はじめに(Gemini APIで何ができる?)
Geminiは、文章だけでなく画像や音声なども扱える生成AIです。Gemini APIを使うと、このGeminiの機能を自分のアプリや業務ツールから呼び出せます。たとえば、問い合わせ対応の下書き作成、会議メモや資料の要点整理、画像の説明文づくりなどを自動化できます。
APIは「別のサービスの機能を、決まった手順で呼び出して使うための窓口」です。つまりGemini APIは、Geminiの頭脳をプログラムから使うための窓口だと考えると分かりやすいです。
企業のDX推進では「まず何を作るか」で迷いがちです。Gemini APIは、小さな業務から試し、効果が見えたものを本番に広げやすい点が特徴です。この記事では、全体像、始め方、基本の呼び出し、モデル選び、運用の注意点までを一つの流れで整理します。
Gemini APIの全体像(できること・利用形態)
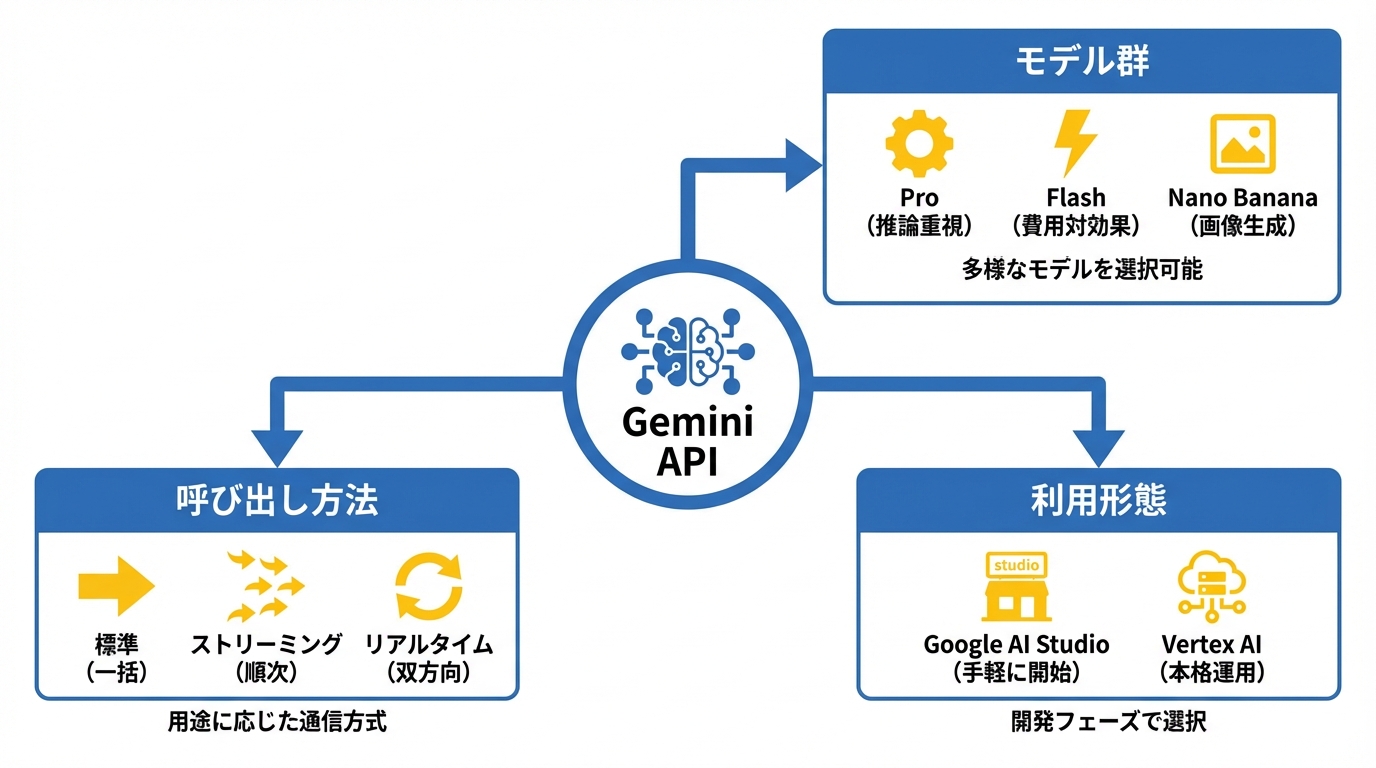
Gemini APIは、テキスト生成だけでなく、画像・音声・動画なども含めて扱えるモデル群と、呼び出し方法(標準・ストリーミング・リアルタイム)を組み合わせて使います。最初に「どの呼び出し方が必要か」「どの利用形態(AI StudioかVertex AIか)が合うか」を押さえると、遠回りを減らせます。
GeminiとGemini APIの位置づけ
Gemini APIには、大きく3つの呼び出し方があります。標準のAPIは、リクエストを送って生成が終わったら1回で結果が返ってくる方式です。ストリーミングAPIは、生成途中の文章が少しずつ届く方式で、待ち時間の体感を減らせます。リアルタイムAPIのLive APIは、WebSocketで双方向にやり取りしながら進む方式で、会話や音声のようにその場で反応してほしい用途に向きます。(参照*1)
Gemini APIは、HTTPで呼び出せるREST APIが用意されています。HTTPリクエストを送れる環境なら利用しやすく、言語別のライブラリやSDKも案内されています。(参照*1)
認証の基本はAPIキーです。すべてのリクエストでx-goog-api-keyヘッダーにAPIキーを含める必要がある、とリファレンスに示されています。(参照*1)
モデル側も用途で選べます。Gemini 3 Proは推論を重視したモデル、Gemini 3 Flashは費用を抑えつつ高い性能を狙うモデルとして説明されています。さらにNano BananaとNano Banana Proは画像生成や画像編集のモデルです。(参照*2)
業務導入の初期は、問い合わせの下書きや社内文書の要約のように「正解が1つに決まらないが、たたき台があると速い作業」と相性が良いです。そのうえで、ストリーミングで体感速度を上げる、Batchで夜間にまとめて回す、といった形に広げると、PoCから本番へつなげやすくなります。(参照*1)
