
はじめに
会議のたびに録音データを聞き返し、手作業で議事録を仕上げるのは大きな時間の負担です。ChatGPTを使った文字起こしと議事録変換を組み合わせれば、この作業を大幅に短縮できますが、プロンプトの書き方しだいで精度や出力の質が変わります。
この記事では、文字起こしの精度を高めるプロンプトの設計から、議事録変換や後処理の実践的な手順までを解説します。
ChatGPT文字起こしの仕組み
対応モデルと入出力形式
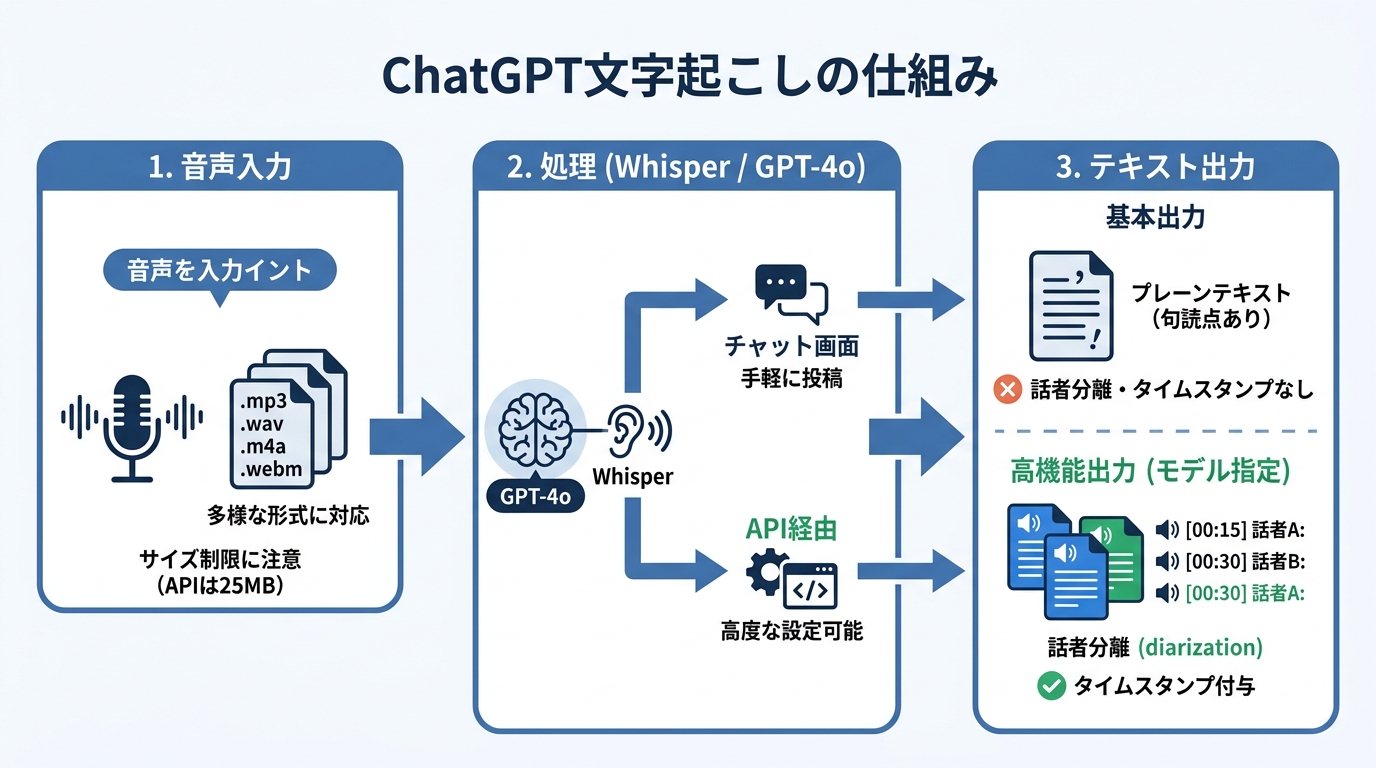
ChatGPTの文字起こしは、音声ファイルをアップロードするとWhisperで処理され、全文テキストとして返される仕組みです。有料プランでGPT-4oを利用している場合、.mp3、.wav、.m4a、.webmなどの形式に対応しており、チャット画面にファイルを投入するだけで文字起こしが完了します(参照*1)。
API経由で利用する場合も、対応するファイル形式はmp3、mp4、mpeg、mpga、m4a、wav、webmで、アップロードの上限は25MBです(参照*2)。つまり、一般的な会議録音であれば多くの形式がそのまま利用できますが、長時間の録音はファイルサイズに注意して分割する必要があります。
出力はプレーンテキストの書き起こしが基本であり、句読点が付いた読みやすいテキストが得られます。一方で、タイムスタンプや話者ラベルは付かないため、そのまま議事録として使うにはプロンプトを活用した後処理が欠かせません。
話者分離と高精度モデル
複数の参加者がいる会議では、「誰が何を発言したか」を区別できるかどうかが議事録の質を左右します。APIで利用できるgpt-4o-transcribe-diarizeモデルは、話者ごとに分離した書き起こしを生成できます。レスポンス形式にdiarized_jsonを指定すると、各セグメントに話者名・開始時刻・終了時刻のメタデータが付与されます(参照*2)。
