
はじめに(Geminiは何がすごいのかを最短で掴む)
Geminiは、文章だけでなく画像や音声、動画、コードまでまとめて扱えるGoogleの生成AIです。調べる、考える、作るを1つの流れで進めやすいのが強みです(参照*1)。
Googleは「Gemini 3」を発表し、推論・長い文脈・マルチモーダルなど各世代で伸ばしてきた能力を統合して、Googleの規模で提供すると説明しています(参照*2)。
さらに報道では、2025年12月18日に軽量で高速な「Gemini 3 Flash」が発表され、用途に合わせて速さや費用を選びやすくなったとされています(参照*3)。この記事では、Geminiは何がすごいのかを、性能、使い心地、導入のしやすさ、注意点の順にほどいていきます。
Geminiの全体像(モデルからアプリまで)
Geminiの定義と位置づけ
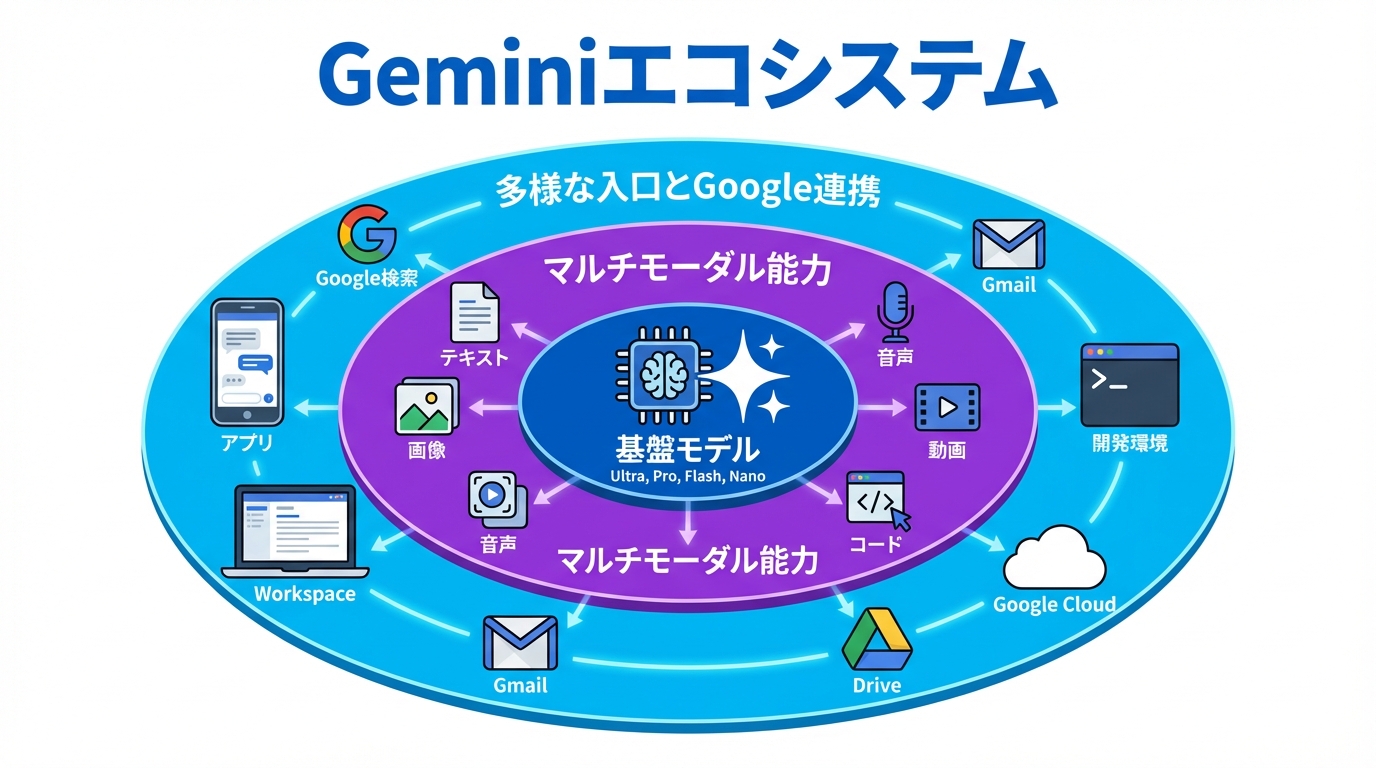
Geminiは2023年12月にGoogleが開発した、複数の種類の情報をまとめて理解して文章などを作れる生成AIモデルです。テキストに加えて、コード、音声、画像、動画も扱える点が特徴です(参照*1)。
できることは、質問への回答、翻訳、要約、メール文の作成、コードの見直し、物語や詩の作成、入力に基づく画像生成など幅広いです(参照*4)。
またGeminiには用途が違う基盤モデルがあり、たとえばGemini Ultraは高性能でテキストや画像、音声、動画、コードなどを高速に処理し、Gemini Proは汎用性が高く推論や創作の作業に強みがあります。Gemini Flashは速度とコスト効率、Gemini Nanoは端末上で動く用途に向くと整理されています(参照*1)。
ここで押さえたいのは、「Gemini=チャット画面」ではなく、目的に合わせてモデルと入口(アプリ、Workspace、開発環境)を選ぶ考え方が土台にある点です(参照*1)。
またGeminiはChatGPTなど他の生成AIと比較されやすい一方、Google検索やGoogle Workspaceとつながる前提で設計されている点が利用シーンを広げています(参照*1)。導入担当者の観点では、単発の回答品質だけでなく「普段使っている業務ツールに、どれだけ自然に入り込めるか」が評価ポイントになりやすいです。
Geminiの普及状況とエコシステム規模
Geminiのすごさは、性能だけでなく届く範囲の広さでも見えてきます。Googleの発表では、AIの概要は月間20億ユーザー、Geminiアプリは月間6億5000万以上のユーザーを獲得し、クラウド顧客の70%以上がGoogleのAIを利用し、1300万の開発者が生成モデルを使っているとしています(参照*2)。
