
この記事のまとめ
AIによる文章要約は、元のテキストから重要な情報を短くまとめる技術です。初心者がこの技術を活用するために、押さえておきたいポイントは次の通りです。
- 文章要約には「抽出型」と「生成型」の2種類があり、正確さ重視か読みやすさ重視かで使い分ける
- BART、Pegasus、T5などのオープンソースモデルのほか、GPT-4やClaudeなどの商用APIも選択肢になる
- 精度の評価にはROUGEやBERTScoreなどの自動指標と、人間による評価を組み合わせるのが効果的
- ハルシネーション(事実と異なる内容の生成)や著作権の問題など、実務で注意すべき落とし穴もある
AI文章要約の定義と背景
AI文章要約とは
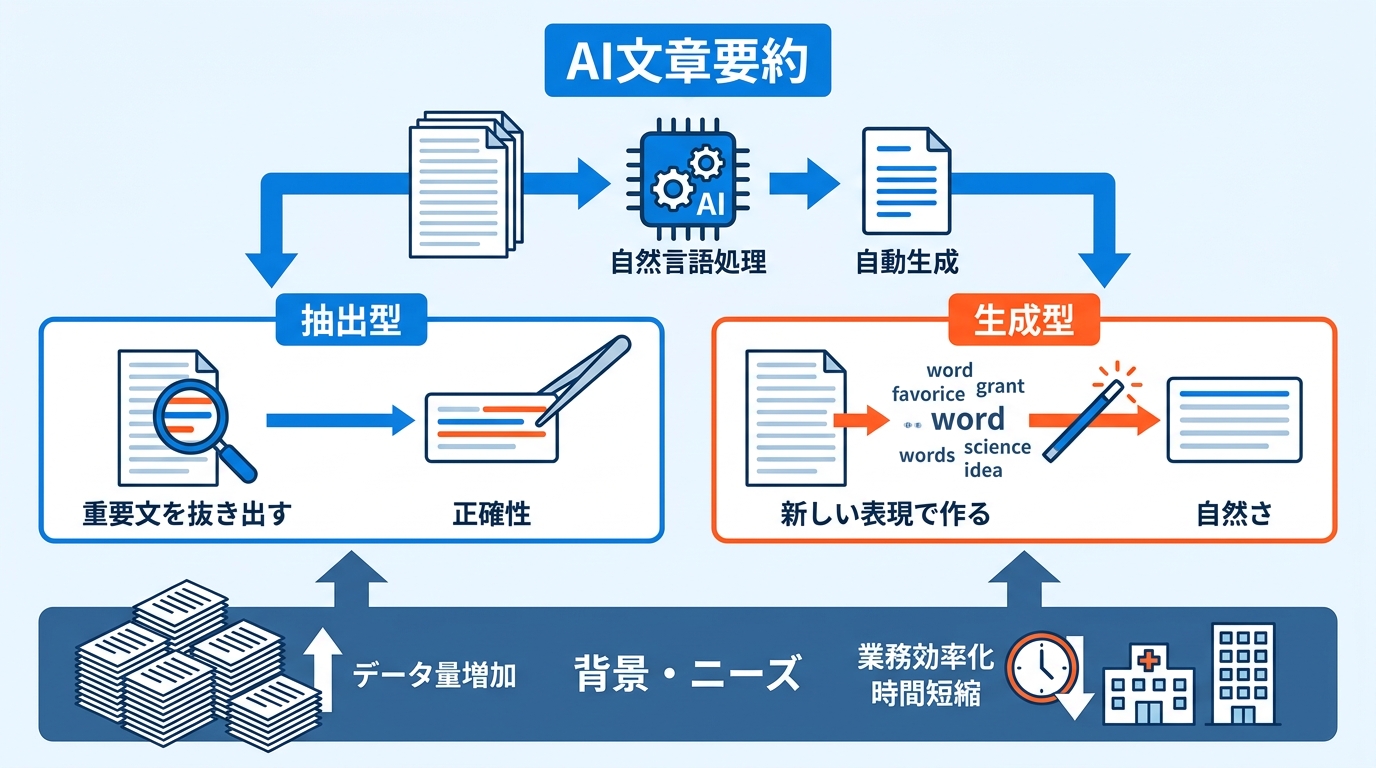
AI文章要約とは、自然言語処理の技術を使って、文書や会話などのテキストから短い要約を自動で生成する仕組みです。手作業で文章を読んでまとめる必要がなくなるため、大量の情報を扱う場面で特に力を発揮します。
この技術には大きく2つのやり方があります。1つは「抽出型」で、元のテキストの中から重要な文をそのまま抜き出す方法です。もう1つは「生成型」で、元のテキストにない表現を使いながら、簡潔で読みやすい要約文を新たに作り出す方法です(参照*1)。
どちらの方法を選ぶかによって、要約の性質が変わります。抽出型は元の文章をそのまま使うため正確性が高く、生成型は自然で読みやすい文章になりやすいという違いがあります。目的や用途に応じて使い分けることが、AI文章要約を活用する第一歩です。
要約ニーズが高まる理由
文章要約へのニーズは、日々生まれるデータ量の増加とともに広がっています。医療の分野では、患者の診療記録や検査結果といった膨大なデータが毎日蓄積されており、正確な要約が臨床レビューや保険の査定、監査などで欠かせないものになっています(参照*2)。
ビジネスの現場でも、その効果は具体的な数字に表れています。ある保険会社の事例では、AIによる通話内容の要約が1件あたり約4分の時間短縮につながり、年間で56,000時間もの削減を実現しました(参照*3)。