このモデルでは、入力が30秒を超える場合にchunking_strategyの設定が必須となり、”auto”または音声区間検出の構成を指定して音声を分割します。会議のように長い音声を扱う場合、この設定が話者分離の精度に直結します。
通常のChatGPTチャット画面からの文字起こしでは話者の分離やタイムスタンプは付きません。そのため、話者ごとの発言管理が必要な議事録では、API経由での話者分離モデルの活用を検討する価値があります。
文字起こし精度を上げるプロンプト
専門用語・固有名詞の補正
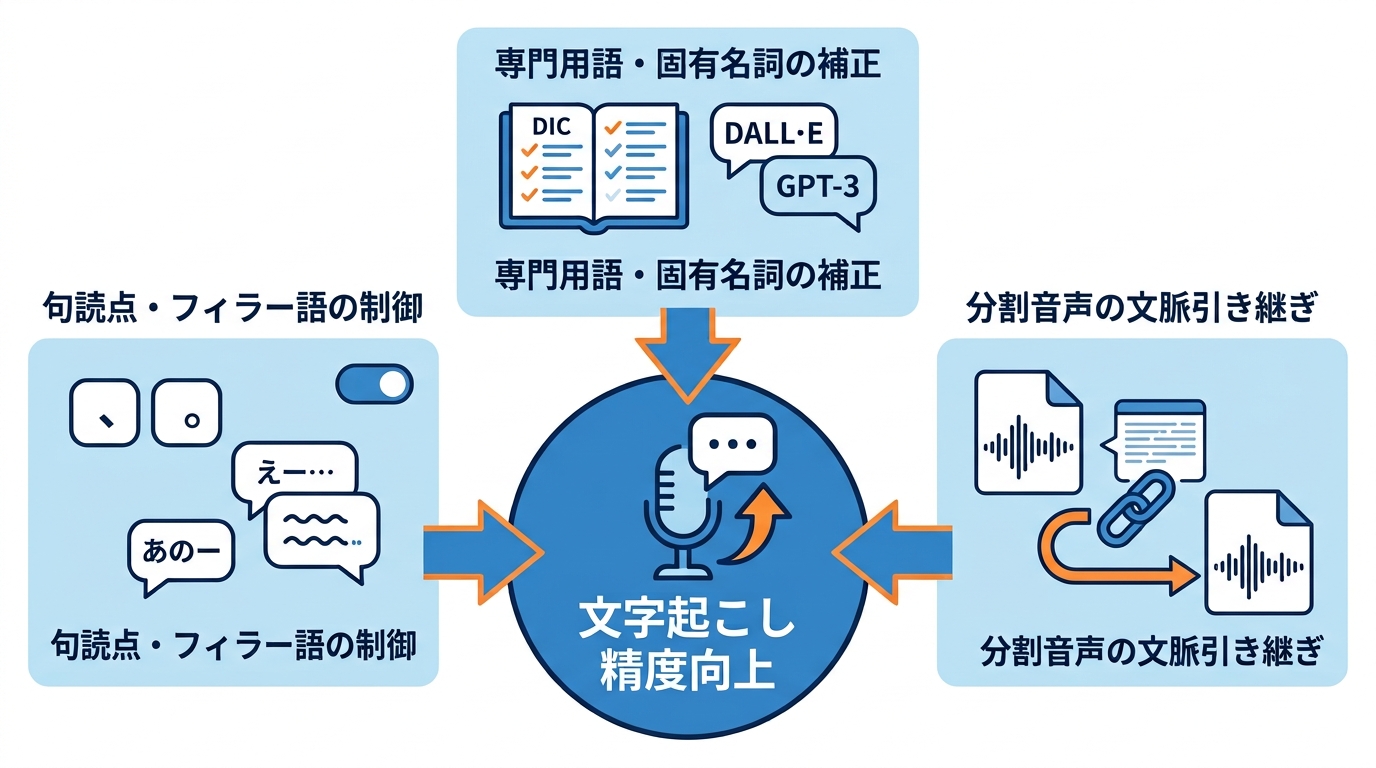
文字起こしモデルは、音声だけでは判断しにくい専門用語や固有名詞を誤認識することがあります。プロンプトに正しい表記をあらかじめ含めておくと、認識精度が向上します。たとえば公式ガイドでは、”DALL·E”が”DALI”、”GPT-3″が”GDP 3″と誤認識された事例に対し、プロンプトへ次のように記述する方法が示されています。”The transcript is about OpenAI which makes technology like DALL·E, GPT-3, and ChatGPT with the hope of one day building an AGI system that benefits all of humanity.”(参照*2)
会議の文字起こしでも同様に、社内用語や製品名をプロンプトに列挙しておくと、Whisperがそれらの単語をより正確に認識・表記できるようになります(参照*3)。頻出する略語やプロジェクト名をプロンプトの冒頭にまとめて記載しておくと、修正の手間を減らせます。
句読点・フィラー語の制御
文字起こし結果で句読点が抜け落ちると、後から読みにくいテキストになります。モデルが句読点を省略する場合は、句読点を含むシンプルなプロンプトを与えると改善できます。公式ガイドでは”Hello, welcome to my lecture.”のような例文をプロンプトに設定する方法が紹介されています(参照*2)。