Google AI StudioとVertex AIの利用形態
Gemini APIは、Google AI StudioでAPIキーを作って使い始める流れが分かりやすいです。キーを作成して取得できれば、手元のコードからGemini APIに接続できます。(参照*3)
一方で、Google CloudのVertex AI経由でGemini APIを使う形もあります。Vertex AIのクイックスタートでは、Google Gen AI SDKを入れて最初のAPIリクエストを送る手順が示され、認証方法としてADCまたはAPIキーを選べます。ADCを使う場合は、Cloudプロジェクトの選択、課金の有効化、Vertex AI APIの有効化、gcloud CLIのインストールが前提になります。(参照*4)
どちらを選ぶかは、運用要件で決めるのが現実的です。たとえば、個人検証や小規模PoCならAI Studioで始めやすく、権限管理や課金管理をCloud側に寄せたい場合はVertex AIが候補になります。(参照*4)
PoC止まりを避けるには、開始時点で「本番で必要になること」を少しだけ意識しておくと効果的です。たとえば、誰がキーや権限を管理するか、ログをどこに残すか、入力してよい情報の範囲を決めるか、といった点です。(参照*3)
利用開始の準備(APIキー・プロジェクト・認証)
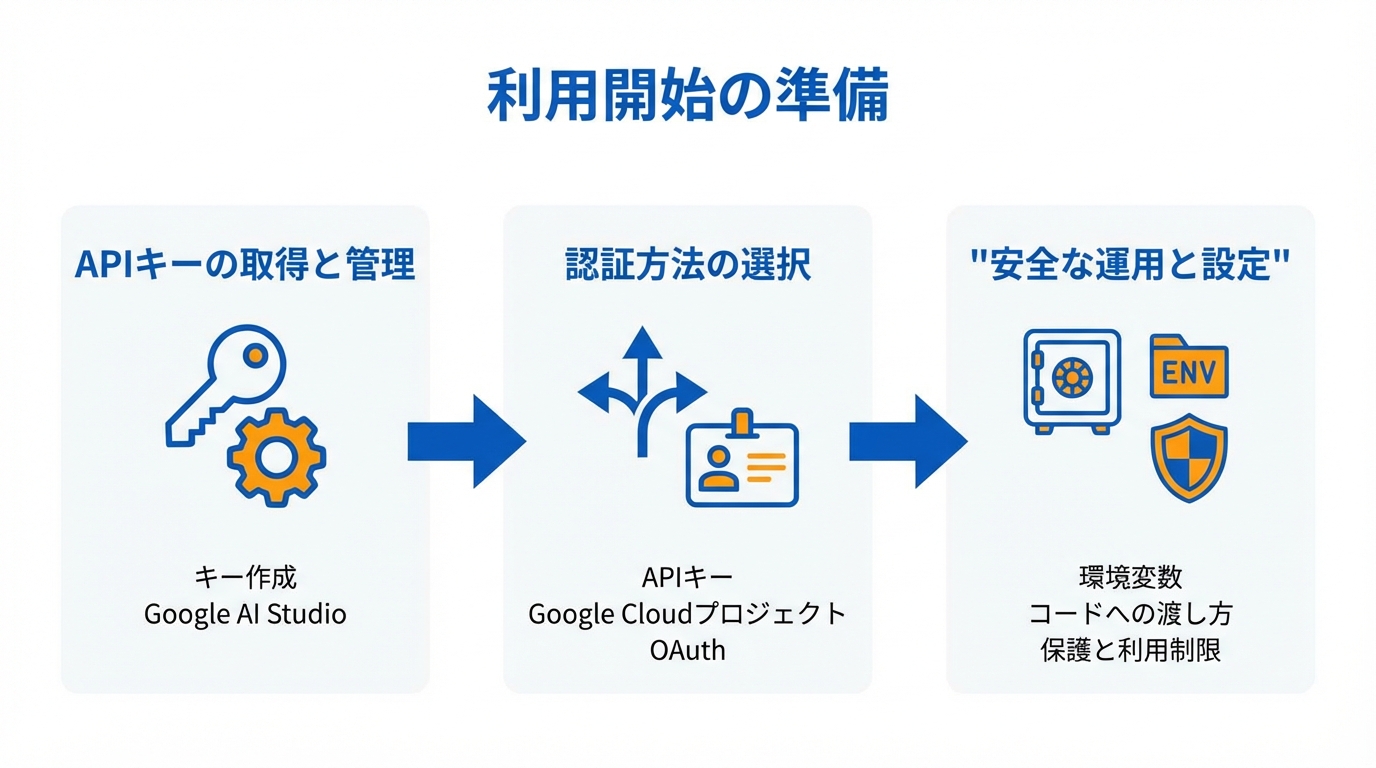
最初の壁は、APIキーの取得と管理です。ここでつまずくと、モデル選びやプロンプト以前に手が止まります。安全に動かすための前提を、短い手順で整理します。
APIキー作成と取得手順
Gemini APIを使うにはAPIキーが必要です。APIキーは、あなたの呼び出しが「誰の利用か」を識別するための合い言葉のようなものです。(参照*3)
作成と表示はGoogle AI StudioのAPIキーページで行います。キーを取得できたら、そのキーを使ってGemini APIに接続できます。まずは「キーを作って、1回呼び出して返る」までを最初のゴールにすると、迷いにくいです。(参照*3)
Google AI Studioのプロジェクトは、Google Cloudプロジェクトの軽量なインターフェースとして説明されています。新しいプロジェクトを作るか、既存のGoogle Cloudプロジェクトをインポートして使います。(参照*3)
もう1つの考え方として、OAuth(外部サービスに安全にログインする仕組み)を使う手順も案内されています。この場合は、Cloudプロジェクトを用意し、Google Generative Language APIを有効化したうえで、OAuth同意画面を構成し、テストユーザーを追加します。外部ユーザーを含むアプリで認証を丁寧に扱いたい場合の選択肢です。(参照*5)