こうした事例が示しているのは、AI文章要約が「あると便利な機能」ではなく、業務を支える基盤として使われ始めているということです。情報量が増えるほど、人が手作業で要約する負担は大きくなるため、AIへの期待は今後も続くと考えられます。
要約手法の種類と仕組み
抽出型要約の特徴
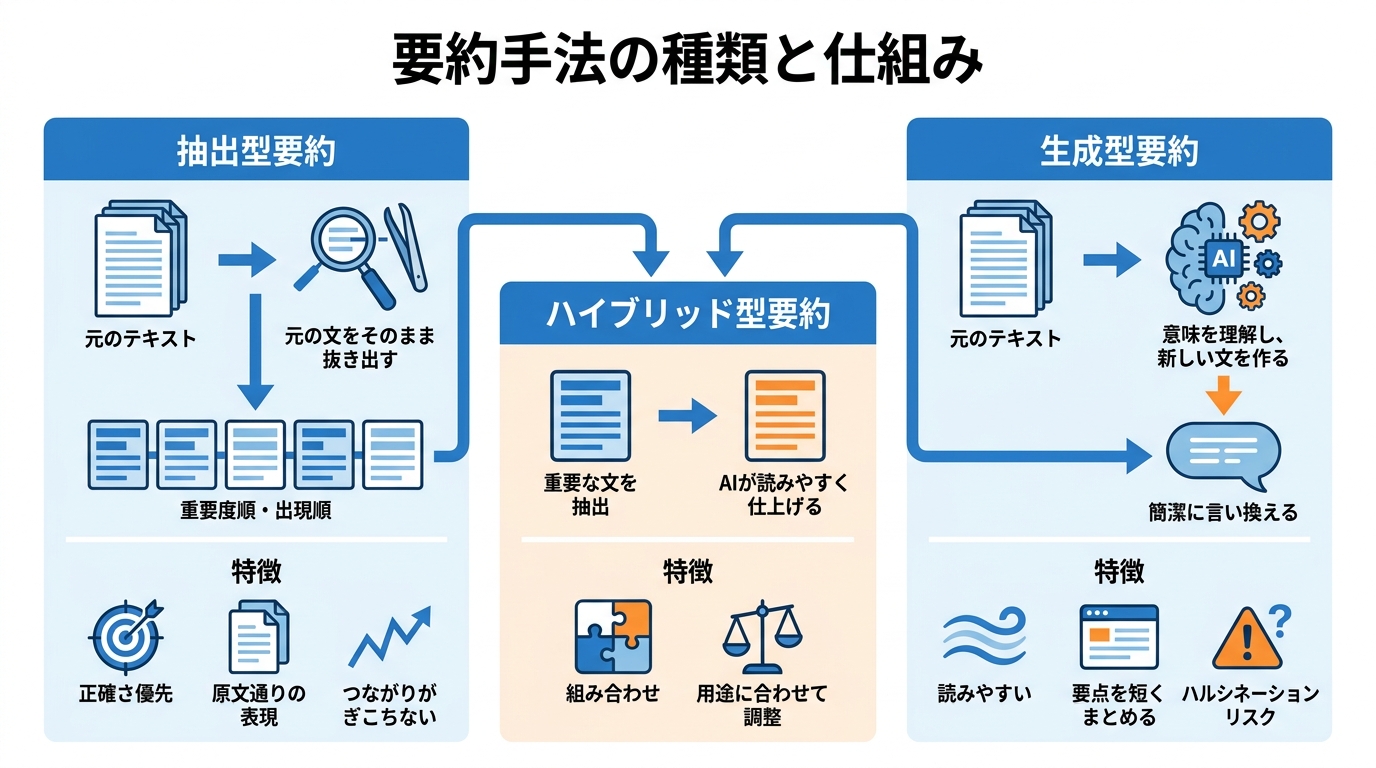
抽出型要約は、元のテキストからそのまま文を抜き出して要約を作る方法です。AIが新しい文を作るのではなく、すでにある文の中から「どの文が大事か」を判定して選び出します。
抽出された各文には重要度を示すスコアが付き、元の文章での出現順に並べるか、スコアの高い順に並べるかを選ぶことができます(参照*1)。法律文書やコンプライアンス報告書、医療記録のように、原文通りの表現が欠かせない場面で特に向いています。元の文をそのまま返すため、生成型と比べてハルシネーション(事実と異なる情報の出力)が起きにくいという利点もあります(参照*3)。
一方で、抜き出した文をつなげるだけなので、文と文のつながりがぎこちなくなる場合があります。読みやすさよりも正確さを最優先にしたいときに、抽出型は有力な選択肢となります。
生成型要約の特徴
生成型要約は、元のテキストの意味を理解したうえで、AIが自分の言葉で要約文を作り出す方法です。原文の文章をそのまま使うのではなく、内容を言い換えたり、複数の情報をまとめたりして、簡潔な文章を新たに生成します(参照*4)。
この方法は、顧客向けの報告書や経営層へのブリーフィングなど、文章の流れや読みやすさが重視される場面に適しています。原文の表現に縛られないため、要点を短くまとめやすいのが強みです(参照*3)。
ただし、AIが文章を新しく生成する以上、元のテキストにない情報が混ざるリスクが抽出型より高くなります。精度を確認する際も、単純な文の一致だけでは評価しきれないため、より高度な指標が求められます。
ハイブリッド型の活用
ハイブリッド型は、抽出型と生成型を組み合わせたやり方です。まず元のテキストから重要な文を抽出し、それをもとにAIが読みやすい文章へ仕上げるといった流れで使われます。ダッシュボード(情報を一覧表示する画面)や、複数の文書を横断して要約する場面に向いています(参照*3)。