フィラー語とは「えー」「あのー」のような、話し言葉で発せられるつなぎ言葉のことです。モデルはこれらを省略することがありますが、発言のニュアンスを残したい場合はフィラー語を含むプロンプトが有効です。公式ガイドの例では”Umm, let me think like, hmm… Okay, here’s what I’m, like, thinking.”という文をプロンプトに含めています。議事録用途ではフィラー語を除去したほうが読みやすいため、目的に応じてプロンプトの有無を使い分けるのがポイントです。
分割音声の文脈引き継ぎ
長時間の会議録音をファイルサイズの上限に合わせて分割した場合、分割点で文脈が途切れて誤認識が起きやすくなります。これを防ぐには、前のセグメントの書き起こしテキストを次のセグメントのプロンプトに渡す方法が有効です。公式ガイドでは、モデルが前の音声から関連情報を取得し、書き起こしの精度が向上すると説明されています(参照*2)。
ただし、whisper-1モデルではプロンプトの末尾224トークンだけが参照され、それ以前の内容は無視されます。そのため、前のセグメントの全文を渡すのではなく、末尾の数文だけをプロンプトに含めるのが効率的です。分割が多いほどこの手順の重要度が上がるため、プロンプトへの引き継ぎを自動化するスクリプトを用意しておくと作業がスムーズになります。
議事録変換プロンプトの実践例
基本の要約プロンプト
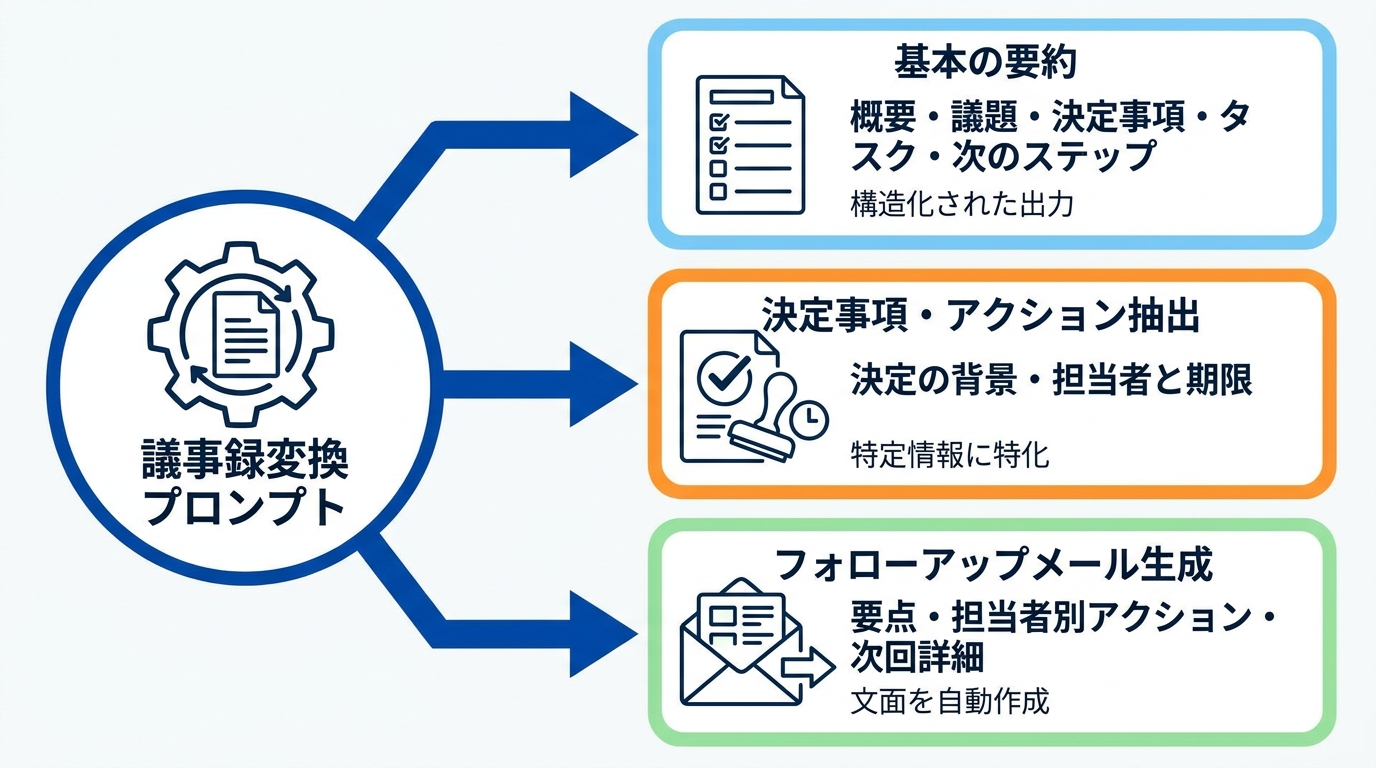
文字起こしテキストが手に入ったら、次はそれを議事録として整形するプロンプトの出番です。会議の要約を依頼するプロンプトでは、出力に含めたい項目をあらかじめ指定するのが効果的です。実践例として、次のようなプロンプトが挙げられます。”Generate professional meeting minutes from this transcript. Include: 1) Meeting overview, 2) Key topics discussed, 3) Decisions made, 4) Action items with responsible parties, 5) Next steps and deadlines.”(参照*4)
