
この記事のまとめ
AIで論文要約を効率化する方法は、大規模言語モデル(large language model:LLM)を活用してPDFの解析から構造化された要約の生成までを自動化することです。以下のポイントを押さえることで、精度と効率を両立できます。
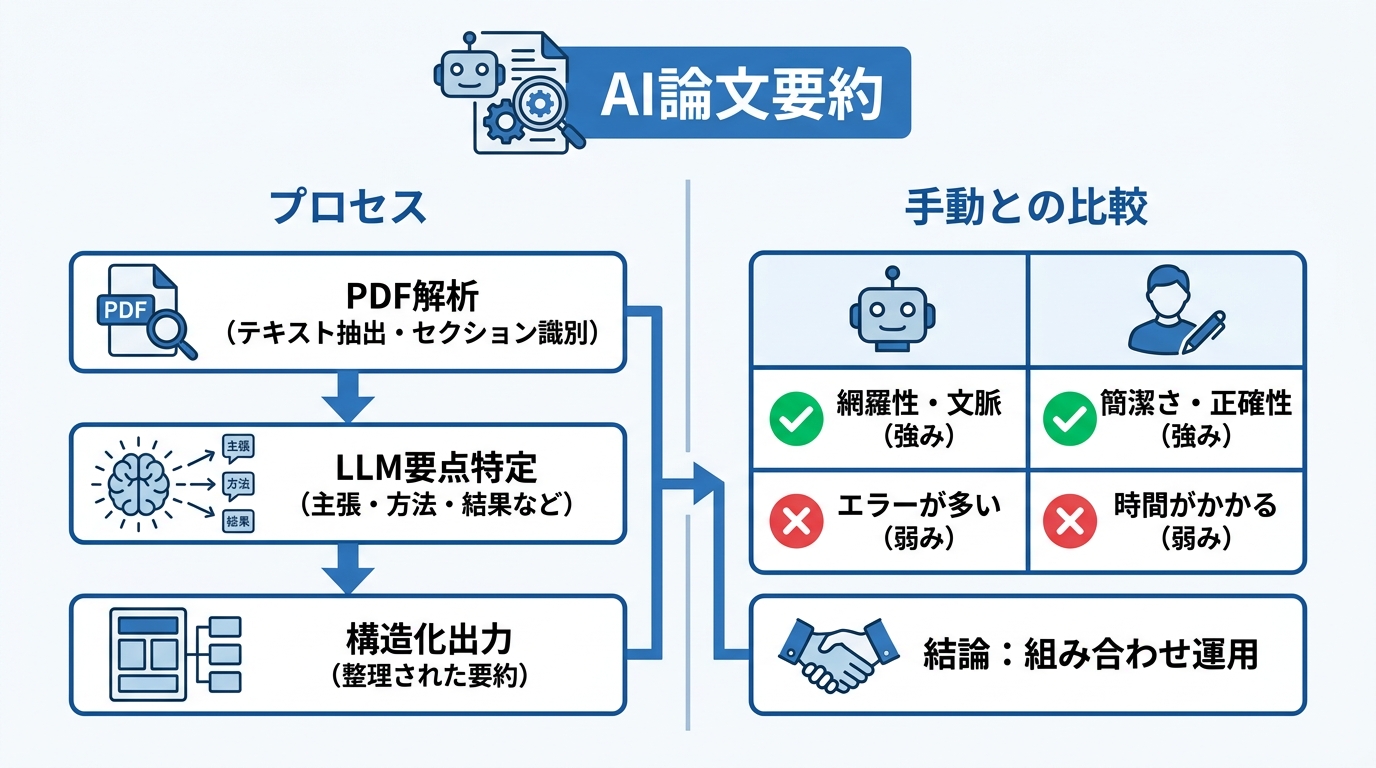
- AI論文要約は、PDF解析(テキスト抽出・セクション識別)→LLMによる要点の特定→構造化出力の3段階で機能し、手動では30分以上かかる内容を数分で処理できます。
- RAGパイプラインやプロンプトエンジニアリングといった手法を組み合わせることで、要約の正確性と網羅性を高められます。
- 汎用LLMと学術特化ツールには得意分野の違いがあり、目的に応じて使い分けることが精度向上の鍵です。
- AIの要約には情報の欠落やハルシネーション(事実と異なる内容の生成)のリスクがあるため、入力テキストの前処理や人の目による検証が欠かせません。
AI論文要約とは
論文要約におけるAIの役割
AIを使った論文要約は、PDF解析(テキスト抽出・セクション識別)→LLMによる要点の特定→構造化出力という3つの段階で進みます。まずPDFからテキストを抽出してセクションを識別し、次にLLMが主張・方法・結果・限界といった要素を特定し、最後に論文の各セクションと対応する形で構造化された要約が生成されます。性能の高いツールでは論文をベクトルとして埋め込み、意味検索によって追加の質問にも回答できます(参照*1)。
AIは、キーワードの生成、研究間の関連性の発見、複数論文にまたがる知見の要約、文献の整理と可視化といった作業を支援します。ただし、AIツールは従来の学術データベースを置き換えるものではなく、検索や読解の補助として位置づけられます(参照*2)。
手動要約との違い
手動の要約と比較した場合、AIはどの程度正確に論文の要点をとらえられるのかが重要な問いになります。Johns Hopkins大学で行われた研究では、生物医学分野の論文を対象にAIと人間が作成した注釈付き文献目録の質と正確性が比較されました。その結果、AI生成の注釈と人間が作成した注釈は論文の主要な論点を同程度にとらえていたことが確認されました。一方で、人間が書いた注釈のほうが短く解釈しやすい傾向があり、AIの注釈にはエラーが多いという違いも報告されています(参照*3)。
研究の質や文脈の評価、つまり対象の研究が他の研究とどう関連するかといった記述については、AIの注釈がやや優れているとされました。ただし、AIが示す研究の質や文脈に関する記述は常に正確とは限らず、人間の注釈よりもエラーが多い点が課題です。手動要約の正確さとAIの網羅性にはそれぞれ強みがあるため、両方を組み合わせる運用が実用的といえます。
