
はじめに
近年、AI技術の進歩により、ChatGPTなどの対話型AIを日常生活やビジネスで利用する機会が急速に増えています。こうしたテクノロジーは文章作成や学習支援、業務効率化など幅広い場面で活用される一方、利用者から個人情報がやりとりされるリスクも指摘されています。
本記事ではChatGPTを例に、個人情報がどのように扱われるのか、そして利用者が直面しうるリスクや具体的な対策について解説します。安全に活用するためのポイントを押さえ、デジタル社会におけるプライバシー保護について改めて考えてみましょう。
ChatGPTで扱われる個人情報の種類と仕組み
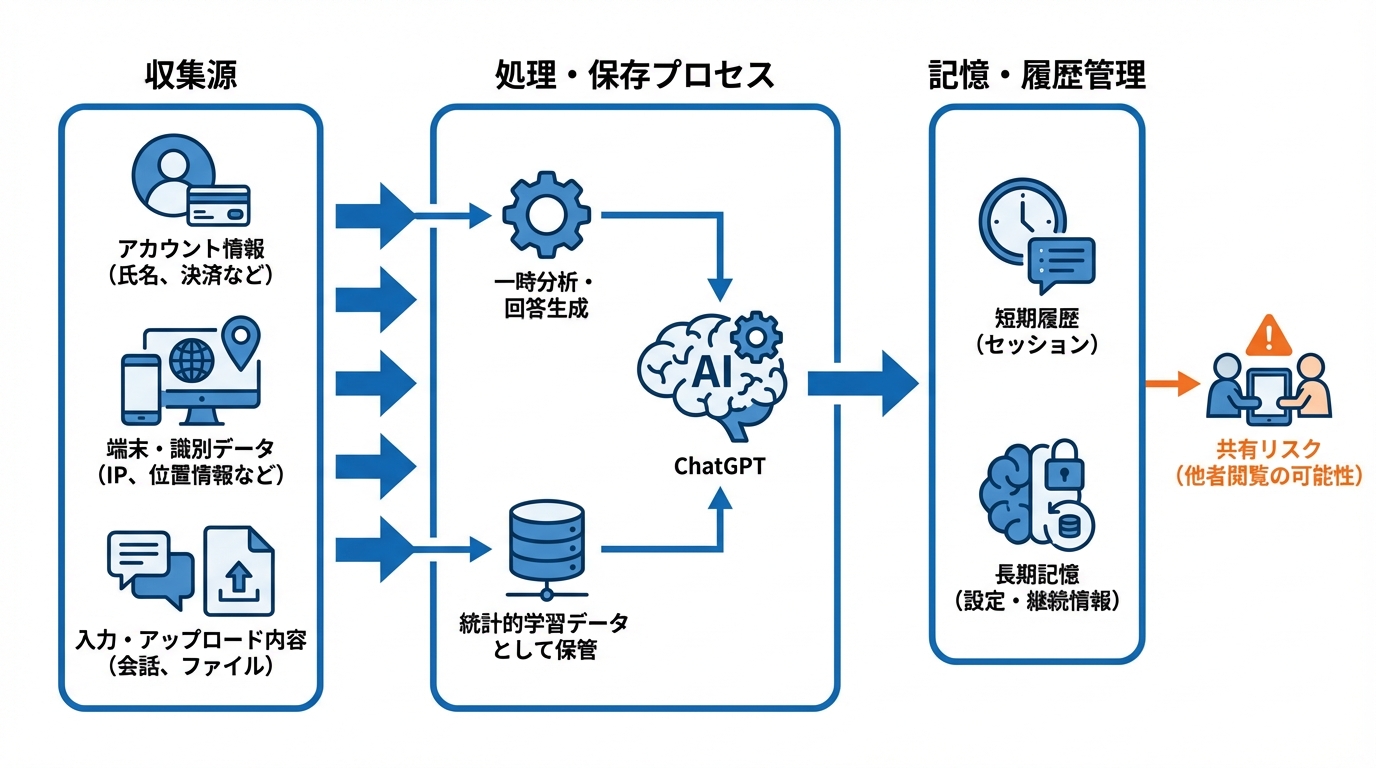
ChatGPTのデータ収集源
ChatGPTが扱う個人情報の主な出どころは、ユーザーがアカウント作成時や有料版の支払い手続きで入力するデータです。具体的には氏名、連絡先、決済カード情報などが含まれ、サービス提供や本人認証のために利用されます(参照*1)。
また、利用端末のIPアドレスや位置情報、ブラウザの利用状況といった識別データも収集されます。さらに、チャットへの書き込み内容やファイルのアップロード情報はAIの回答精度向上や運営側のサービス改善に活用されます。これらのデータはベンダー企業や法令遵守のための機関とも共有されるため、取り扱い範囲が広いことを理解しておく必要があります。
モデル学習と保存データの違い
ChatGPTの学習過程と実際の保存データは必ずしも同じではありません。ユーザーが入力やアップロードを行うと、AIが一時的にそのデータを分析し、回答生成に用いることがあります。たとえばコードインタプリタが起動されると、PDFなどの文書から隠れたメタデータやリビジョン履歴まで抽出される可能性があります(参照*2)。
一方、学習データとして反映される情報は一般に統計的な形で保管され、個別のやりとりを直接的に参照する形で保存しているわけではありません。ただし、運営側のデータ処理方針は変更されることがあるため、利用者は機密性の高い情報を提出する前にプライバシーポリシーをこまめに確認することが重要です。
ChatGPTの記憶機能と履歴管理