この規模感が意味するのは、Geminiが単体の道具ではなく、研究やモデル、開発ツール、インフラ、そして多くの人が日常で触れる製品までを一体で回している点です(参照*2)。
導入の現場では、利用者が多いほど運用ノウハウが集まりやすく、連携先(検索、Gmail、Driveなど)も増えやすくなります。結果として、PoCで試したあとに本番へつなげる説明材料を集めやすい土台ができます。
AI性能で見たGeminiのすごさ(推論・マルチモーダル・長文)
推論能力と少ないプロンプトでの到達力
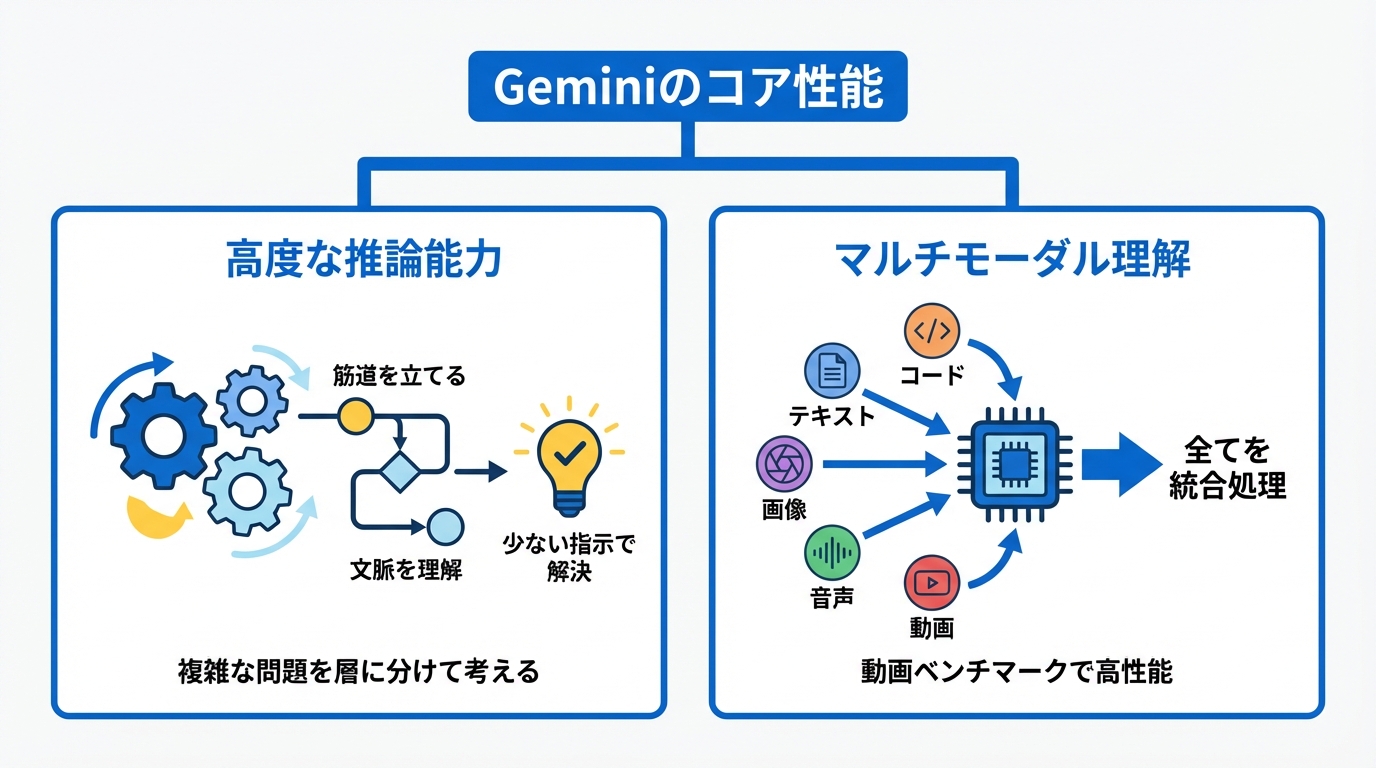
Geminiの性能面でまず押さえたいのは、推論の強さです。GoogleはGemini 3について、深さや細かな違いを捉え、創造的なアイデアの小さな手掛かりを読み取り、難しい問題を層に分けて考えられると説明しています(参照*2)。
ここでいう推論は、単に知識を並べるのではなく、状況を理解して筋道を立てる力です。たとえば社内の業務改善で、現状の作業手順、制約(個人情報の扱い、承認フロー)、ゴール(工数削減、品質の均一化)を整理して、どこから手を付けるかを決める場面が分かりやすい例です。
Gemini 3は文脈と意図をより正確に理解する力が高く、少ないプロンプトでも必要なものを得られるとされています(参照*2)。少ないプロンプトで進むと、やり取りが減るだけでなく、指示が長文化して要点がぼやける失敗も起きにくくなります。
また開発の文脈では、Gemini 2.5 ProがWebDev ArenaのランキングでフロントエンドWeb開発能力が優れているとされ、Cursorのコードエージェントの中核になっていること、CognitionやReplitとの協業を可能にしていることが紹介されています(参照*5)。ここでのエージェントは、指示を受けて作業を進めるAIの役割のことです。推論が強いほど、単発の回答だけでなく、作業の手順そのものを組み立てる方向に広がります。
業務での使い方に落とすと、たとえば「月次レポート作成の手順を分解して、どこを自動化できるか案を出す」「FAQの問い合わせログを分類して、回答テンプレート案を作る」といった、整理と判断を含む作業に向きます。
マルチモーダル理解と動画ベンチマーク指標
Geminiはマルチモーダル、つまり文章以外の情報も一緒に理解できる点が大きな特徴です。GoogleはGeminiを、テキストだけでなくコード、音声、画像、動画などを理解して処理できるモデルとして説明しています(参照*1)。
動画理解の強さは、数値でも語られています。Googleの開発者向け情報では、Gemini 2.5 ProがVideoMMEという動画ベンチマークで84.8%を記録したとされています(参照*5)。ベンチマークは、同じ条件で性能を比べるためのテストのことです。