AI論文要約の仕組みと主要手法
LLMによる抽出・生成の基本構造
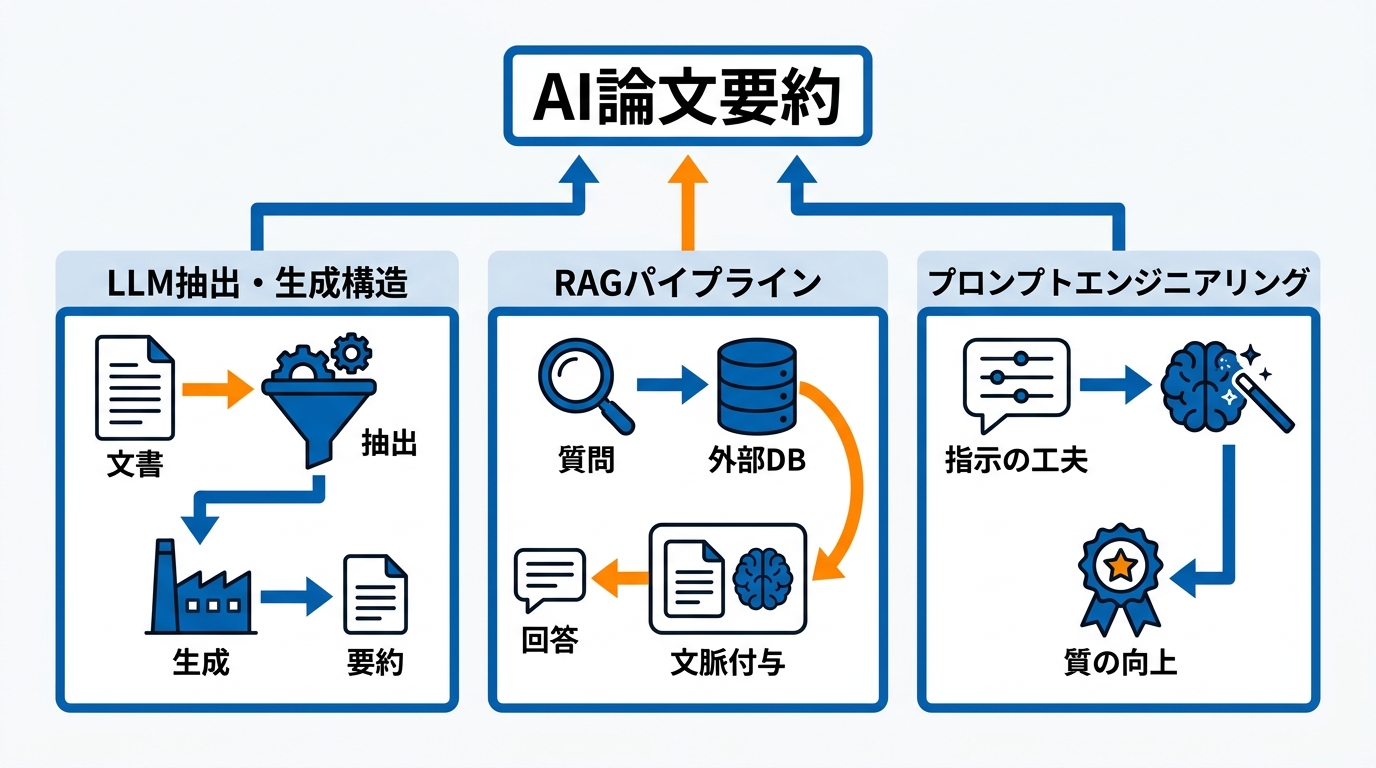
LLMを用いた論文要約では、文書から情報を「抽出」する処理と、抽出した情報をもとに新たな文章を「生成」する処理が組み合わさっています。PaperQA2と呼ばれる実装では、まずLLMが生成したキーワードで候補論文を検索し、各論文をチャンク(小さなテキストの塊)に分割して埋め込み表現に変換します。次に、質問文もベクトルに変換して上位k件の類似チャンクを特定し、各チャンクについてLLMがスコア付きの要約を作成します。LLMによる再スコアリングで関連性の高い要約が選別され、最終的にそれらの要約を文脈として組み込んだプロンプトから回答が生成されます(参照*4)。
この構造では、文書のメタデータを埋め込みに反映させることや、言語エージェントが繰り返し質問と回答を洗練させるエージェント型RAGの仕組みも採用されています。抽出と生成を段階的に行うことで、単なる文の切り出しではなく、元の論文の論理構造を保った要約が可能になります。
RAGパイプラインの活用
検索拡張生成(Retrieval-Augmented Generation:RAG)は、外部の文献データベースから関連情報を取得し、それをLLMに文脈として与えることで回答を生成する方法です。この方法を使うことで、LLMが学習データに含まれていない論文の内容にも対応できるようになります。
典型的なRAGパイプラインは6つのステップで構成されます。まず利用者が研究に関する質問を投げかけ、バックエンドがAPIや検索エンジンを通じて関連論文を取得します。取得した論文はテキストチャンクに分割され、ベクトル埋め込みに変換されます。利用者の質問文も同様にベクトル化され、類似度検索で上位k件のチャンクが取得されます。これらのチャンクが利用者のプロンプトに付加され、LLMが質問と取得した内容の両方を用いて回答を生成します(参照*5)。
このパイプラインは、論文を1本ずつ要約する場面だけでなく、複数の論文にまたがる横断的な質問への回答にも適用できます。チャンク分割の粒度や類似度検索の件数(k値)を調整することで、要約の詳しさや精度を制御できる点がRAGの特長です。
プロンプトエンジニアリングの技法
プロンプトエンジニアリングとは、LLMに入力する指示文を工夫・改善することで、出力の質を高める方法です。医療情報学の分野では、段階的にプロンプトを改良しながら有効な指示文を構築するプロトコルが提案されています。このプロトコルでは、評価に用いないランダムに選んだ文書を使ってプロンプトの設計とテストを行い、強調表示の有無によって異なる要約を生成する手順が取られています(参照*6)。
