Primeは、フルスクラッチの国産モデルとしてReasoningとNon-reasoningの2系統を備え、日本語性能やコストパフォーマンスの面で海外モデルと競り合える水準に到達しました。NICTとの共同研究による安全性強化や256Kコンテキスト長への拡張など、企業利用を強く意識した設計が特徴です。国産モデルを選ぶ理由が「なんとなく安心」では意味がありませんが、トークン効率、データ主権、カスタマイズの自由度といった実務的な根拠があるなら、比較対象に入れる価値は十分にあります。
一方で、数学的推論やSTEM分野、法令領域などにはまだ改善の余地が残されています。自社の業務要件と照らし合わせながら、得意領域を活かせるタスクから試すというのが現実的なアプローチです。複数モデルを比較する際は、ベンチマークスコアだけでなく、実際の業務タスクを使った手元での検証を必ず加えることを勧めます。
監修者
安達裕哉(あだち ゆうや)
デロイト トーマツ コンサルティングにて品質マネジメント、人事などの分野でコンサルティングに従事しその後、監査法人トーマツの中小企業向けコンサルティング部門の立ち上げに参画。大阪支社長、東京支社長を歴任したのち2013年5月にwebマーケティング、コンテンツ制作を行う「ティネクト株式会社」を設立。ビジネスメディア「Books&Apps」を運営。
2023年7月に生成AIコンサルティング、およびAIメディア運営を行う「ワークワンダース株式会社」を設立。ICJ2号ファンドによる調達を実施(1.3億円)。
著書「頭のいい人が話す前に考えていること」 が、82万部(2025年3月時点)を売り上げる。
(“2023年・2024年上半期に日本で一番売れたビジネス書”(トーハン調べ/日販調べ))
参照
- (*1) 株式会社Preferred Networks – 国産生成AI基盤モデルPLaMo 3.0 Primeを正式リリース
- (*2) Overview of the PLaMo Platform
- (*3) AIの今を知り、使い方を学べる「Aibrary(アイブラリー)」- ニュース・コラム・活用ヒントがそろう知識の棚 – 国産AI「PLaMo 3.0」登場
- (*4) arXiv.org – [2509.04897] PLaMo 2 Technical Report
- (*5) note(ノート) – 「日本語AI」の多くは海外製の上に乗っている–PLaMo 3.0 Primeが違う理由
- (*6) Preferred Networks Tech Blog – PLaMo 3.0 Primeをリリースしました
- (*7) クラスメソッド発「やってみた」系技術メディア | DevelopersIO – PLaMo 3.0 Prime を試してみた
- (*8) 窓の杜 – 国産生成AI基盤モデル「PLaMo 3.0 Prime」が正式リリース ~推論特化と高速応答の2モデル
- (*9) PLaMo
- (*10) Stanford CRFM
- (*11) https://hai.stanford.edu/assets/files/ai_index_report_2026_chapter_3_responsible_ai.pdf
- (*12) AI革命株式会社 – PLaMo 3.0 Primeとは?PFN国産フルスクラッチLLMの料金・256Kコンテキスト・使い方を徹底解説
- (*13) API Reference | Reference
- (*14) Preferred Networks Tech Blog – PLaMo-3.0-Prime-β を LLM 開発の現場で使う