このプロンプトは、概要・議題・決定事項・担当付きのタスク・次のステップと期限という5つの構成要素を指定しているため、出力が構造化されやすくなります。会議の要約では、項目ごとに分けた出力を得ることで、手作業での並べ替えや整理の時間を省けます。チームの議事録テンプレートに合わせて項目名を日本語に変えると、さらに実務で使いやすくなります。
決定事項・アクション抽出
会議で最も見落とされやすい情報は、「何が決まったか」と「誰が何をするか」です。これらだけを抜き出すプロンプトを別途用意しておくと、確認漏れを防げます。決定事項の抽出に特化したプロンプトの例として、次の文面があります。”Review this meeting transcript and extract all key decisions that were made. For each decision, include the context of why it was made and any relevant discussion points.”(参照*4)
このプロンプトは、決定の背景と関連する議論のポイントまでセットで出力させる設計です。会議の要約プロンプトとは別に、担当者と期限付きのアクション項目だけを抽出するプロンプトを組み合わせると、1つの会議録音から目的別の文書を効率よく生成できます。
フォローアップメール生成
議事録の作成と並行して求められるのが、会議後のフォローアップメールです。ChatGPTに文字起こしテキストを渡しつつ、メール生成に適したプロンプトを使えば、この作業も自動化できます。実践例として、次のプロンプトが挙げられます。”Based on this meeting transcript, write a follow-up email summarizing the meeting. Include key takeaways, action points assigned to each person, and next meeting details. Keep the tone professional but conversational.”(参照*4)