一方、論文の詳細を保持することに特化したFOCUSワークフローという方法もあります。この方法では、文書をセクションごとに処理し、効果量・手法名・正確な比較結果・著者自身の表現といった具体的な情報を直接引用として自然に埋め込みながら、すべての要点を抽出します。多くのAI要約が失いがちな詳細情報を網羅性として積極的に残す点に特徴があり、最終出力には概要を冒頭に配置し、セクションごとに整理した構成で仕上げます(参照*7)。
プロンプトの設計次第で要約の粒度や焦点が大きく変わるため、目的に合ったプロンプトをあらかじめテンプレートとして用意しておくことが、再現性のある要約づくりにつながります。
実践ワークフローの設計
PDF取り込みから要約生成までの手順
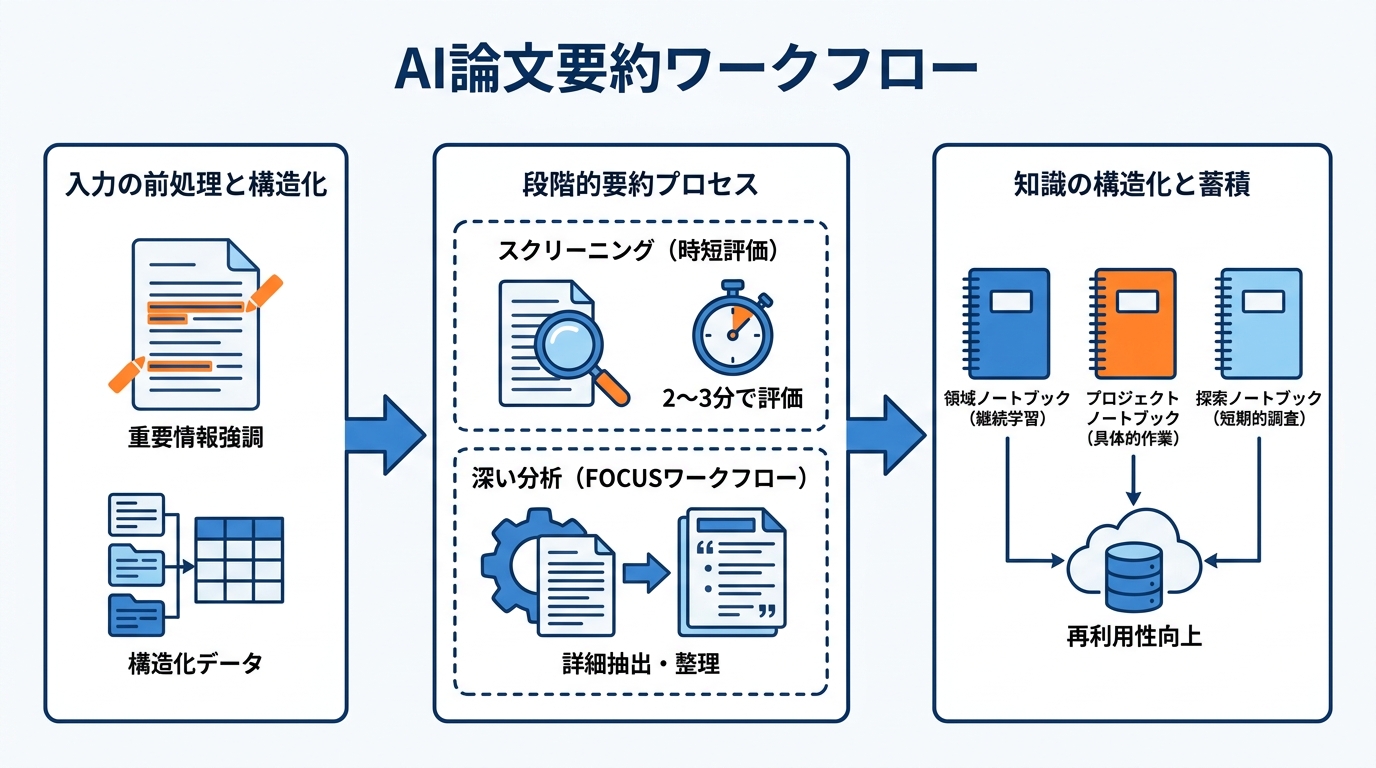
実際にAIで論文要約を行うワークフローは、PDFの取り込みから始まります。論文分析ツールを使うと、1文の要約、方法の分解、データ付きの主要な知見、限界、影響度スコアといった構造化された情報が論文から抽出されます。この処理により、30分以上かかる精読の代わりに2〜3分で論文の関連性を評価できるとされています。ただし、これはあくまでスクリーニングのための手段であり、重要な論文については精読の代替にはなりません(参照*8)。
FOCUSワークフローを適用する場合、手順は2段階に分かれます。最初の段階でセクションごとにすべての要点を抽出し、具体的な詳細と直接引用を自然に埋め込みます。次の段階で引用記号の除去、冒頭への概要・要点の追加、セクションの整理を行い、読みやすい最終出力に仕上げます(参照*7)。スクリーニングと深い分析を段階的に使い分けることが、実践的なワークフロー設計の基本です。
入力テキストの前処理と構造化
AIに渡すテキストの前処理は、要約の質を大きく左右します。医療分野の退院記録を対象にした研究では、重要な情報にハイライトを付けた入力と、ハイライトなしの入力をLLMに与え、それぞれの要約を比較する方法が採られています。この研究では、詳細情報を強調したハイライト付きの退院記録をLLMに提供することで、重要な情報の欠落を減らせるかどうかが検証されました(参照*6)。
ハイライト付きの入力から生成された要約は平均96%の完全性を示し、ハイライトなしの88%を8ポイント上回っています。この差は統計的にも有意な結果です。論文要約の場面に置き換えると、AIに渡す前の段階で重要なセクションや数値に目印を付けておくことが、出力の網羅性を高める前処理として機能することを示唆しています。
ノートブック型管理による知識蓄積