動画を理解できると何が変わるのか。例として、Google AI Studioの「Video to Learning App」は、1本のYouTube動画を元に対話型の学習アプリを作成できる体験として紹介されています(参照*5)。動画の内容を読み取り、学習用の質問や説明に組み替える発想です。
同じ情報源では、動画理解とコード作成を組み合わせることで、新しい作業の流れを生み出すとも述べています(参照*5)。たとえば社内研修動画から、要点まとめに加えて理解度チェックの設問を作り、簡単な学習ページにする、といった展開が考えやすくなります。文章だけのAIより入力の入口が増えるぶん、現実の業務資料(画像の図、動画の説明)を含む形で扱える場面が増えます。
長いコンテキストウィンドウと大規模入力処理
Geminiのもう1つの強みは、長い入力をまとめて扱えることです。Geminiアプリの案内では、Google AI Proへアップグレードすると1Mトークンの文脈ウィンドウを利用でき、最大で約1,500ページ分のテキストまたは30k行のコードを処理可能だとされています(参照*6)。
文脈ウィンドウは、AIが一度に見渡せる情報の量だと考えると理解しやすいです。長い資料や長いプログラムは、途中で前提が変わったり、前のページの条件が効いてきたりします。そこをまとめて読めると、分割して貼り付ける手間が減り、全体のつながりを保ったまま要約や見直しを頼みやすくなります(参照*6)。
業務に置き換えると、RFPや提案書、規程集、FAQ、障害報告書の束などをまとめて読み込ませ、「論点の抜け」「矛盾」「前提の違い」を洗い出す使い方と相性が良いです。ただし、入力できるからといって機密情報をそのまま渡すのではなく、利用する入口(個人利用か、組織アカウントか)に合わせてルールを先に確認する必要があります(参照*7)。
また同じ案内では、Google AI Ultraへアップグレードすると、Googleの最も高度なモデル3 ProやVeo 3.1の動画生成、Deep Research、Gemini 3 Deep Thinkなどの機能を利用できるとされています(参照*6)。長文処理と高度機能が同じ導線にあることで、読む量が多い作業から、作る作業までをつなげやすい設計になっています。
プロダクト体験で見たGeminiのすごさ(検索・Workspace・スマホ)
検索体験とAIモードの統合
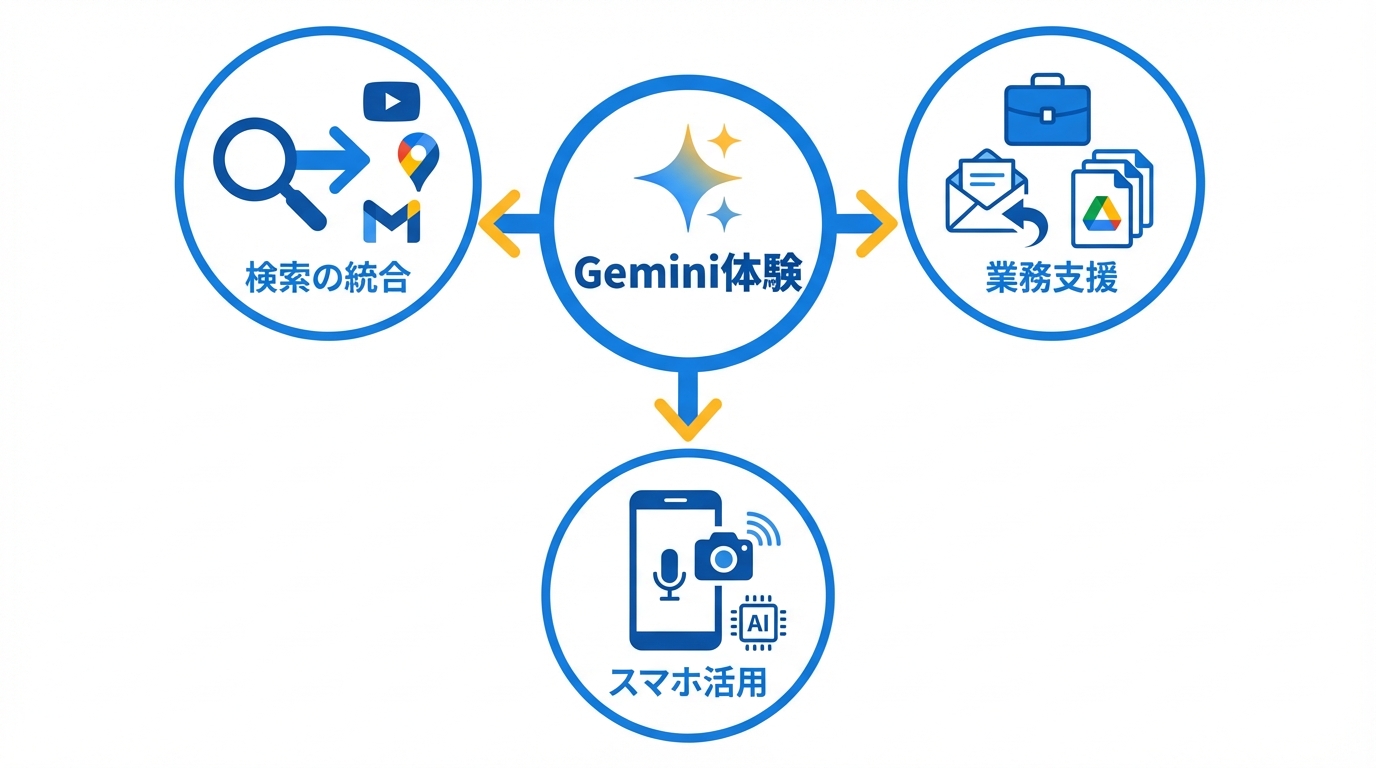