このプロンプトでは、要点の要約・担当者ごとのアクション項目・次回会議の詳細という3要素をメールに含めるよう指示しています。さらにトーンを”professional but conversational”と指定することで、堅すぎず読みやすい文面が得られます。プロンプトの中でトーンや言語を指定する一文を加えるだけで、英語・日本語を問わず出力の雰囲気を調整できるのがChatGPT活用の利点です。
GPT後処理による品質向上
システムプロンプトでの誤字修正
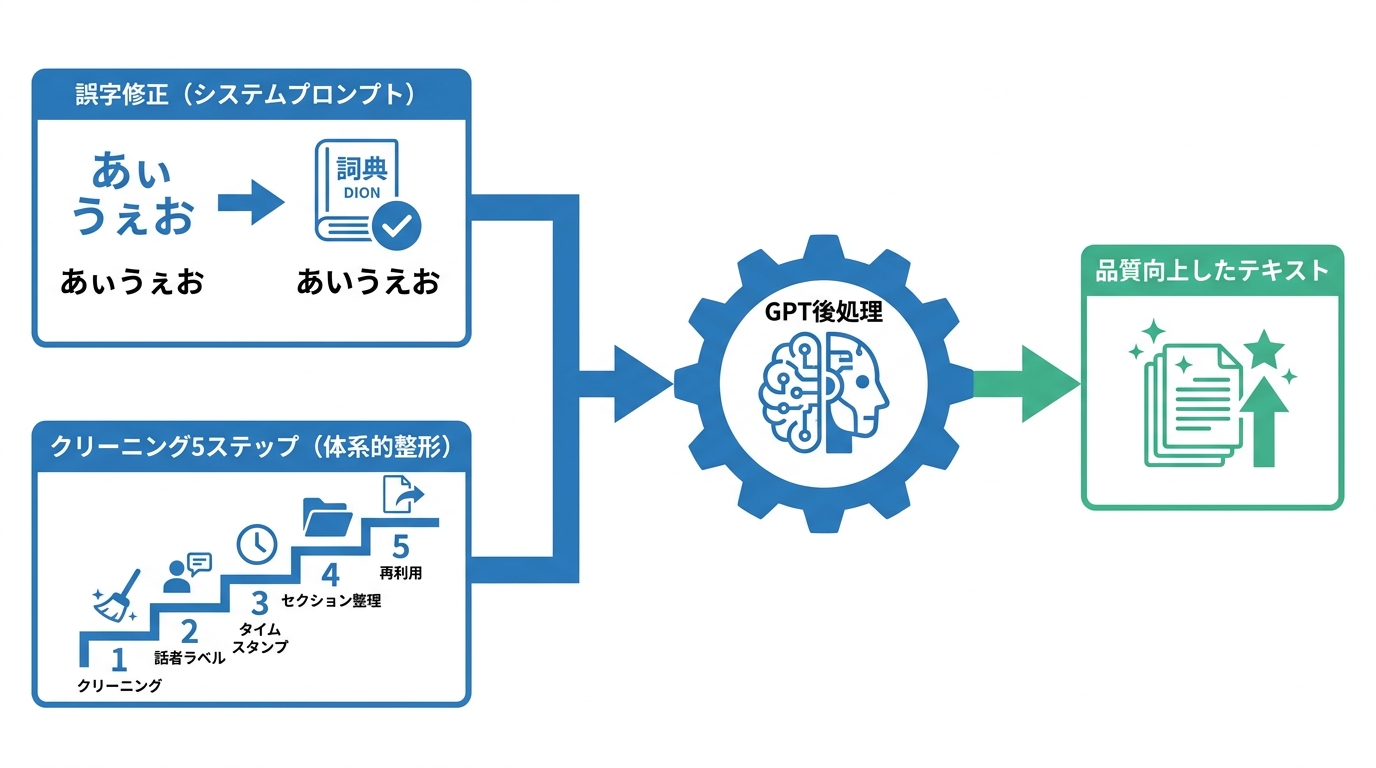
文字起こし段階のプロンプトだけでは補正しきれない誤字や表記ゆれは、GPT-4による後処理で修正できます。公式ガイドでは、system_prompt変数にあらかじめ社名や製品名を定義し、GPT-4に書き起こしテキストを渡す方法が紹介されています(参照*2)。
この後処理をかけると、GPT-4が書き起こし中の多くのスペルミスを修正します。GPT-4はWhisperよりも大きなコンテキストウィンドウを持つため、長い書き起こしテキストにもスケールしやすく、指示に従った修正が可能であるという点でWhisperのプロンプトパラメータよりも信頼性が高いとされています(参照*2)。
したがって、文字起こし時のプロンプトで大まかな精度を確保し、仕上げにGPT-4の後処理を通すという2段階の運用が、品質と効率のバランスを取りやすい方法といえます。
クリーニングと整形の5ステップ
書き起こしテキストを議事録として仕上げるまでには、体系的なクリーニングの手順を踏むと品質が安定します。実務で使われている後処理の工程は次の5段階です(参照*5)。
- クリーニング: フィラー語の除去と文法の修正。省略してはならない工程です。