要約した論文の知識を蓄積し、後から参照できる形に整理する方法として、ノートブック型の管理が有効です。ノートブックを3種類に分けて運用する方法が提案されており、1つ目はAIの広い分野について継続的に学ぶための「領域ノートブック」で、知識を追記していく拠点として機能します。2つ目は特定の目標に向けた「プロジェクトノートブック」で、製品機能や成果物、発表準備など具体的な作業のために専用のノートブックを立ち上げます。3つ目は好奇心に基づく短期的な調査に使う「探索ノートブック」で、新しいモデルやフレームワークなど気になったテーマを一時的に掘り下げるために使います(参照*9)。
この3分類により、長期的な知識の蓄積と短期的な調査が混在せず、目的に応じたノートブックから必要な情報を素早く引き出せます。論文要約の結果をどのノートブックに格納するかをあらかじめ決めておくことで、蓄積した知識の再利用性が高まります。
主要AIツールの比較と選び方
汎用LLM(ChatGPT等)の特徴と限界
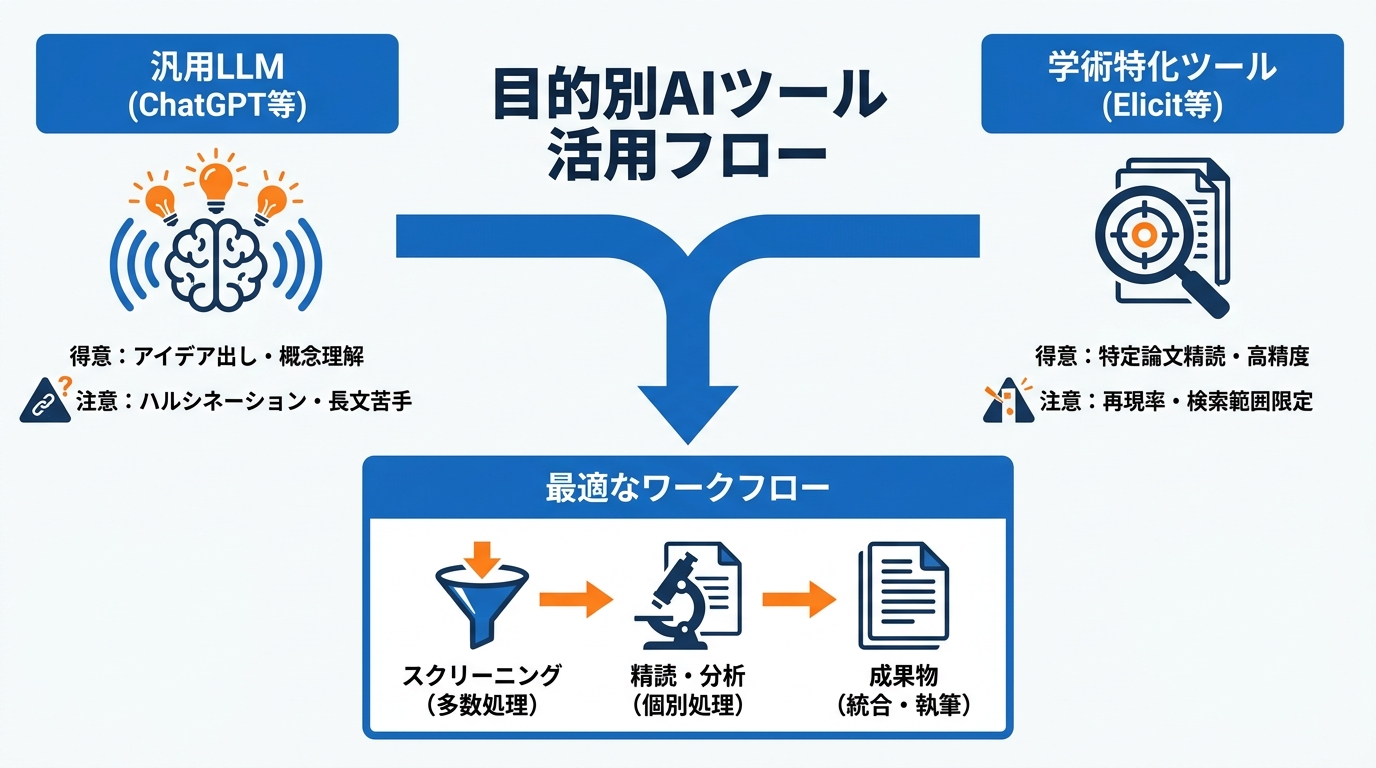
ChatGPTは、複雑な学術概念をわかりやすく分解し、研究上の問いに行き詰まったときに着想を広げる用途で広く使われています。しかし、30ページを超えるような長い論文ではコンテキストの上限に達しやすく、文書を分割して処理する必要が生じます。その結果、セクション間のつながりが失われるリスクがあります。さらに、ChatGPTは知識の空白を認める代わりに、実在しないがもっともらしい引用を生成してしまうことがある点も報告されています(参照*10)。
RAGを組み合わせない状態では、GPT-4の引用精度は13.4%(119件中16件が正確)、再現率は13.7%にとどまり、ハルシネーション率は約28.6%に上ります。GPT-3.5ではさらに低く、精度9.4%、再現率11.9%です(参照*5)。汎用LLMを論文要約に使う場合は、出力された引用や事実を必ず原文と照合する工程が不可欠です。
学術特化ツールの機能比較
学術用途に特化したAIツールとしては、Elicit、Connected Papers、ChatPDF、Jenny AIなどがあり、それぞれ異なる強みを持っています。これら4つのツールを、すでに出版された緑内障関連の系統的レビュー4本を対象にテストした研究では、特定の1本の論文に対して質問を投げかけた場合のほうが、フォルダ内の全論文に対して一括で質問した場合よりも正確な回答が得られることがわかりました。フォルダ単位での質問では、回答が不完全になったり不正確になったりする頻度が高かったため、1本ずつ個別に問い合わせる方法が推奨されています(参照*11)。