環境変数設定とコードへの渡し方
APIキーは、コードに直接書かず、環境変数として渡すのが基本です。環境変数は、パソコンやサーバー側に「秘密の値」を持たせて、プログラムから読み取れるようにする仕組みです。(参照*3)
案内されている環境変数名はGEMINI_API_KEYまたはGOOGLE_API_KEYです。片方だけ設定するのが推奨で、両方ある場合はGOOGLE_API_KEYが優先されます。キーを入れ替えたのに反映されない、という混乱を避けるために知っておくと便利です。(参照*3)
また、REST APIやブラウザのJavaScriptで使う場合は、APIキーを明示的に指定する必要があるとされています。環境変数に置けない場所では、キーの渡し方(サーバー経由にするか、制限を強めるか)を先に決めておくと安全です。(参照*3)
APIキー保護と運用ベストプラクティス
APIキーは、漏れると第三者に勝手に使われる可能性があります。そのため、キーの機密性を保ち、ソース管理や公開コードに含めないことが推奨されています。(参照*3)
利用制限も有効です。特定のIPアドレスや参照元での利用制限、必要なAPIだけを有効化する、といった設定が勧められています。使える範囲を狭めるほど、万一漏れても被害を抑えやすくなります。(参照*3)
運用面では、定期的な監査とローテーション(キーの定期交換)が推奨されています。さらに、サーバー側から呼び出す設計や、エフェメラルトークン(短時間だけ有効な一時トークン)の活用なども紹介されています。(参照*3)
DX推進の現場では、技術よりも「運用ルールがなくて止まる」ケースがよく起きます。たとえば、PoCでは個人キーで動いたが、本番で担当が変わって管理できない、といったパターンです。最初の段階でも、管理者と保管場所だけは決めておくと、次の承認が取りやすくなります。(参照*3)
基本の呼び出し方(generateContent・ストリーミング・Live)
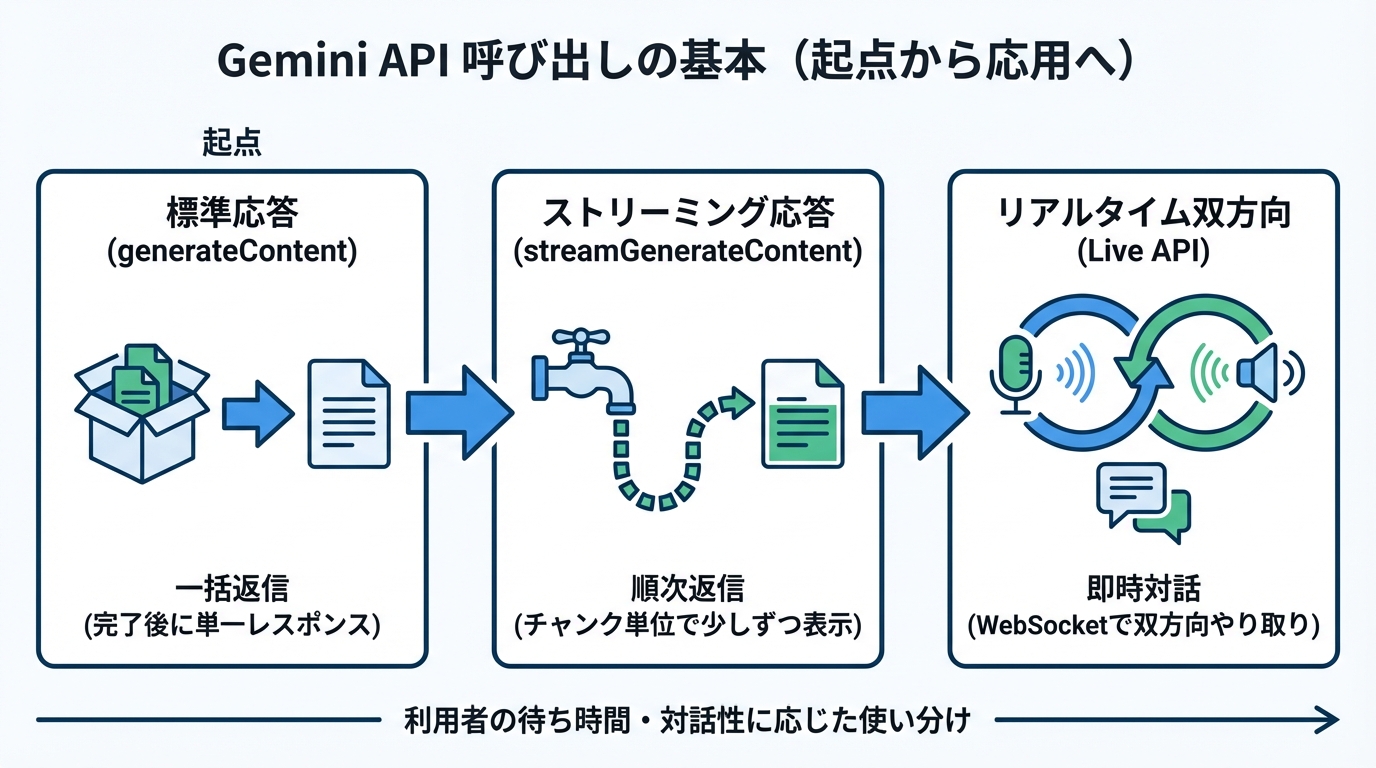
Gemini APIの呼び出しは、標準のgenerateContentを起点に理解すると整理しやすいです。次にストリーミング、最後にLive APIを必要に応じて検討します。
generateContentのリクエスト構造
Gemini APIの基本はgenerateContentです。標準エンドポイントは、リクエストを受け取り、生成全体を完了した後に単一のレスポンスを返します。(参照*1)
リクエスト本文はJSONで、標準モードとストリーミングモードで同じ構造です。会話はcontents配列で表し、Contentが会話の1ターンの入れ物になります。さらにPartオブジェクトで、テキストや画像などのデータを入れます。(参照*1)