ハイブリッド型は、モデルの組み合わせ方によってスコアが変わる可能性があります。抽出型のRandom Forestモデルと生成型のBARTモデルを組み合わせた研究では、ROUGEのR1が51.45(Random Forest単体)、32.78(BART単体)で、平均ROUGE F-measureが31.31(ハイブリッド)という結果が報告されています(参照*5)。
この結果からわかるのは、ハイブリッド型が常に高いスコアを出すわけではなく、モデルの組み合わせ方や対象テキストによって成果が変わるということです。自分の用途に合った組み合わせを実際に試して検証することが大切です。
主要モデル・ツールの比較
オープンソースモデルの選択肢
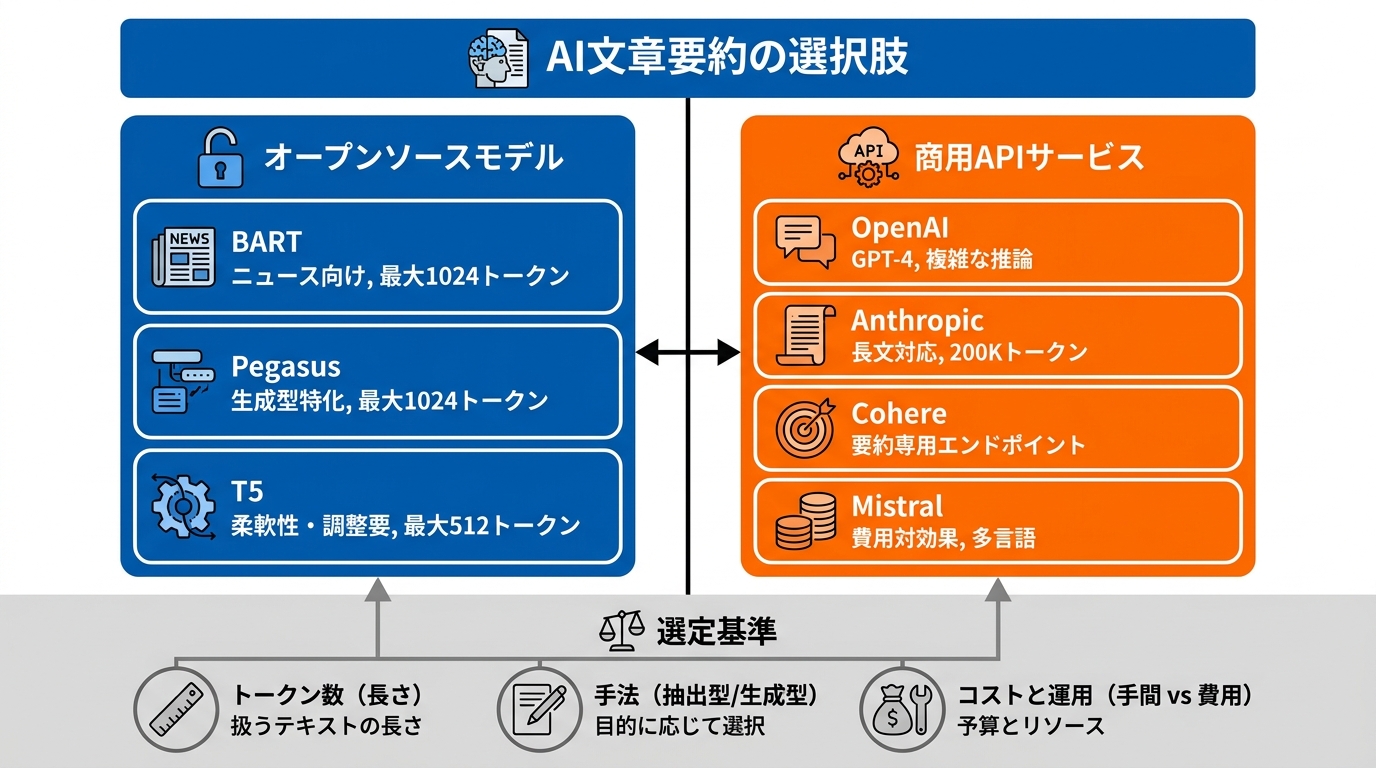
AI文章要約に使えるオープンソースモデルには、代表的なものがいくつかあります。特によく使われているのが、BART、Pegasus、T5の3つです。
BARTはCNN Daily Mailデータセットで学習されたモデルで、ニュース記事や一般的な文書の要約に強みがあります。2025年10月末時点で325万回以上ダウンロードされており、広く利用されています。Pegasusは生成型の要約に特化したモデルで、xsum版やCNN DailyMail版など複数のバリエーションがあります。T5はBARTより柔軟性が高い反面、調整の手間がかかります。ベースモデルは約900MBですが、smallバージョン(約250MB)は限られた計算資源でも動かしやすいのが特徴です(参照*4)。
処理できるトークン数にも違いがあります。t5-small、t5-base、t5-largeはいずれも最大512トークンで、BARTのbart-large-cnnとPegasusのpegasus-cnn_dailymailは最大1024トークンに対応しています(参照*6)。扱いたい文章の長さに合わせてモデルを選ぶのが基本です。
商用APIサービスの比較