Elicitは研究上の問いを入力すると学術データベースから関連研究を検索し、要約を提示する機能を備えています。すでに蓄積された研究分野では高い性能を発揮しますが、データベースへのアクセス範囲に依存するため、結果が限定的になる場合があります(参照*10)。Elicitの検索感度(再現率)は平均39.5%で、従来の検索手法の94.5%と比べると低い一方、適合率は平均41.8%で従来の7.55%を上回っており、従来の検索では見つからなかった論文を特定できたケースも報告されています(参照*12)。
目的別の選定基準
ツール選定では、自分の目的に合った強みを持つものを選ぶことが大切です。たとえば、複雑な概念のかみ砕きやアイデア出しには汎用LLMが向いていますが、長い論文の一括処理や正確な引用が必要な場面では、学術特化ツールを併用するほうが実用的です。1本ずつ個別に論文を処理したほうが正確性が高まるという研究結果からも、大量の論文を一度に処理するのではなく、スクリーニングと精読の段階で使うツールを分けるワークフローが有効といえます。
メタアナリシス(複数の研究結果を統計的に統合する手法)の用途では、Paperguide、Elicit、SciSpace、RevMan、Rayyanといったツールが、スクリーニングの自動化やデータ抽出、効果量の計算、エビデンスの統合を支援するものとして挙げられています(参照*13)。論文の要約だけでなく、その先の分析工程まで見据えてツールを選ぶことで、作業全体の効率が上がります。
要約精度の検証と注意点
完全性・正確性・構造整合性の評価指標
AIが生成した要約の質を測るうえで、完全性(必要な情報がどれだけ含まれているか)、正確性(内容が事実と合っているか)、構造の整合性(元の論文の構成と対応しているか)という3つの軸が参考になります。退院記録を対象にした研究では、ハイライトなしの入力から生成された要約の完全性が平均88%(標準偏差6%)であったのに対し、ハイライト付きの要約は96%(標準偏差4%)に達しました。フィッシャーの正確検定ではP値が0.01となり、統計的に有意な差が確認されています(参照*6)。
正確性の面では、AIの注釈は人間と同程度に論文の主要な論点をとらえる一方で、研究の質や文脈に関する記述にエラーが多い傾向が報告されています(参照*3)。AI要約を受け取ったあとに、元の論文との照合をチェックリスト形式で行う方法も提案されており、要約の正確性を読者自身が判断できる仕組みが求められています(参照*14)。
ハルシネーションと情報欠落への対策
AIによる論文要約の最大のリスクは、ハルシネーション(事実に基づかない情報の生成)と情報の欠落です。GPT-4では引用のハルシネーション率が約28.6%に達するというデータがあり、もっともらしい架空の文献が提示される事例が報告されています(参照*5)。ハルシネーションや偏り、不十分な網羅性はAIツールを使ううえで常に意識すべきリスクです(参照*2)。