マルチモーダルは、同じContentの中に複数のPartを入れることで実現します。たとえば「画像」と「この画像を説明して」というテキストを同じターンに入れる、という形です。(参照*1)
企業利用でよくある最初の実装は「社内文書を貼り付けて要点を返す」「問い合わせ文面の候補を返す」といった一問一答です。この段階では、まず標準のgenerateContentで、入力と出力が安定して返ることを確認すると進めやすくなります。(参照*1)
streamGenerateContentとLive APIの使い分け
ストリーミングのstreamGenerateContentは、レスポンスをチャンク単位で返します。画面に少しずつ文章が出るため、利用者は待ち時間を短く感じやすく、対話的な体験を作りやすくなります。(参照*1)
Live APIはリアルタイムの双方向ストリーミングをWebSocketで提供します。結果を受け取るだけでなく、やり取りしながら進めたい場面に向く、と整理すると理解しやすいです。(参照*1)
ほかにも、バッチモード(batchGenerateContent)やエンベディング(embedContent)などの機能が挙げられています。GeminiにはImagenやVeoなどの専用モデルを用いたメディア生成機能が組み込まれており、generateContent APIからアクセスできます。(参照*1)
使い分けの目安は、利用者が待っているかどうかです。利用者が画面の前で待つならストリーミング、裏側でまとめて処理してよいならバッチ、音声や即時応答が必要ならLive API、という判断がしやすいです。(参照*1)
マルチターン会話と履歴管理
会話を続けるときは、contents配列に過去のターンを積み重ねて送ります。Gemini APIではcontentsが会話のターンを表すため、履歴をどこまで入れるかが会話品質に影響します。(参照*1)
履歴管理のポイントは、目的に必要な情報だけを残すことです。雑談のように後で不要になるターンは省き、条件や決定事項は残す、といった整理が効きます。履歴が長くなるほど送る情報も増えるため、必要な範囲を決めておくと運用しやすくなります。(参照*1)
Pythonでは、以前はgoogle.generativeaiパッケージが使われ、2024年末にgoogle-genaiという新しいパッケージが出た、という整理が紹介されています。また、OpenAI互換性があり、OpenAIのAPIを使う方法をそのまま使えるとも説明されています。既存の実装を活かしながら移行したい場合に、判断材料になります。(参照*6)
モデル選定のコツ(Gemini 3/2.5・プレビュー・専用モデル)
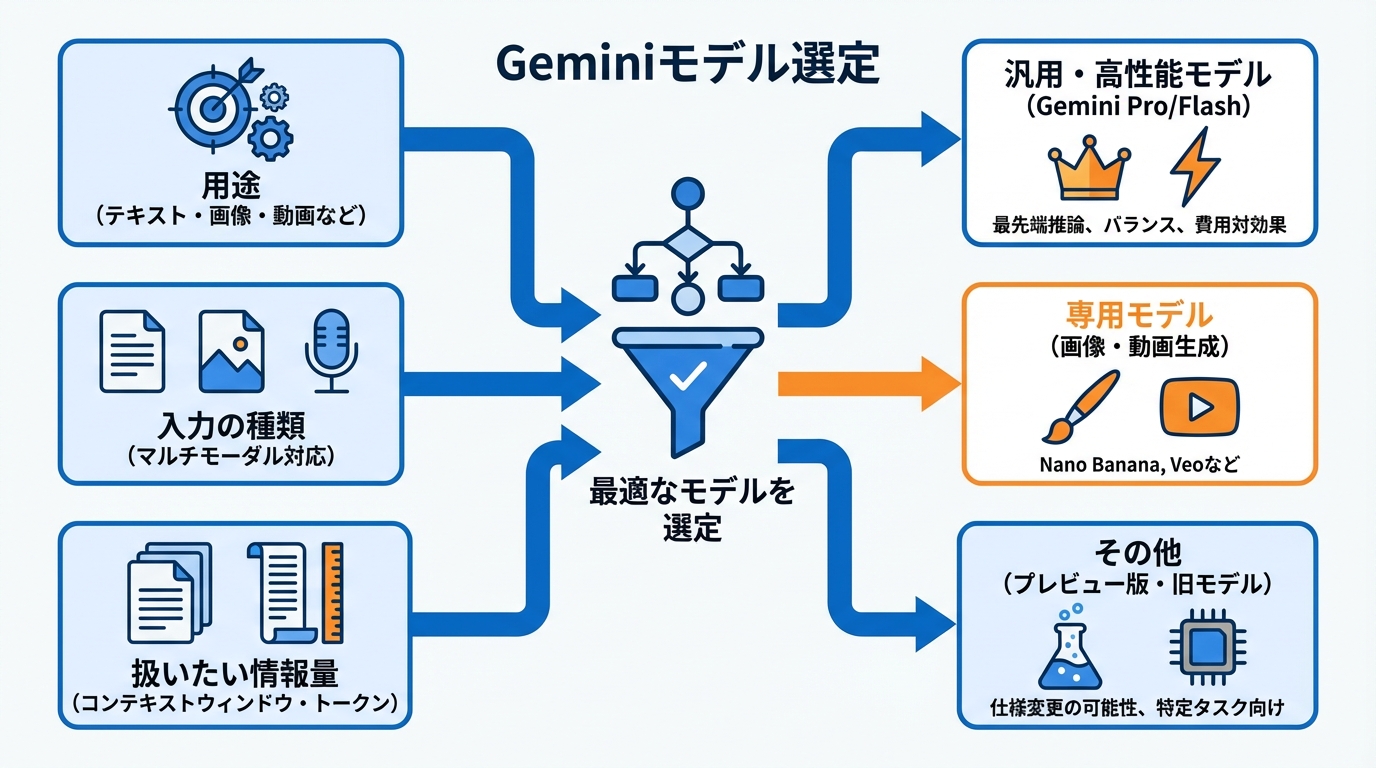