Geminiの体験面で分かりやすい変化は、検索への入り方です。GoogleはGemini 3を検索のAIモードで提供し、より複雑な推論と新しい動的な体験を含むと説明しています(参照*2)。検索は多くの人が毎日使う入口なので、ここに統合されると、AIが特別な道具ではなく普段の調べ物の延長になります。
Geminiアプリ側でも、SearchやYouTube、Google Maps、GmailなどのGoogleアプリと連携でき、要約や深掘り、出典リンクを1か所で取得できると案内されています(参照*8)。調べた結果をまとめ直したり、次に何を調べるべきかを整理したりする流れが、1つの画面に寄りやすいのがポイントです。
導入担当者の視点では、社内の問い合わせ対応や調査業務で「まず検索し、次に社内資料を探す」という行動が多いほど、入口がまとまる価値が出ます。検索と要約が近いと、調査メモやレポートのたたき台までを短い導線で作りやすくなります。
Google Workspace業務支援機能
仕事や学校での実用性が出やすいのが、Google Workspaceでの支援です。GoogleはGmailで、過去のメールやGoogle Driveから情報を引き出して、より適切で的確な返信案を提案するパーソナライズされたスマートリプライを紹介しています(参照*9)。返信のたびにスレッドを読み直したり、別ファイルを探したりする時間を減らす狙いです。
またメール整理についても、削除やアーカイブといった作業をGeminiが代行し、受信箱の整理を助けるとされています。例として「私の未読メールを昨年のThe Groomed Pawから全て削除」と指示し、ワンクリックで管理を手伝う機能が、次の四半期に一般提供開始予定だと説明されています(参照*9)。
スマホ側では、Gemini Liveが自然な会話で使える機能として紹介され、2025年4月7日のアップデート以降、カメラやスマホ画面を映像として共有しながら会話できるようになったと報じられています(参照*10)。利用にはGoogle One AIプレミアム(月額2900円(税込))が必要とされる一方で、Pixel 9やGalaxy S25などでは映像共有機能付きGemini Liveを契約なしで使えるとも書かれています(参照*10)。
さらにCNET Japanは、Tensor G5とGemini NanoによりAI機能が端末上で動作し、日常操作での実用性を重視していると伝えています。例として、会話をリアルタイムで翻訳するマイボイス通訳が印象的だった一方、予約や日程情報の表示を提案するマジックサジェストは完璧ではなく改善の余地があるとも述べています(参照*11)。
この流れを業務に寄せると、外回りや現場対応の担当者が、写真や画面共有を使って状況説明し、その場で要約や次アクション案を作る、といった使い方が見えてきます。PC前に戻らないと進まない仕事を減らせるかどうかが、体験面での差になりやすいです。