ChatGPTには短期的な履歴と長期の記憶機能が存在します。特定のキーワードや継続的に使い続ける情報を覚えさせる指示をすると、別のチャットでも引き継がれる場合があります(参照*3)。たとえば、共用端末や友人のデバイスで会話をした後に履歴を削除しても、長期記憶データが残っていると、そのキーワードについて問われた際に以前の内容が再現されることがあります。
このような仕組みは利便性を高める一方、プライバシーリスクも伴います。意図せず個人的な情報を他者に見られてしまう恐れがあり、とりわけ他者が同じ端末でChatGPTを操作する場合には注意が必要です。履歴や記憶機能の存在を理解し、重要な会話が外部に漏れないよう配慮することがポイントです。
どんなリスクがあるのか:漏洩・悪用・脆弱性
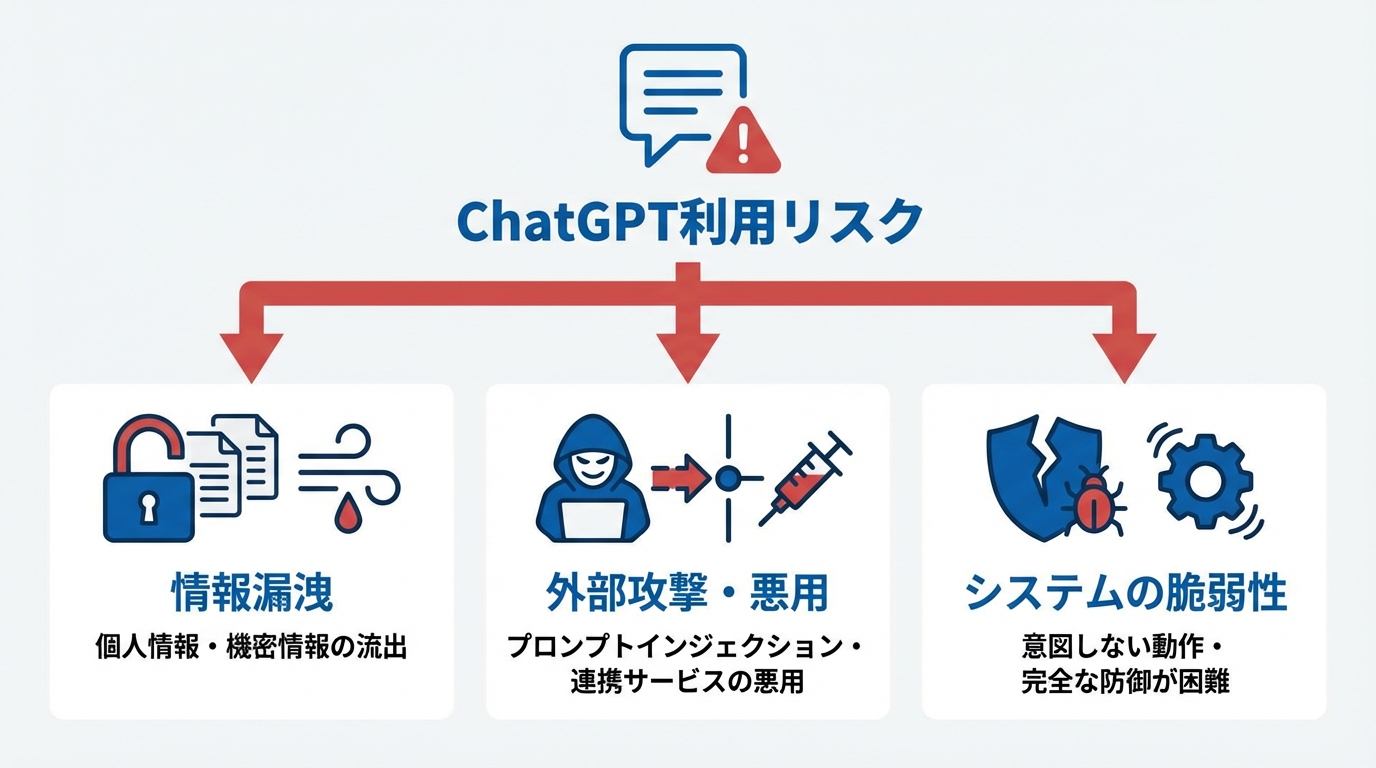
入力情報からの漏洩リスク
ChatGPTへの入力情報から生じる最大の懸念は、個人情報が第三者へ流出する可能性です。公的機関では個人情報保護規定への違反が重大な問題となるため、特に注意が必要です。ビクトリア州の規定では、職員が公開型生成AIに個人情報を入力してはならないと明記されており、違反は法的なリスクを伴います(参照*4)。
また、企業の内部メモなどでは、従業員がChatGPTに財務情報や個人データを誤って入力し、社外への機密漏洩につながった事例も報告されています。Appleやサムスンなどが特定部署での使用を制限する背景には、こうしたリスクが存在します。機密情報が含まれる素材をそのまま送信すると、不正アクセスやサイバー攻撃に対する脆弱性が高まることを理解しておく必要があります(参照*5)。
間接的プロンプトインジェクションと連携サービスのリスク
ユーザーが意図しなくても、不特定の情報を入力するだけで悪意ある第三者に利用される恐れがあります。特に、外部から仕込まれた文書に含まれる隠れた指令が、チャットボットの応答を意図した方向へ誘導する「間接的プロンプトインジェクション」と呼ばれる攻撃手法が注目されています。こうした攻撃によって、機密情報が会話の一部として引き出される危険性が指摘されています(参照*6)。