自分でモデルを動かすのではなく、APIとして文章要約の機能を利用する方法もあります。商用のAPIサービスは、環境構築の手間を省きたい場合や、高い処理性能が必要な場合に適しています。
OpenAIはGPT-4およびGPT-3.5をChatCompletion APIで提供しており、プロンプトの工夫であらゆるスタイルの要約に対応できます。複雑な推論を含むタスクに強いのが特徴です。AnthropicのClaude 4 SonnetはAPIで利用でき、200Kトークンという大きなコンテキストウインドウを持つため、長い文書の処理に向いています。CohereのSummarizeは要約専用のエンドポイントを備えており、抽出型と生成型の両方のモードを選べます。Mistral APIは費用対効果が高く、多言語対応やGDPR準拠のインフラを備えた選択肢です(参照*4)。
各サービスには、対応する文書の長さ、得意な要約スタイル、コストの違いがあります。自分が扱う文書の種類や量、予算と照らし合わせて選ぶ必要があります。
選定時の判断基準
モデルやAPIを選ぶときには、いくつかの判断軸を持っておくと迷いにくくなります。まず確認したいのが、扱うテキストの長さと最大トークン数の関係です。オープンソースモデルでは512トークンから1024トークンまでの幅があり、長い文書にはトークン数の多いモデルか、商用APIのように大きなコンテキストウインドウを持つサービスが必要です。
次に、要約の目的に応じて手法を選びます。法律文書のように原文の正確さが求められるなら抽出型、社内報告のように読みやすさを優先するなら生成型が向いています。また、生成型の出力は単純な文の一致では評価しにくく、より高度な指標が求められます(参照*3)。
コストと運用の手間も見逃せません。オープンソースモデルは無料で使える一方、サーバーの用意やモデルの調整が必要です。商用APIは手軽に始められますが、呼び出し回数に応じた費用がかかります。どちらが自分の環境に合うかを、小さな規模で試してから判断するのが現実的です。
精度評価の指標と方法
ROUGE・BERTScoreなど自動指標
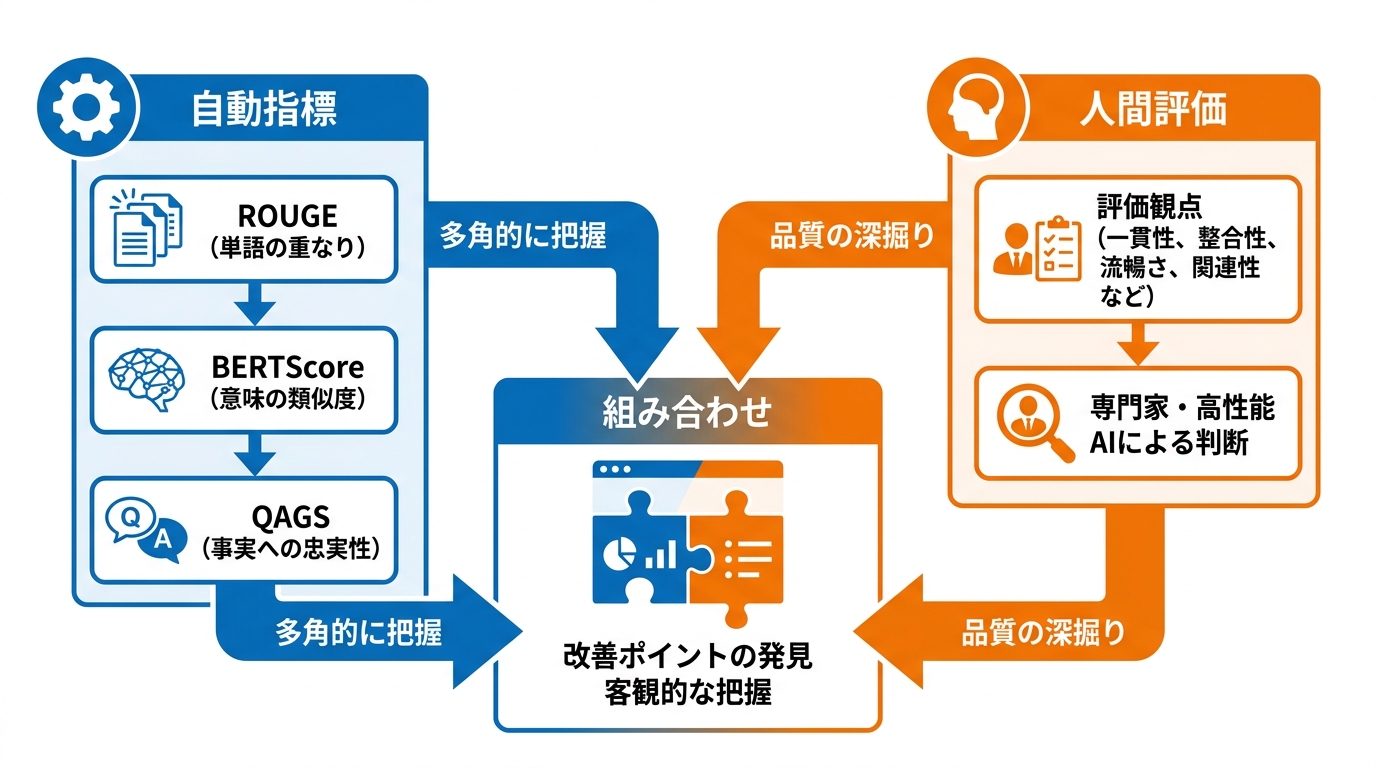