開発・導入で見たGeminiのすごさ(API・コスト・エージェント)
開発者向け提供形態と導入導線
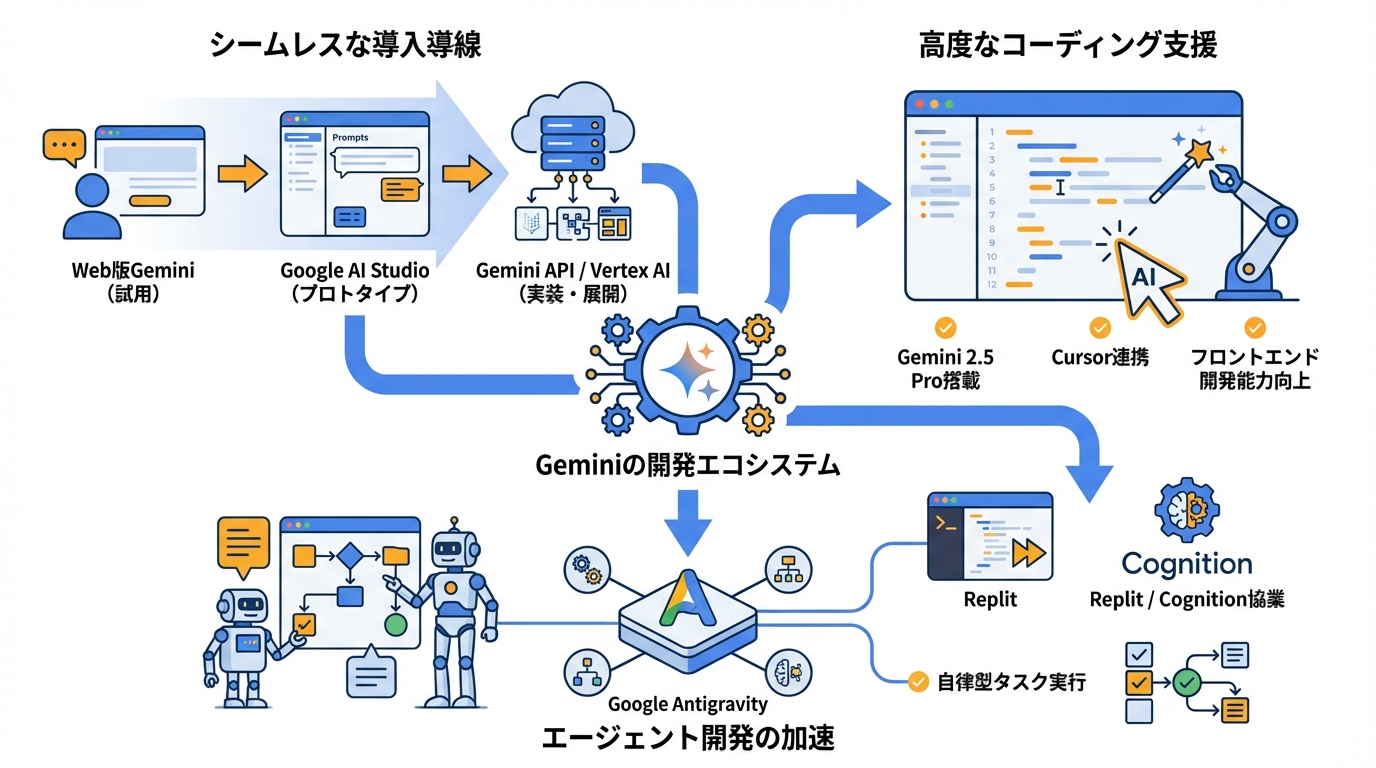
Geminiは、使う人の立場に合わせて入口が用意されています。紹介されている形としては、Web版Gemini(一般ユーザー向け)、Google AI Studio(開発者向けのテスト環境)、Gemini API(アプリ開発向け)、Vertex AI(企業向けの開発環境)の4つです(参照*1)。
またGoogleはGemini 3が、Geminiアプリ、AI StudioとVertex AI、そして新しいエージェント開発プラットフォームのGoogle Antigravityでも提供されると述べています(参照*2)。エージェント開発プラットフォームは、作業を進めるAIの仕組みを作るための土台だと捉えると分かりやすいです。
個人の利用から開発、企業導入までが同じ系列でつながるため、試してから作るまでの距離が短くなります。たとえば、まずGeminiアプリで社内向け回答のたたき台を作り、次にAI Studioでプロンプトやデータ連携の当たりを付け、要件が固まったらAPIやVertex AIで業務システムに組み込む、という順番が取りやすくなります(参照*1)。
コーディング支援と開発ツール連携事例
開発の現場での具体例として、GoogleはGemini 2.5 ProがWebDev ArenaのランキングでフロントエンドWeb開発能力が最も優れていることを示し、Cursorのコードエージェントの中核になっていると説明しています(参照*5)。Cursorは、コードを書く作業をAIで支援する開発用の道具です。
さらに同じ情報源では、ReplitやCognitionとの協業にも触れています。Replitはブラウザ上で開発できる環境で、Cognitionは開発支援の領域で知られる企業です。これらと組み合わせることで、エージェント型プログラミングの可能性が開くとされています(参照*5)。
コメントとして、Replit社長のMichele Catasta氏はGemini 2.5 Proを「能力対遅延」の比率で最も優れたフロンティアモデルと評価し、遅延に敏感な作業の信頼性を高める場面でReplit Agentに展開していく期待を述べています(参照*5)。遅延は待ち時間のことなので、速さと賢さのバランスが良い、という意味合いです。
またCognition創設チームのSilas Alberti氏は、ジュニアデベロッパーの評価でもリード性能を達成し、リクエストルーティングのバックエンド大規模リファクタリングを含む評価を解決した最初のモデルで、適切な判断と良い抽象化を選べる点がより熟練の開発者のようだったとコメントしています(参照*5)。リファクタリングは、動きは変えずにコードの中身を整理して読みやすくする作業です。