- 話者ラベル付け: “Speaker A”のような仮ラベルを実名に置き換えます。話者が1人の場合は省略可能です。
- タイムスタンプの最適化: 用途に合わせてタイムスタンプの形式を整えます。読むだけの用途では省略できます。
- セクション整理: 見出しを追加し、内容を構造化します。短い書き起こしでは省略可能です。
- 再利用: ブログ記事や要約、メモなど他の形式に変換します。書き起こしが最終成果物の場合は不要です。
クリーニングのプロンプトでは、フィラー語の除去、言い直しの整理、繰り返しの圧縮、不完全な文の補完といったルールを明示し、技術用語はそのまま保持して事実関係を省略しないよう指示することが推奨されています(参照*5)。
専用ツールとの比較・使い分け
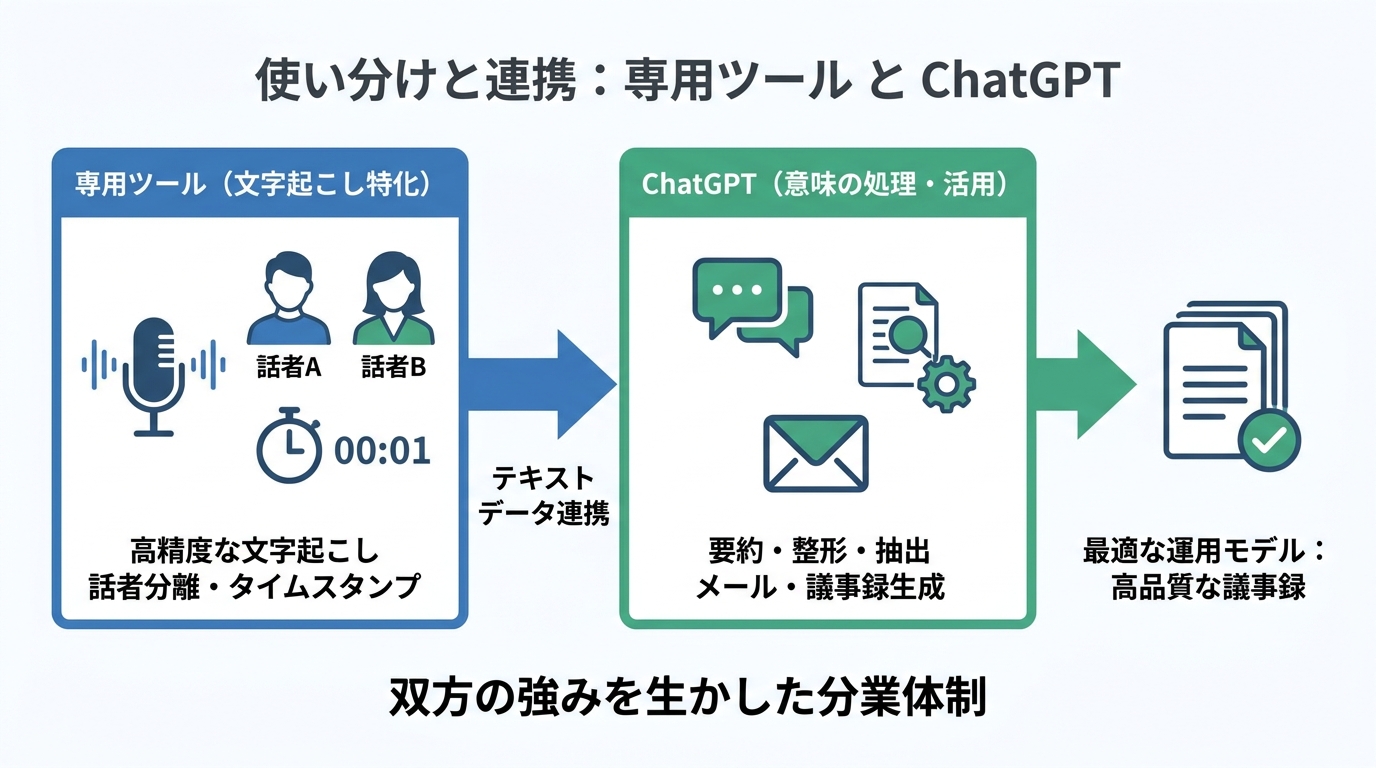
ChatGPTの得意・不得意
ChatGPTの文字起こしは、音声ファイルをアップロードするだけで句読点付きの読みやすいテキストが得られる手軽さが強みです。しかし、出力にはタイムスタンプや話者ラベルが含まれないため、公開用の書き起こしやインタビュー記事にはそのまま使いにくいという面があります(参照*1)。
加えて、チャット画面の機能としては、リアルタイムの文字起こし、複数話者の自動分離、バッチ処理による一括変換には対応していません(参照*1)。また、ChatGPT自体は会議を録音したり、書き起こしを単独で生成したりする機能を持っていないため、音声データは別のツールであらかじめ用意する必要があります(参照*4)。こうした制約を理解したうえで、プロンプトによる要約・整形という後工程に活用するのがChatGPTの効果的な使い方です。
専用ツール併用の判断基準
専用の文字起こしツールは、複数の入出力形式への対応、複数話者の追跡、編集しやすいエディタなど、会議録音の管理に特化した機能を備えています(参照*3)。話者分離やタイムスタンプが必須の場面、あるいは大量の録音を定常的に処理する運用では、専用ツールを文字起こしの工程に使うほうが効率的です。