AI文章要約の精度を測るには、自動で計算できる指標がよく使われます。代表的なのが、ROUGE、BERTScore、QAGSの3つです。
ROUGEは、AIが生成した要約と正解の要約を比べて、共通する単語やフレーズの重なり具合を数値化する手法です。要約の評価では標準的なベースラインとして広く使われています。BERTScoreは単語の一致だけでなく、文脈を考慮した意味の類似度を比べるため、人間の判断とより高い相関を示します。さらに、QAGSのような質問応答ベースの手法は、要約が事実に忠実かどうかを測る指標として、同じ条件で比べたときにROUGEよりも事実性との相関が強いと報告されています(参照*3)。
自動指標はそれぞれ測れる範囲が異なります。単語の重なりを見るROUGE、意味の近さを捉えるBERTScore、事実との整合性を測るQAGSを組み合わせることで、要約の品質を多角的に把握しやすくなります。
人間評価との組み合わせ
自動指標だけでは捉えきれない品質を見るために、人間による評価も欠かせません。実際の運用では、自動指標と人間評価を組み合わせる方法が取られています。
医療分野の研究では、GPT-4-turboを評価者として使い、一貫性、整合性、流暢さ、関連性の4つの観点で要約を評価する手法が試みられました。この手法では、専門家の判断との一致率が平均83.06%に達しています(参照*2)。また、臨床での要約評価では、構成(診断・薬・指示のまとまり具合)、明瞭さ、正確さ、有用性(診察準備にどれだけ役立つか)の4軸で評価する方法も報告されています(参照*7)。
こうした事例から見えてくるのは、評価の観点を具体的に定めることで、人間の判断とAIの判断の差を客観的に把握できるということです。自動指標でまず大まかな品質を確認し、そのうえで人間や高性能なAIモデルによる評価を加えると、要約の改善ポイントが見つけやすくなります。
失敗例と注意点
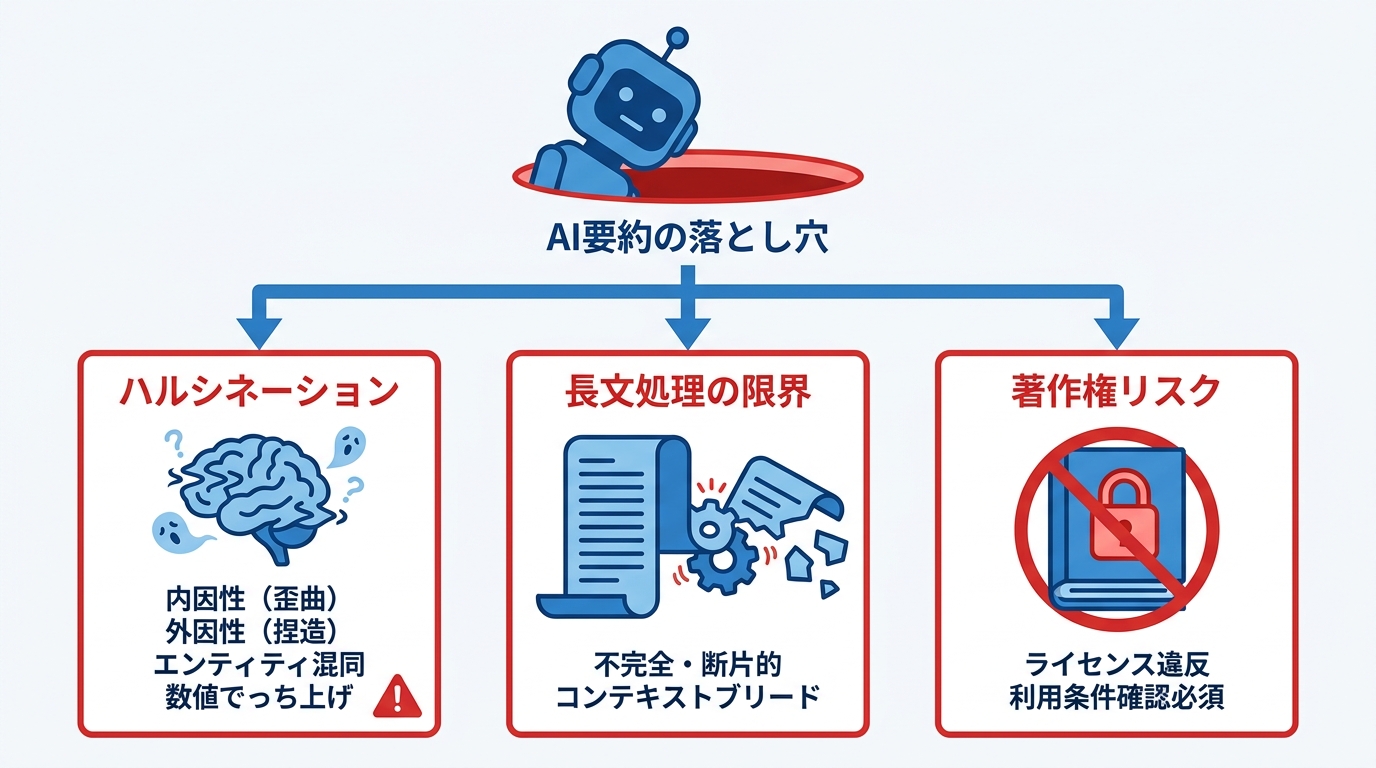
ハルシネーションの発生パターン
AI文章要約で最も気をつけたいのが、ハルシネーション(元のテキストにない情報をAIが作り出してしまう現象)です。これにはいくつかの典型的なパターンがあります。