導入担当者が押さえたいのは、「コードを書ける」だけでなく「変更の影響を読んで、構造を直す」ところまで期待されている点です。社内システム連携や運用改善は、手直しが前提になることが多いため、保守の観点でも評価しやすくなります。
コスト性能と高速モデルの設計思想
費用と速さの面では、報道として2025年12月18日にGoogleがGemini 3 Flashを発表したとされています。軽量で高性能、回答を非常に速く生成できる点が特徴とされています(参照*3)。
同じ報道では、API利用料はInputが0.5ドル/1Mトークン、Outputが3ドル/1Mトークンで、Gemini 3 Proの1/4と説明されています。コスト面の有利さが開発ツールの無料枠拡大にも寄与した、という説明もあります(参照*3)。
さらにGemini 3 Flashは「思考の循環」という仕組みを採用し、APIの応答に含まれる思考の続きを次のリクエストへ暗号データとして返して推論の状態を連結し、超高速に処理するとされています(参照*3)。ここでの思考はAIの推論過程を指すと説明されており、速さを出すための設計思想が語られています(参照*3)。
業務での判断材料にすると、同じ品質が必要な作業でも「毎日大量に回す軽めの処理(分類、一次要約)」と「週次・月次で丁寧にまとめる重めの処理(レポート、設計レビュー)」が混ざります。モデルの速度と単価の選択肢が増えると、作業の種類ごとに費用を見積もりやすくなります。
注意点とガバナンス(安全性・プライバシー・限界)
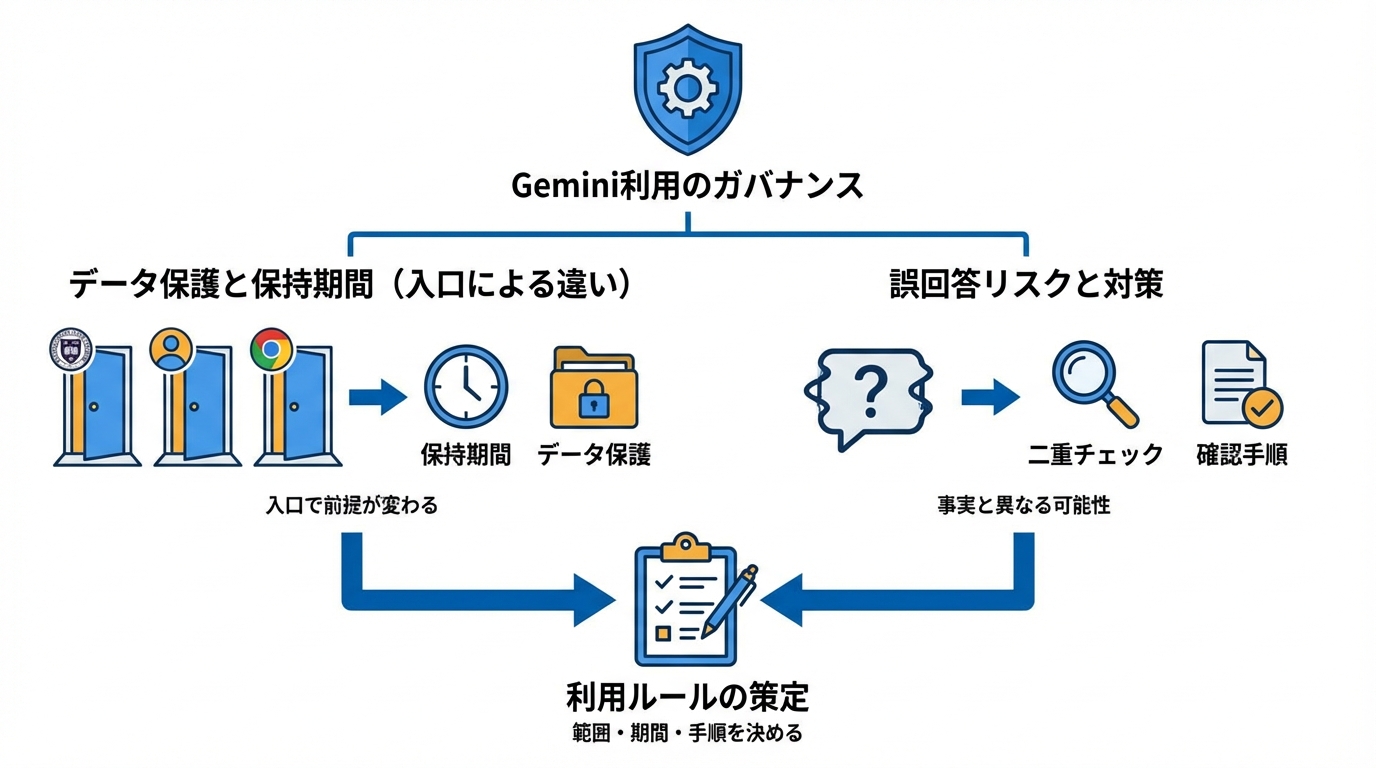
データ保護と保持期間のルール
Geminiを使うときは、入力した内容がどう扱われるかを先に確認したいところです。ハワイ大学(University of Hawaiʻi, UH)の案内では、Google@UHアカウントでの利用において、Geminiの活動データが人間によって評価されたり、AIモデルのトレーニングに使用されたりすることは基本的にないと説明されています(参照*4)。
一方で、ミネソタ大学(University of Minnesota)の案内では、Geminiに入力したデータやGeminiから受信したデータは情報セキュリティの推奨に従い3か月間保持され、3か月を過ぎると履歴、プロンプト、結果はGeminiから削除されるとされています。また現時点でエンドユーザーはGeminiのチャットを個別に削除できないとも書かれています(参照*7)。