たとえば、Google DriveやGmailとChatGPTが連携可能な環境下では、AIがクラウド上のファイルに幅広くアクセスし、利用者の知らないうちに個人情報を抜き取る可能性もあるとセキュリティ研究者は示唆しています。研究者らは、この手法が実際に成功すると、ユーザーのドキュメントから高感度な情報を無断で抽出できるため、データ保護上の大きな脆弱性になると警鐘を鳴らしています(参照*7)。
ビジネス利用における企業データリスク
ビジネス利用の場合、企業内のチャット履歴や特定業務データが流出すると、多くの顧客情報や知的財産が危険にさらされます。サイバーセキュリティ研究では、ChatGPTが抱える新たな脆弱性がGPT-4oやGPT-5にも影響を与えると報告されており、一部は修正済みでも完全な防御には至っていません(参照*8)。
問題となるのは、ユーザーが知らないうちに意図しない動作をAIが行う環境です。攻撃者が組織のシステムへ侵入しなくても、従業員がChatGPTを通じてデータをやりとりする中で外部へ情報が漏れるケースがあります。こうしたリスクを踏まえ、利用ルールやセキュリティ教育を強化する企業が増えています。
公開版ChatGPTとエンタープライズ版の違いと組織ポリシー
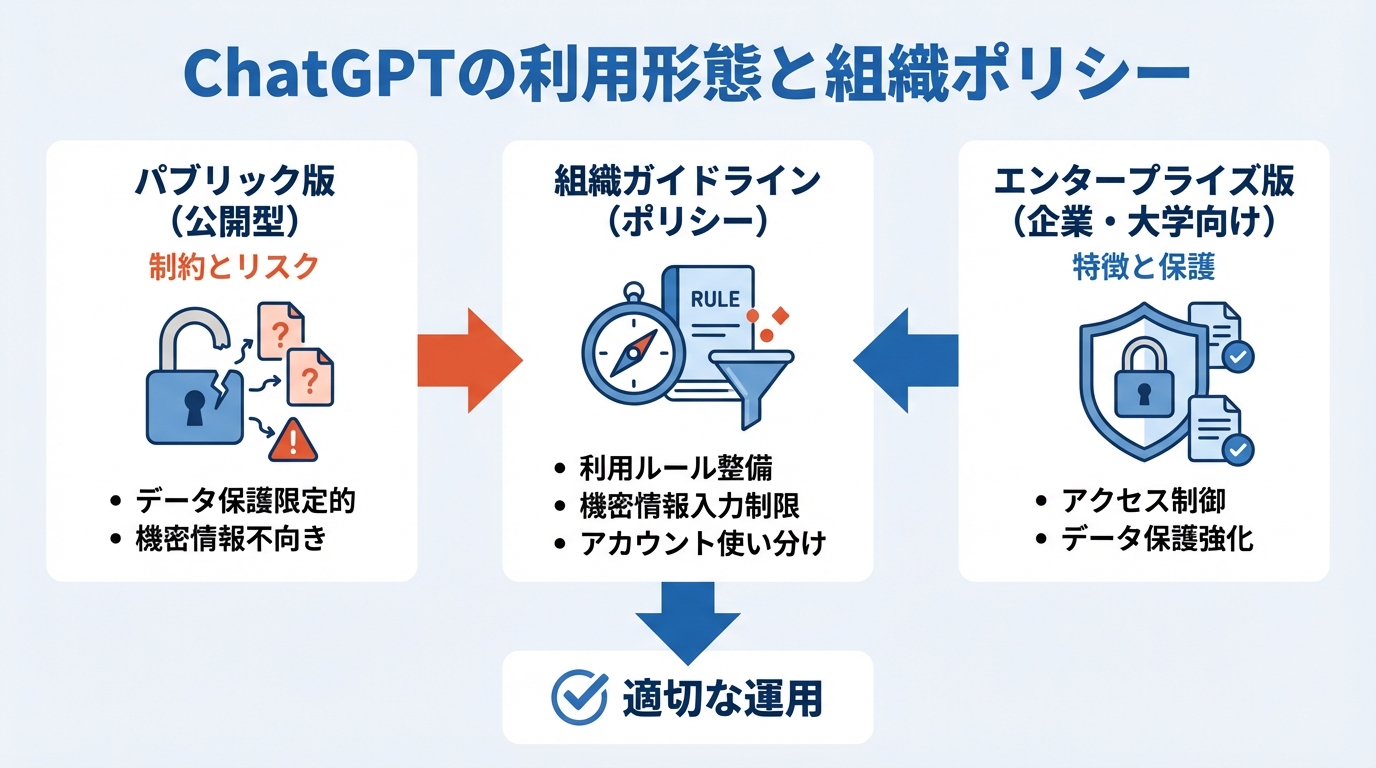
パブリック版の制約とリスク
ChatGPTのパブリック版は、一般利用者向けに開放されているため、使いやすさと多機能性を備えています。しかし、データ保護やアクセス制御が限定的な場合が多く、企業や公共機関など組織にとってはリスク要因となることがあります。ビクトリア州の情報委員会事務局によれば、公開型ツールはデータの取り扱い・保護に関する制御が最小限であるため、機密性の高い情報のやりとりには適さないとされています(参照*4)。
また、大学など学術機関でもパブリック版の利用は便利である一方、研究データや学生の成績情報を誤って入力した場合、大きなプライバシー問題を引き起こす可能性があります。UCベルモトのガイドでは、生成型AIツールを使用する際はコミュニティ原則と責任あるAIの方針を順守し、特に機密領域での利用には慎重になるよう明記しています(参照*9)。
企業・大学向けライセンス版の特徴