Geminiはモデルが複数あり、得意分野と費用感が異なります。モデル選びは「用途」「入力の種類(テキストだけか、画像や音声も扱うか)」「扱いたい情報量」の3点で考えると整理しやすくなります。
用途別モデル選定
モデルは、やりたいことに合わせて選ぶのが近道です。Gemini 3 Proは、最先端の推論に基づいて構築されたGoogleの最もインテリジェントなモデルであり、マルチモーダル理解において世界最高水準のモデルだと説明されています。一方でGemini 3 Flashは、大規模モデルに匹敵するパフォーマンスを、わずかな費用で実現するとされています。(参照*2)
画像生成や画像編集が目的なら、Nano BananaやNano Banana Proが画像生成および編集モデルとして挙げられています。文章生成と同じ感覚で選ぶと混乱しやすいため、目的が画像なら専用モデルを選ぶ、という切り分けが分かりやすいです。(参照*2)
Gemini 2.5 Proは、コーディングや複雑な推論タスクに優れた強力な推論モデルです。Gemini 2.5 Flashは、100万トークンのコンテキストウィンドウを備えた最もバランスの取れたモデル、Gemini 2.5 Flash-Liteは、高頻度のタスクで優れたパフォーマンスを発揮する高速で費用対効果が高いマルチモーダルモデル、と説明されています。(参照*2)
動画生成ではVeo 3.1がネイティブ音声に対応した最先端の動画生成モデルとして挙げられています。文章の自動化と同じ基盤で、画像・動画などへ拡張できる点が、業務の横展開をしやすくします。(参照*2)
コンテキストウィンドウとトークン上限
モデル選びで見落としやすいのが、コンテキストウィンドウ(モデルが一度に参照できる情報量)とトークン上限です。Gemini 3 Proは、入力1,048,576トークン、出力65,536トークンと示されています。長い資料や複数の情報をまとめて扱いたいとき、この上限が効いてきます。(参照*7)
Gemini 3 Proは入力としてテキスト、画像、動画、音声、PDFに対応し、出力はテキストです。また、音声生成、ファイル検索、関数呼び出し、URLコンテキストなどをサポートするとされています。一方で、画像生成やマップによるグラウンディングなど一部は対象外とも書かれているため、やりたい機能が対象かを先に確認すると手戻りを減らせます。(参照*7)
プレビュー版のgemini-3-pro-previewのようなバリエーションもあり、年月日やバージョンの付け方は「モデル バージョンのパターン」を参照するよう案内されています。プレビューは試せる反面、運用中に仕様や上限が変わる可能性がある前提で扱うと安全です。(参照*7)
社内で説明するときは「どの業務で、どの資料量を一度に扱うか」を言葉にすると決裁が進みやすくなります。たとえば、週次レポートの元データが長いならコンテキストが大きいモデル、短文のチャット応対なら軽量モデル、といった形で要件に結びつけられます。(参照*7)