さらにミシガン大学(University of Michigan)の案内では、Gemini in Chromeを使うと、デフォルトで閲覧中のブラウザタブのページ内容とURLを取得して処理し、表示されない内容が含まれる場合もあると説明されています。データはGemini Apps Activityに保管され、ページ内容は一時的にU-M Googleアカウントに記録される一方、Gemini Apps Activityには表示されず、18か月間保持されるとされています(参照*12)。
また個人開発の注意点として、AI Studioで入力したデータがGoogleの学習やモデル改善に使用される可能性があるため、機密性の高い情報は扱わず、有料プランの検討などの対策が必要だという指摘もあります(参照*13)。
同じGeminiでも入口によって前提が変わり得ます。社内で使うなら、まず「どの入口で使うか」を決め、次に「入力してよい情報の範囲」「保持期間」「共有範囲」を短いルールにしておくと、PoCから本番へ移すときの説明が通りやすくなります(参照*7)。
誤回答リスクと利用上の注意
生成AIには、事実と異なる情報を自信ありげに返す可能性があります。UHの案内でも、情報の信頼性を常に評価するよう注意が書かれています(参照*4)。
同じ案内では、Geminiには回答を二重チェックする機能があるとも説明されています(参照*4)。ただし、機能があることと、誤りが起きないことは別です。レポートや社内文書に使うなら、出典リンクを開いて一次情報に戻る、数字と固有名詞は原文で照合する、といった確認手順を先に決めると運用に乗せやすくなります。
また、スマホのカメラ共有など便利な機能ほど、映り込みや画面共有により意図せず情報が入るリスクが増えます。使う場面を決め、写してよい範囲を揃えるだけでも事故が減らせます。
おわりに(Geminiのすごさを活かす次の一手)
Geminiは何がすごいのかを一言でまとめるなら、推論、マルチモーダル、長文処理を、検索やメール、開発環境まで一続きで使える点です(参照*1)(参照*2)(参照*6)。
次の一手としては、まず「毎週かならず発生し、入力データの範囲を切り出しやすい作業」を1つ選び、Geminiに任せる範囲を小さく決めるのが現実的です。たとえば、問い合わせログの分類、会議メモの要約、レポートの構成案づくりなどから始めると、効果測定(何分減ったか、修正が何回必要だったか)を取りやすくなります。
そのうえで、入力データの扱いと保持期間などのルールを確認し、誤回答の可能性を前提に二重チェックを組み込むと、Geminiの強みを安全に活かしやすくなります(参照*7)(参照*4)。
PoCで手応えが出たら、次は入口の整理です。個人の試用はGeminiアプリ、検証はAI Studio、業務システム連携はAPIやVertex AIというように役割を分けると、現場の使い勝手とガバナンスを両立しやすくなります(参照*1)。