Michigan State大学の研究チームは、LLMの内部状態に小さな変動を加えることで出力の信頼度を測る方法を開発しました。CCPSと呼ばれるこの方法は、AIが表明する確信度と実際の正確さとのずれ(キャリブレーション誤差)を、従来手法と比べて平均で半分以上削減したと報告されています(参照*15)。入力テキストの前処理で重要箇所を強調すること、RAGにより原文を文脈として与えること、そして出力後に人がチェックリストで照合することが、現時点で実行できる主な対策です。
おわりに
AIで論文要約を効率化するには、RAGやプロンプトエンジニアリングといった手法の理解、入力テキストの前処理、目的に応じたツールの選定、そして出力の検証という一連のワークフローを組み立てることが欠かせません。どの手法やツールにも得意な領域と限界があるため、自分の研究目的や扱う論文の分野に合わせて組み合わせを調整することが、精度と効率を両立させる鍵です。
AIの要約はスクリーニングの時間を大幅に短縮してくれますが、ハルシネーションや情報欠落のリスクは常に伴います。最終的には人の目で原文と照合する工程を外さず、AIを「読解の補助」として位置づけることで、論文要約の質と生産性を高めることができます。
監修者
安達裕哉(あだち ゆうや)
デロイト トーマツ コンサルティングにて品質マネジメント、人事などの分野でコンサルティングに従事しその後、監査法人トーマツの中小企業向けコンサルティング部門の立ち上げに参画。大阪支社長、東京支社長を歴任したのち2013年5月にwebマーケティング、コンテンツ制作を行う「ティネクト株式会社」を設立。ビジネスメディア「Books&Apps」を運営。
2023年7月に生成AIコンサルティング、およびAIメディア運営を行う「ワークワンダース株式会社」を設立。ICJ2号ファンドによる調達を実施(1.3億円)。
著書「頭のいい人が話す前に考えていること」 が、82万部(2025年3月時点)を売り上げる。
(“2023年・2024年上半期に日本で一番売れたビジネス書”(トーハン調べ/日販調べ))
参照
- (*1) PapersFlow – Best AI Paper Summarizers in 2026: How to Read Research Papers 10x Faster
- (*2) AI Tools for Literature Reviews
- (*3) New Study Shows Pros vs. Cons of Using ChatGPT in Research Process
- (*4) GitHub – Future-House/paper-qa: High accuracy RAG for answering questions from scientific documents with citations · GitHub