運用で詰まらないための実践(レート制限・Batch・RAG・規約)
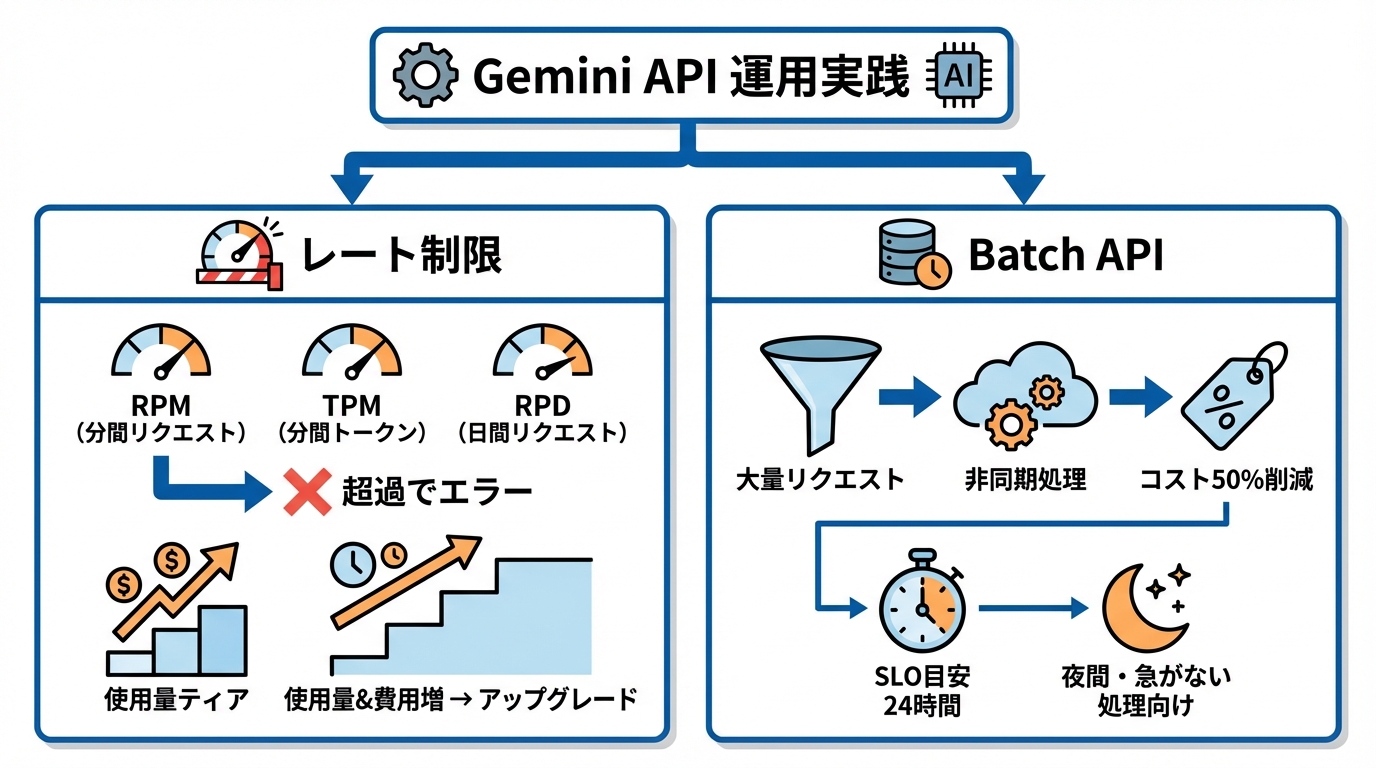
PoCから本番に進むと、性能よりも運用の制約で止まりやすくなります。ここでは、レート制限、まとめ処理(Batch)、社内資料の参照、規約の確認ポイントを整理します。
レート上限のディメンションと使用量ティア
Gemini APIは、使いすぎを防ぐためのレート上限があります。ディメンションは3つで、1分あたりのリクエスト数(RPM)、1分あたりの入力トークン数(TPM)、日あたりのリクエスト数(RPD)です。(参照*8)
使用量は各上限に対して評価され、どれか1つでも超えるとレート制限エラーになります。たとえばRPMが20なら、TPMなどが余っていても1分以内に21回リクエストするとエラーになります。(参照*8)
レート上限はAPIキーごとではなくプロジェクトごとに適用され、RPDのリセットは太平洋時間の午前0時と説明されています。運用で「日次の上限に達する時刻」を見積もるときに、前提として押さえておくと役に立ちます。(参照*8)
上限は使用量ティアに関連付けられており、APIの使用量と費用が増えると上位の階層へアップグレードできると説明されています。また、試験運用版モデルやプレビュー版モデルはレート制限がより厳しいとも書かれています。(参照*8)
ティア要件の要約として、Tier 1は無料で対象地域のユーザーでありTier 1プロジェクトにリンクされた有料請求先アカウントが必要、Tier 2は合計費用$250超で支払い完了から30日以上、Tier 3は合計費用$1,000超で支払い完了から30日以上と示されています。費用と時間の条件があるため、必要になってから申請すると間に合わない可能性もあります。(参照*8)
Batch APIの非同期処理とコスト最適化
大量のリクエストをまとめて処理したいときは、Gemini Batch APIが選択肢になります。Batch APIは非同期処理(すぐに結果を返さず、裏でまとめて処理する方式)向けに設計されており、標準料金の50%で利用できるとされています。(参照*9)
SLO(完了までの目安)は24時間で、実運用ではそれより速く完了することが多いとも説明されています。数分で返ってこないと困る用途には向かないため、夜間の一括処理や、評価用の大量実行のように急がない仕事で使い分けると整理できます。(参照*9)
バッチジョブの作成方法は2通りで、インラインリクエストと入力ファイルです。入力ファイルはJSON Lines(JSONL)形式で、各行に完全なGenerateContentRequestオブジェクトを入れます。最大サイズは2GBと示されています。(参照*9)