監修者
安達裕哉(あだち ゆうや)
デロイト トーマツ コンサルティングにて品質マネジメント、人事などの分野でコンサルティングに従事しその後、監査法人トーマツの中小企業向けコンサルティング部門の立ち上げに参画。大阪支社長、東京支社長を歴任したのち2013年5月にwebマーケティング、コンテンツ制作を行う「ティネクト株式会社」を設立。ビジネスメディア「Books&Apps」を運営。
2023年7月に生成AIコンサルティング、およびAIメディア運営を行う「ワークワンダース株式会社」を設立。ICJ2号ファンドによる調達を実施(1.3億円)。
著書「頭のいい人が話す前に考えていること」 が、82万部(2025年3月時点)を売り上げる。
(“2023年・2024年上半期に日本で一番売れたビジネス書”(トーハン調べ/日販調べ))
参照
- (*1) 株式会社LIG(リグ)|DX支援・システム開発・Web制作 – 【2025最新】Geminiとは?特徴や活用例、使い方を徹底解説
- (*2) Google – A new era of intelligence with Gemini 3
- (*3) Yahoo!ニュース – Googleが作った「超高速で思考するAI」がスゴそうすぎる【Gemini 3 Flash】
- (*4) Google Gemini
- (*5) Gemini 2.5 Pro Preview: even better coding performance
- (*6) App Store – Google Gemini App
- (*7) Gemini: Data and Appropriate Use
- (*8) Apps on Google Play
- (*9) Google Workspace Blog – Introducing new ways Gemini in Workspace helps you do your best work
- (*10) Business Insider Japan – グーグル「Pixel 9a」のAI機能はどれくらい使える?「Gemini Live」の実力を試す
- (*11) CNET Japan – 「Pixel 10」実機レビュー:妥協なしのトリプルカメラと進化したAI機能が魅力
- (*12) University of Michigan – Knowledge Base – Google: "Gemini in Chrome" Browser Feature
- (*13) Zenn – Google最新!「Gemini 2.5 Pro」が凄い理由を徹底解説