一方、テキスト化した後の要約・決定事項の抽出・メール生成といった「意味を扱う作業」はChatGPTのプロンプトが得意とする領域です。したがって、専用ツールで高精度な書き起こしを行い、その出力をChatGPTに渡して議事録に仕上げるという分業体制が、双方の強みを生かした運用モデルになります。
よくある失敗と注意点
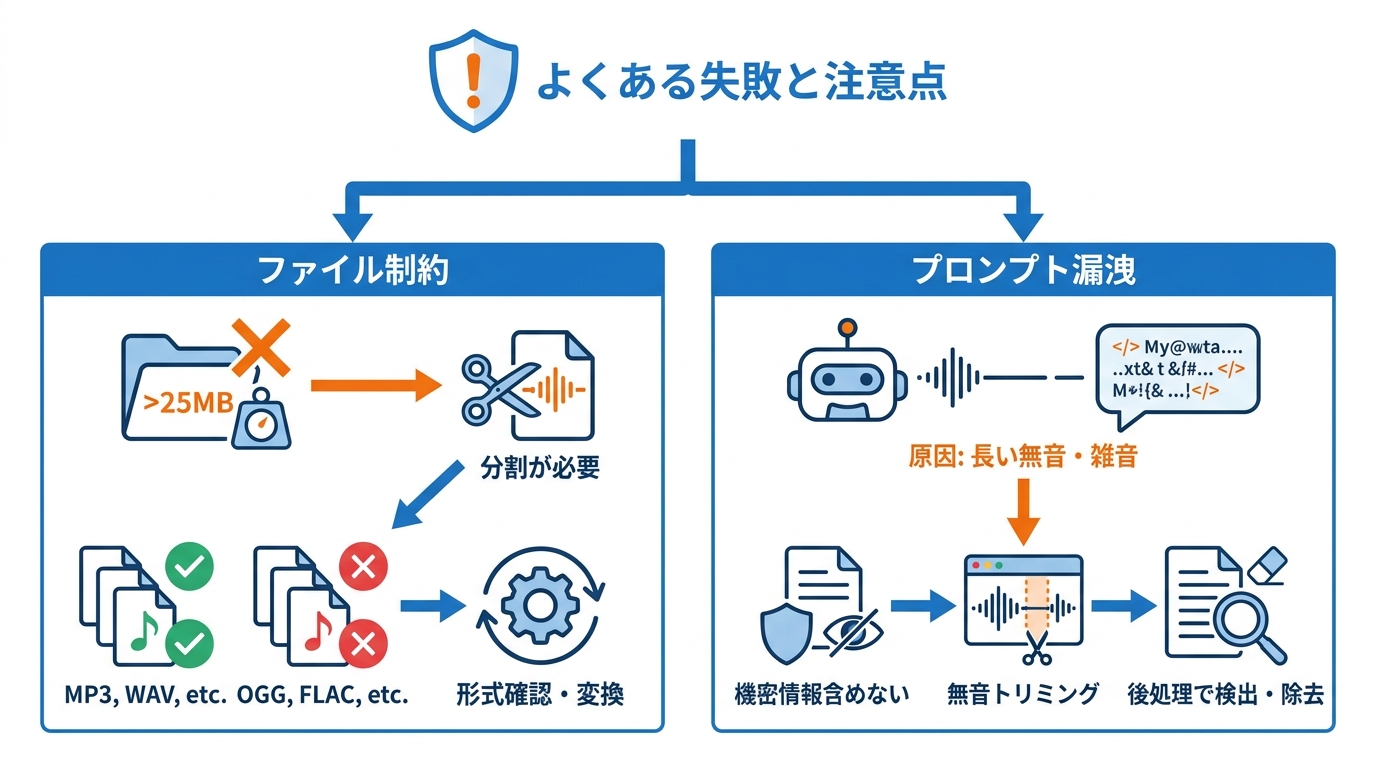
ファイルサイズと形式の制約
ChatGPTやWhisper APIで文字起こしを行う際に最も多い失敗は、ファイルサイズの上限を超えたまま音声をアップロードしようとすることです。Whisper APIでは各音声ファイルの上限が25MBに制限されており、これを超える録音は分割が必要です(参照*3)。
対応ファイル形式はmp3、mp4、mpeg、mpga、m4a、wav、webmの7種類です(参照*2)。録音ソフトによっては.oggや.flacなど非対応の形式で保存されることがあるため、アップロード前に形式を確認し、必要に応じて変換しておくと無駄な手戻りを避けられます。分割時には前述の「文脈引き継ぎプロンプト」を活用して、セグメント間の精度低下を防ぐことも忘れないようにしたいところです。
プロンプト漏洩・誤認識の対策
文字起こしモデルの特有の問題として、プロンプトの内容が書き起こし結果に混入する「プロンプト漏洩」があります。ユーザー報告によると、この現象は音声中に長い無音区間と背景雑音がある場合や、発話以外のランダムな音が含まれる場合に起きやすい傾向があります(参照*6)。
具体的には、モデルがシステムプロンプトや開発者プロンプトの末尾の文をそのまま出力してしまうことがあります。この出力は音声入力とは一致せず、プロンプトの内部情報がテキストに漏れ出す形になります(参照*6)。対策としては、プロンプトに機密情報を含めないこと、書き起こし後にGPT-4の後処理で不自然な文を検出・除去すること、そして無音区間の多い録音は事前にトリミングしておくことが有効です。
おわりに