企業や大学向けのエンタープライズライセンス版では、組織内アカウントによる限定的なアクセスや、データ保護を強化する機能が備わっています。MITの指針では、研究データや特許出願情報などの高リスク情報は専用のセキュリティ手段が必要であり、公開型の生成AIツールでは扱わないことが推奨されています(参照*10)。
実際に、ChatGPT Business(旧Team)版を導入している高等教育機関の事例も増えています。たとえば、UW‑Green Bayでは、従来のChatGPT個人アカウントには存在しない保護機能を備えたBusiness版を提供し、それ以外の利用は認めていません。ただし、機密度の高い学生情報や医療情報を入力することは依然として強く制限されており、利用者が適切な運用を行わないとFERPAやHIPAAなどの法令違反となる可能性があります(参照*11)。
公共機関と大学の利用ガイドライン事例
公共機関や大学では、それぞれ独自のガイドラインが整備され始めています。ペンシルベニア大学の場合、学習・研究・ビジネスでの生成型AI利用を推進する一方で、大学アカウントを介してログインしないとセキュリティ上の保護が受けられない仕組みを導入しています。これにより、個人利用と公的利用を区別し、組織の方針に合ったデータ保護を実現しています(参照*12)。
また、職場での利用を検討する場合には、ChatGPTが収集するデータや共有先を認識したうえで、機密情報を入力しないことが推奨されています。特に業務上の書類や顧客データは慎重に取り扱い、ChatGPTへの入力の前に不要な情報を削除するなどの工夫が必要です(参照*1)。
ChatGPTで守るべき個人情報と入力してはいけない情報
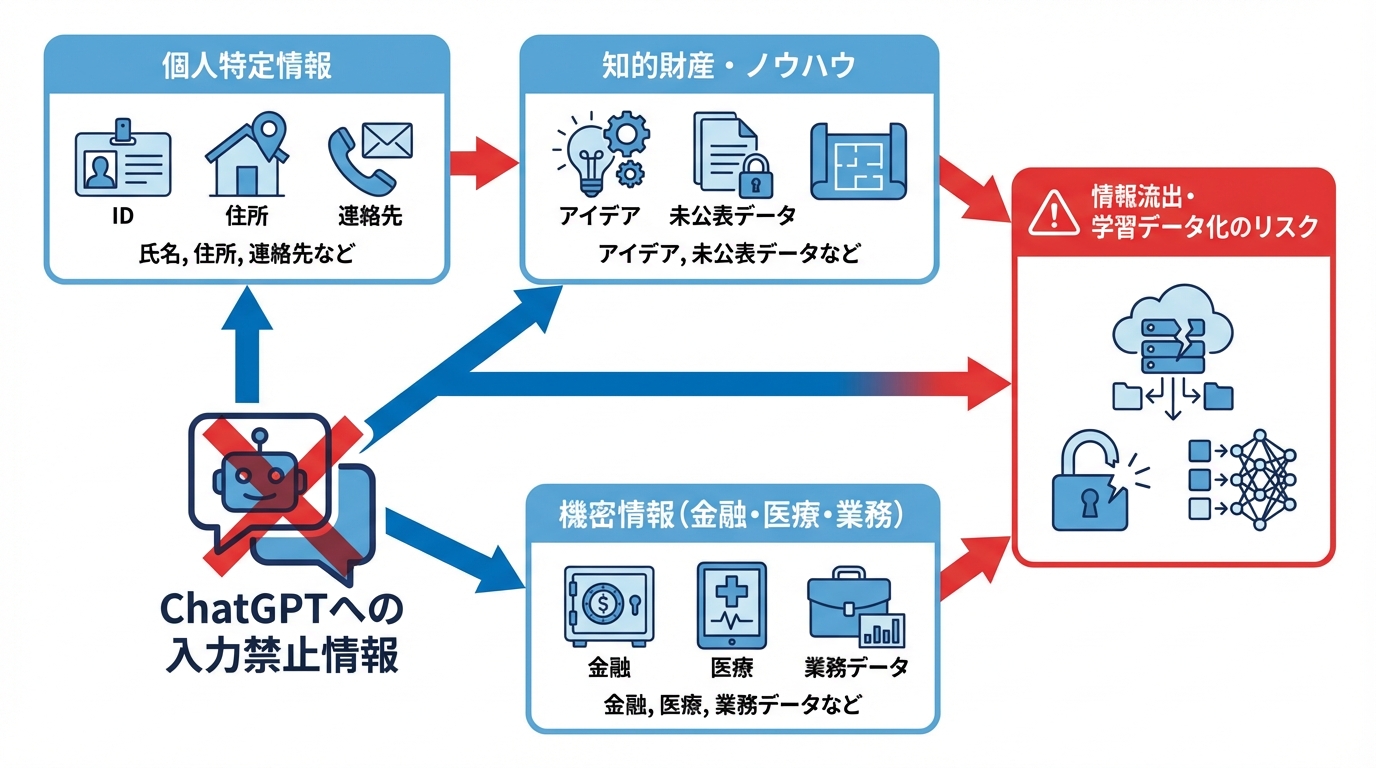
個人を特定できる情報の危険性
個人を特定できる情報は、氏名や生年月日だけでなく、社会保障番号や住所、連絡先など非常に幅広い範囲に及びます。AIシステムへ安易に提示すると、なりすましや不正アクセス、さらにはフィッシング詐欺のリスクが高まるため、共有は極力避けるべきです(参照*6)。