ハルシネーションには、元の情報を歪める「内因性」と、無関係な情報を付け加える「外因性」の2種類があります。たとえば、原文に「2022年に発生した地震」と書かれているのに、要約では「2015年に発生した」と変わってしまうのが内因性のハルシネーションです。原文にない地震データを勝手に追加するのが外因性にあたります(参照*8)。
さらに、モデルが登場人物や組織の属性を取り違える「エンティティ混同」や、統計データを捏造する「数値のでっち上げ」も報告されています。長い文書を分割して処理するときには、前の部分の情報が次の部分に漏れ込む「コンテキストブリード」が起き、連鎖的に誤りが広がることもあります(参照*3)。こうしたパターンを事前に知っておくと、要約結果をチェックするときに見るべきポイントが明確になります。
長文処理と著作権の落とし穴
ハルシネーション以外にも、実務でつまずきやすいポイントがあります。1つは長文を処理するときの問題、もう1つは著作権に関する問題です。
コンテキストウインドウ(AIが一度に処理できるテキスト量の上限)を超える長い文書では、要約が不完全になったり断片的になったりします。モデルのスペック上は大きなコンテキストウインドウをうたっていても、その上限に近づくにつれて実際の性能が落ちることがあります(参照*4)。
著作権の面では、多くの出版社がChatGPTやMicrosoft Copilotのような外部のAIツールにコンテンツを共有することをライセンスで許可していません。大学の図書館が提供する研究論文なども、AIツールで要約することをライセンス上認めていないケースが多く、出版社のライセンスはフェアユース(公正利用)に優先するとされています(参照*9)。要約したいテキストの利用条件を事前に確認しておくことが、トラブルを防ぐうえで欠かせません。
領域別ユースケース
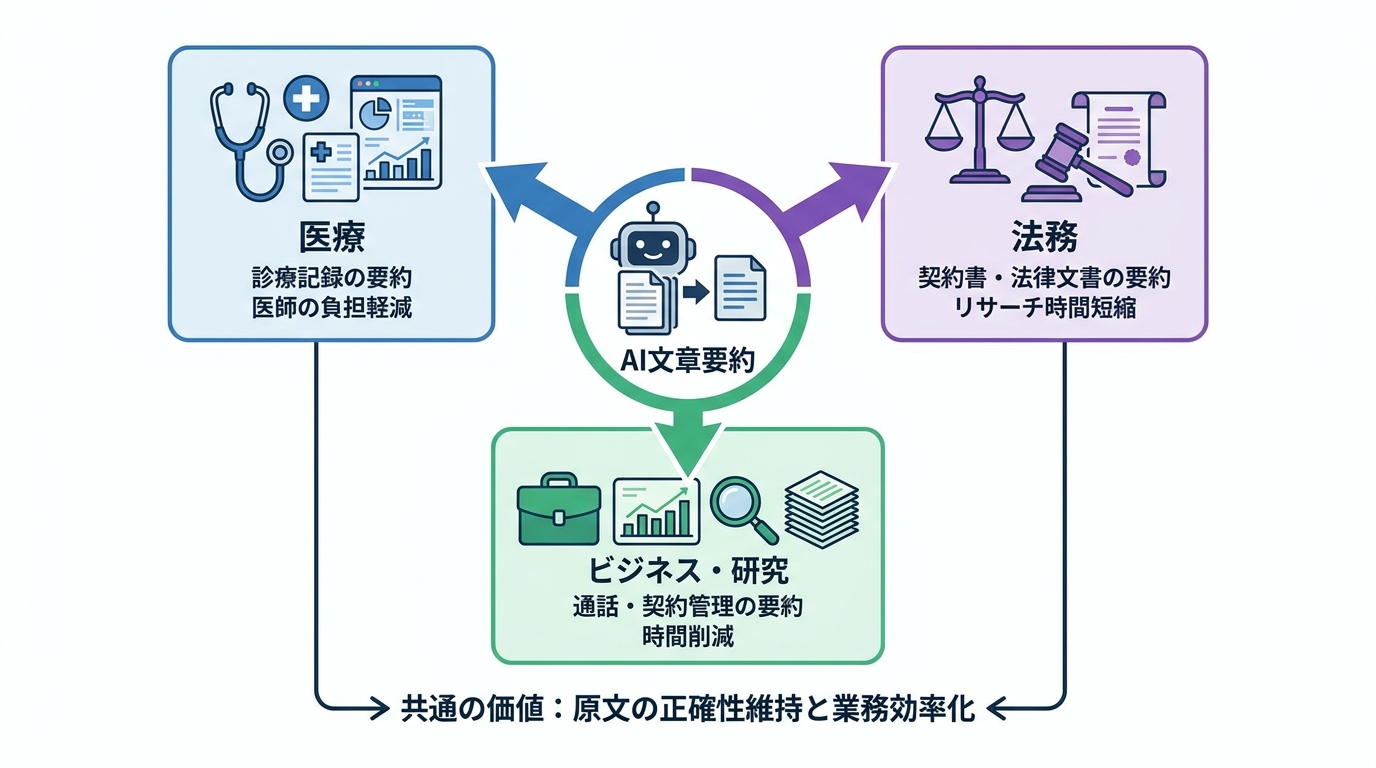
医療・法務での活用事例
AI文章要約は、情報量が膨大で正確さが求められる医療と法務の分野で活用が進んでいます。