ChatGPTによる文字起こしは、プロンプトの設計次第で精度が大きく変わります。専門用語の補正、句読点やフィラー語の制御、分割音声の文脈引き継ぎといったテクニックを組み合わせることで、後処理の手間を減らしながら実用的な議事録を効率よく作成できます。
文字起こしの工程と議事録変換の工程それぞれに適したプロンプトを用意し、必要に応じて専用ツールと組み合わせる運用を整えてみてください。
監修者
安達裕哉(あだち ゆうや)
デロイト トーマツ コンサルティングにて品質マネジメント、人事などの分野でコンサルティングに従事しその後、監査法人トーマツの中小企業向けコンサルティング部門の立ち上げに参画。大阪支社長、東京支社長を歴任したのち2013年5月にwebマーケティング、コンテンツ制作を行う「ティネクト株式会社」を設立。ビジネスメディア「Books&Apps」を運営。
2023年7月に生成AIコンサルティング、およびAIメディア運営を行う「ワークワンダース株式会社」を設立。ICJ2号ファンドによる調達を実施(1.3億円)。
著書「頭のいい人が話す前に考えていること」 が、82万部(2025年3月時点)を売り上げる。
(“2023年・2024年上半期に日本で一番売れたビジネス書”(トーハン調べ/日販調べ))
参照
- (*1) Maestra AI – Can ChatGPT Transcribe Audio? (with Prompts and an Alternative)
- (*2) Speech to text | OpenAI API
- (*3) Sonix – How to Use ChatGPT for Meeting Notes
- (*4) ChatGPT Meeting Minutes Generator
- (*5) How to Clean a Transcript: 5 AI Prompts (2026)
- (*6) OpenAI Developer Community – Transcription model gpt-4o-mini-transcribe prompt leakage