創作物や独自のノウハウといった知的財産にも注意が必要です。著作権者が同意していたとしても、ChatGPTがそのまま学習データとして活用する可能性があり、他のユーザーが似た情報を得られる展開につながります。外部への流出を恐れる企業では、社員の利用を制限しているケースもあり、アイデアを共有する際は特に用心が必要です(参照*5)。
また、会話の文字起こしが無期限に保存される可能性がある点も見落とせません。プラットフォーム側の管理が不十分であれば、個々のやりとりに含まれる名前や住所などが流出する危険があります。職場でも機密情報の海外移転や第三者との共有が行われる場合があるため、入力前の一工夫を習慣化することがポイントです(参照*1)。
金融・医療・機密情報のリスク
金融情報や医療データなど、特に機密性の高い分野の情報は取り扱いに最大限の注意が必要です。ビクトリア州の公共部門向け指針によれば、こうしたデータを公開型の生成AIに入力すれば、法規上の問題だけでなく個人の重大な被害をもたらすおそれがあります。生成AIが予期せず個人情報を再構成してしまう可能性もあり、さらにデータの保存先が海外に及ぶケースも指摘されています(参照*4)。
大学などでも、健康情報や学生の成績情報のように高い機密度を伴うデータは、ChatGPTへの入力を厳しく制限しています。UW‑Green Bayではビジネス版のChatGPTであっても、FERPAやHIPAAの準拠が明確になっておらず、敏感情報の取り扱いを原則禁止としています。こうした事例は、機密度の高い領域こそオープンなAIツールから遠ざける必要があることを示しています(参照*11)。
業務データ・知的財産の取り扱い
業務データや研究関連の機密事項、さらには特許申請前のアイデアなども、むやみにChatGPTへ投げかけるべきではありません。UCベルモトの実務ガイドラインでは、未公表の研究データや機密レベルP2以上の情報をAIへ入力する行為を原則禁止としており、実施には部局レベルでの厳格な承認が必要とされています(参照*9)。
MITでも、高リスク情報を含む財務データや人事情報、学生の記録などは公開型の生成AIへの入力を想定していません。十分なアクセス制御がなければ、外部からの不正アクセスや誤ったデータ取り扱いにより、意図せず重要情報を漏えいする恐れもあるため、機密情報の扱い方法を見直すことが欠かせません(参照*10)。