医療の現場では、5人に1人の患者が約20万語もの診療記録を持っているとされ、その量は長編小説に匹敵します。大規模言語モデル(LLM)は、こうした膨大なメモや検査結果を要約し、医師の負担を減らす手段として注目されています(参照*7)。
法務の分野でも、契約書のレビューや訴訟準備、規制対応といった作業でAI文章要約が使われています。高度な自然言語処理を活用して法律文書を要約し、重要な情報を抽出することで、リサーチの時間を短縮しながら正確性を保つ運用が行われています(参照*10)。どちらの分野でも、原文の正確さを損なわないことが最優先の条件です。
ビジネス・研究での活用事例
医療や法務だけでなく、日常のビジネスや研究の場面でもAI文章要約は幅広く使われています。
保険業界の事例では、AIによる通話内容の要約で1件あたり約4分の短縮が実現し、年間56,000時間の削減につながりました(参照*3)。また、契約管理の分野では、AIが複数の文書を横断して質問に答えたり、契約ファイルの要約を自動で生成したりする機能が実際に業務に組み込まれています(参照*11)。
このように、文章要約のAIは特定の専門領域だけでなく、大量のテキストを扱うあらゆる業務で活用の余地があります。自分の業務でどんなテキストに時間を取られているかを洗い出してみると、導入の候補が見えてきます。
おわりに
AI文章要約は、抽出型と生成型の違いを理解し、用途に合ったモデルやAPIを選ぶことで、誰でも活用できる技術です。一方で、ハルシネーションや著作権の問題など、使う前に知っておくべき注意点も存在します。
まずは短い文章で試し、自動指標と目視の両方で結果を確認するところから始めてみてください。小さな実験を重ねることで、自分の業務に合った精度と使い方が見つかるはずです。
監修者
安達裕哉(あだち ゆうや)
デロイト トーマツ コンサルティングにて品質マネジメント、人事などの分野でコンサルティングに従事しその後、監査法人トーマツの中小企業向けコンサルティング部門の立ち上げに参画。大阪支社長、東京支社長を歴任したのち2013年5月にwebマーケティング、コンテンツ制作を行う「ティネクト株式会社」を設立。ビジネスメディア「Books&Apps」を運営。
2023年7月に生成AIコンサルティング、およびAIメディア運営を行う「ワークワンダース株式会社」を設立。ICJ2号ファンドによる調達を実施(1.3億円)。
著書「頭のいい人が話す前に考えていること」 が、82万部(2025年3月時点)を売り上げる。
(“2023年・2024年上半期に日本で一番売れたビジネス書”(トーハン調べ/日販調べ))
参照
- (*1) Docs – What is summarization?
- (*2) PubMed Central (PMC) – A Multiagent Summarization and Auto-Evaluation Framework for Medical Text: Development and Evaluation Study
- (*3) Galileo AI – Master LLM Summarization Strategies and their Implementations
- (*4) Complete Guide to Summarization APIs & SDKs (2026)
- (*5) Text summarization: BART, RF, and hybrid BART-RF algorithm comparison
- (*6) GitHub – GitHub – pyenthusiasts/AI-Text-Summarizer · GitHub
- (*7) CU Researcher Introducing a New Standard for Evaluating AI in Clinical Summarization
- (*8) Smallpdf – AI Text Summarization Challenges & How to Solve Them
- (*9) Summarizing with Generative AI
- (*10) Claude Platform Docs – Legal summarization
- (*11) Using AI Features