Batchは「安くできる」だけでなく「本番で詰まりにくい」面もあります。ピーク時間の負荷を避けて回せるため、部門をまたいで利用が増える段階で役に立ちます。(参照*9)
ファイル検索とURLコンテキストと利用規約
社内資料やWebページを根拠として答えさせたい場合は、ファイル検索とURLコンテキストが候補になります。ファイル検索は、資料を取り込んで検索し、見つかった部分を材料にして回答を作る仕組みとして説明されています。(参照*10)
ファイル検索では、クエリ実行時のファイル保管とエンベディング生成が無料とされ、料金が発生するのは最初のインデックス登録時のエンベディングモデル費用と、通常のGeminiモデルの入出力トークン費用のみだと説明されています。費用の出どころが分かれるため、事前に見積もりを立てやすくなります。(参照*10)
URLコンテキストは、指定したURLの内容を取り込む仕組みです。内部インデックスのキャッシュから取得を試み、登録がなければライブ取得に切り替えると説明されています。1リクエストで扱えるURLは最大20個で、テキスト、画像、PDFなどに対応しています。(参照*11)
運用では規約も確認が必要です。規約は2025年4月3日に更新され、2025年5月20日より有効とされ、利用にはGoogle API利用規約とGemini API追加利用規約への同意が必要です。また年齢制限として18歳以上に限られ、18歳未満の個人向けのウェブサイトやアプリ、サービスの一部として使用してはならないと書かれています。利用地域の制限もあり、欧州経済領域、スイス、英国のユーザーは有料サービスのみ利用が認められるとされています。(参照*12)
さらに無料サービスでは、提出したコンテンツと生成された回答が、Googleのプライバシーポリシーに基づき提供、改良、開発に用いられる場合があると説明されています。プライバシー保護のため、人間のレビュアーによる確認や注記、処理が行われることがあるとも書かれています。無料枠で試す段階でも、入力してよい情報(個人情報や機密情報を含むか)を決めておくと、社内の合意形成が進めやすくなります。(参照*12)
おわりに(次にやることチェックリスト)
Gemini APIは、標準、ストリーミング、リアルタイムという呼び出し方を軸に、モデル選びや運用設計まで一続きで考えると理解しやすいです。まずは標準のgenerateContentで小さく動かし、体験を良くしたくなったらストリーミング、要件が合えばLiveやBatchへ広げる流れが自然です。(参照*1)
次にやることを、手順として残します。
- Google AI StudioでAPIキーを作成し、環境変数に設定する(参照*3)
- generateContentで1回呼び出し、contentsとPartの形に慣れる(参照*1)
- 用途に合うモデルとトークン上限を確認する(参照*7)