安全に使うための実践的な対策
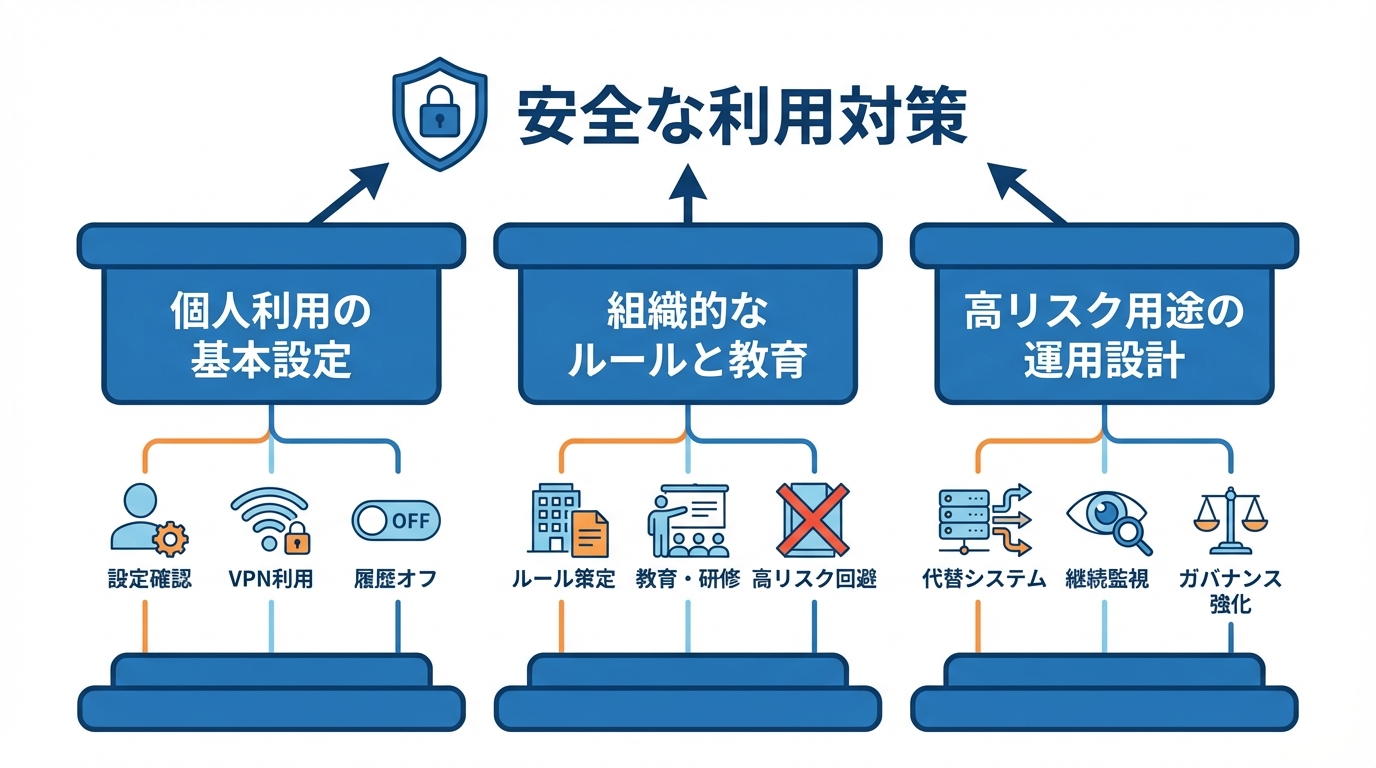
個人利用での基本設定と使い方
個人利用の観点では、まず入力前に内容を再確認する習慣を持つことが重要です。プライベートネットワークやVPNを用いてアクセスすることで、公共のWiFi経由の盗聴リスクを減らせます。さらに、チャット履歴をオフに設定しておけば、回答生成に使われるデータの蓄積を抑えることができ、万一の流出時にも被害を最小限にとどめられます(参照*1)。
自分のオンライン上の情報がどれほど露出しているかを定期的に把握することも大切です。デジタルリテラシー教育では、データブリーチや標的型ハッキングを想定した演習が取り入れられており、学生たちは被害の兆候を見抜く訓練や、情報が漏えいした際の対処を学びます。こうした基礎知識を身につけることで、ChatGPTを含むAIツールの使用時にもより堅固な個人情報保護が実現できます(参照*13)。
企業・学校でのルール設計と教育
企業や教育機関では、まず明確なルールを策定し、利用者がどのような情報を入力してはいけないかを周知徹底することが求められます。AIエッセンシャル研修の受講やリスク評価を行うための専門組織と連携し、新規の利用場面には倫理面や法的リスクにも慎重になる仕組みを導入すべきと、UCベルモトのガイダンスは提案しています(参照*9)。
また、MITの指針によれば、採用選考や学生評価など、判断ミスが重大な影響を及ぼす用途では生成AIの利用を避けることが推奨されています。部門や研究室ごとにポリシーを作成し、WISPなどのセキュリティ文書と整合性を取りながら運用を行うことで、組織全体として情報漏えいリスクを抑制できます(参照*10)。
高リスク用途での代替手段と運用設計
高リスク用途、たとえば公的機関が個人情報を扱う場面では、公開版ChatGPTの利用を前提にしない代替システムの導入や全面的な禁止を検討する必要があります。ビクトリア州の指針によれば、事前のセキュリティリスク評価と継続的な監視をプロセスに組み込み、利用で生じるリスクを最小化することが望ましいとされています(参照*4)。