- (*5) IntuitionLabs – How to Connect ChatGPT to Scientific Literature via RAG
- (*6) JMIR Medical Informatics – Improving Large Language Models’ Summarization Accuracy by Adding Highlights to Discharge Notes: Comparative Evaluation
- (*7) GitHub – stephenturner/skill-focus: Summarize a paper with the FOCUS method · GitHub
- (*8) PapersFlow – AI Paper Analysis: Get TL;DR, Methodology, and Key Findings Without Reading the Full Paper
- (*9) How I Set Up a Personal AI Research Notebook That I Actually Use Daily
- (*10) anara.com – AI research paper summarizer that links to sources? Yes, finally.
- (*11) JMIR AI – JMIR AI – Evaluation of AI Tools Versus the PRISMA Method for Literature Search, Data Extraction, and Study Composition in Glaucoma Systematic Reviews: Content Analysis
- (*12) PubMed Central (PMC) – Comparison of Elicit AI and Traditional Literature Searching in Evidence Syntheses Using Four Case Studies
- (*13) Paperguide Blog – 5 Best AI Tools for Meta Analysis in 2026
- (*14) OEGlobal Connect – Simple Checklists to Verify the Accuracy of AI‑Generated Research Summaries
- (*15) Michigan State University – How reliable is AI information?