- レート上限とティア、規約の年齢や地域の条件、無料サービス時のデータ取り扱いを確認する(参照*8)(参照*12)
社内導入を急ぐ場合は、最初のユースケースを「効果が測れる業務」に絞ると前に進みやすくなります。たとえば、月次レポートの下書き作成や、問い合わせ対応の一次回答案の生成のように、作業時間の削減が数字で見える業務です。そのうえで、レート制限やキー管理まで含めて設計すると、PoCで終わらず本番に近づけやすくなります。(参照*8)(参照*3)
監修者
安達裕哉(あだち ゆうや)
デロイト トーマツ コンサルティングにて品質マネジメント、人事などの分野でコンサルティングに従事しその後、監査法人トーマツの中小企業向けコンサルティング部門の立ち上げに参画。大阪支社長、東京支社長を歴任したのち2013年5月にwebマーケティング、コンテンツ制作を行う「ティネクト株式会社」を設立。ビジネスメディア「Books&Apps」を運営。
2023年7月に生成AIコンサルティング、およびAIメディア運営を行う「ワークワンダース株式会社」を設立。ICJ2号ファンドによる調達を実施(1.3億円)。
著書「頭のいい人が話す前に考えていること」 が、82万部(2025年3月時点)を売り上げる。
(“2023年・2024年上半期に日本で一番売れたビジネス書”(トーハン調べ/日販調べ))
参照
- (*1) Google AI for Developers – Gemini API reference
- (*2) Google AI for Developers – Google AI for Developers
- (*3) Google AI for Developers – Gemini API キーを使用する
- (*4) Google Cloud Documentation – Vertex AI の Gemini API クイックスタート
- (*5) Google AI for Developers – Google AI for Developers
- (*6) Gemini APIを使う
- (*7) Google AI for Developers – Google AI for Developers
- (*8) Google AI for Developers – Google AI for Developers
- (*9) Google AI for Developers – Google AI for Developers
- (*10) Google AI for Developers – Google AI for Developers
- (*11) Google AI for Developers – Google AI for Developers
- (*12) Google AI for Developers – Gemini API 追加利用規約