資産運用業界や研究機関でも、生成AIの導入と同時にリスク管理やガバナンス強化が進められています。専門家らは情報漏えいリスクだけでなく、誤情報や著作権侵害なども含めた包括的な対策を提案しており、組織としてガイドラインを整備する重要性が強調されています。こうした整備の中で個人情報保護は最優先されるべきであり、ChatGPT利用時には守秘義務を徹底し、取扱範囲を常に再点検することが重要です(参照*14)。
おわりに
ChatGPTをはじめとする対話型AIの発展は、私たちの生活やビジネスを大きく変えつつあります。しかし、その利便性の裏側には、個人情報や機密データの取り扱いリスクが常に伴うことを意識する必要があります。
本記事で紹介したリスクと対策を踏まえ、ユーザー一人ひとりが情報管理に責任を持つことがポイントです。適切なルールづくりやツールの選択だけでなく、普段から慎重に入力情報を選別し、デジタル時代のプライバシー保護に取り組んでいきましょう。
監修者
安達裕哉(あだち ゆうや)
デロイト トーマツ コンサルティングにて品質マネジメント、人事などの分野でコンサルティングに従事しその後、監査法人トーマツの中小企業向けコンサルティング部門の立ち上げに参画。大阪支社長、東京支社長を歴任したのち2013年5月にwebマーケティング、コンテンツ制作を行う「ティネクト株式会社」を設立。ビジネスメディア「Books&Apps」を運営。
2023年7月に生成AIコンサルティング、およびAIメディア運営を行う「ワークワンダース株式会社」を設立。ICJ2号ファンドによる調達を実施(1.3億円)。
著書「頭のいい人が話す前に考えていること」 が、82万部(2025年3月時点)を売り上げる。
(“2023年・2024年上半期に日本で一番売れたビジネス書”(トーハン調べ/日販調べ))
参照
- (*1) Hot for Security – What data Chat GPT collects about you, and why is this important for your digital privacy
- (*2) OpenAI Developer Community – Chatgpt knows my parents address – violation of privacy
- (*3) Yahoo!知恵袋 – chatgptについて履歴は完全に見えなくなるor消えますか?
- (*4) Use of personal information with publicly available Generative AI tools in the Victorian public sector – Office of the Victorian Information Commissioner
- (*5) Tech.co – 7 Things You Should Never Share with ChatGPT
- (*6) AgileBlue – 5 Things You Should Never Share with ChatGPT
- (*7) Futurism – It’s Staggeringly Easy for Hackers to Trick ChatGPT Into Leaking Your Most Personal Data
- (*8) The Hacker News – Researchers Find ChatGPT Vulnerabilities That Let Attackers Trick AI Into Leaking Data
- (*9) Appropriate Use of Generative AI Tools
- (*10) Information Systems & Technology – Guidance for use of Generative AI tools
- (*11) UW–Green Bay / GBIT Service Desk – Knowledge Base – Accessing ChatGPT Business with a UWGB Account
- (*12) Penn Generative AI Tools & Resources
- (*13) Common Sense Education – Data Breach Basics
- (*14) KINZAIストア
