
はじめに
AnthropicがClaudeの最上位モデルをOpus 4.8へアップグレードしました。私は毎日のように複数の生成AIモデルを業務で使い比べていますが、新モデルが出るたびに宣伝文句ではなく手元のタスクで実力を確かめることにしています。Opus 4.8についても、前世代のOpus 4.7と何が変わったのかを正確に把握しておかなければ、モデル選定やコスト見積もりで判断を誤ることになります。
Opus 4.8は、長時間のエージェント処理・ツール呼び出し精度・正直さといった複数の領域で改善が図られたモデルです。この記事では、ベンチマーク数値や料金体系、同時リリースされた新機能、導入時の注意点まで、参照情報をもとに詳しく解説します。ベンチマーク数値は性能の一側面にすぎないので、実務導入の判断材料として制約事項やコストの話も同様に重視してください。
Claude Opus 4.8の概要
Anthropicの最上位モデルとしての位置づけ
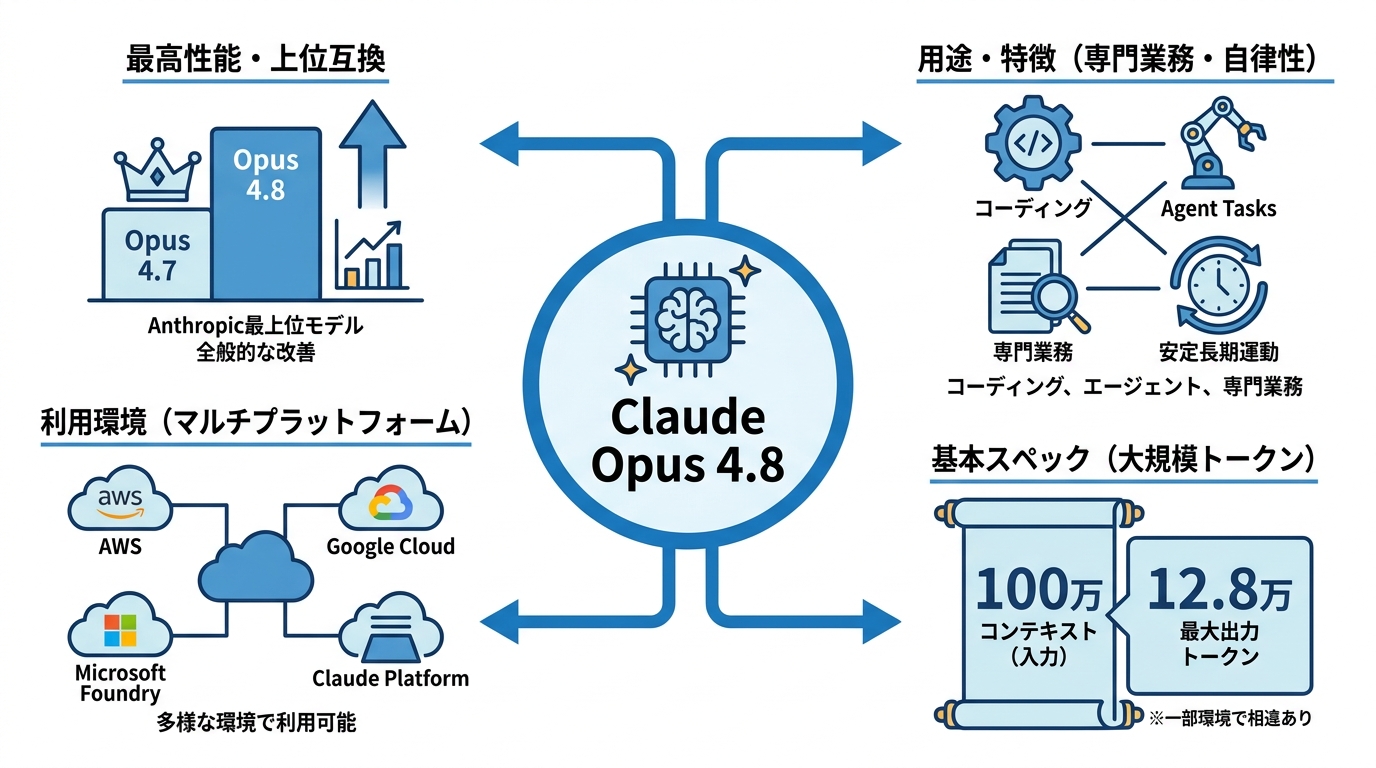
Claude Opus 4.8は、Anthropicが一般提供するモデルのなかで最も高い性能を持つモデルとして位置づけられています。前世代のOpus 4.7を土台とし、ベンチマーク全般にわたって改善が施されたうえで、より効果的な共同作業者として機能するよう設計されました(参照*1)。
対象とする用途は、コーディング、エージェント型のタスク、そして専門的な業務です。長時間にわたるタスクでも安定して動作し続ける一貫性と自律性を備えている点が特徴とされています。開発者向けには、Claude PlatformのほかAmazon Web Services、Google Cloud、Microsoft Foundryの各環境で利用できます(参照*2)。
つまり、Opus 4.8はAnthropicが現時点で提供する最高性能のClaudeモデルであり、従来のOpus 4.7と同じ価格帯でその上位互換として展開されています。用途やプラットフォームの選択肢が広い点は、導入先を検討するうえで押さえておきたいポイントです。ただし、最上位モデルであることと、自社の用途に最適であることは別の話です。後述するコスト面も踏まえて判断してください。
基本スペックとモデルID
Claude Opus 4.8の基本仕様として、コンテキストウィンドウは既定で100万トークンに対応しています。これはClaude API、Amazon Bedrock、Vertex AIで共通の仕様ですが、Microsoft Foundryでは20万トークンとなっています。最大出力トークンは12万8,000トークンです(参照*3)。
機能面では、適応的思考(adaptive thinking)に対応しており、Opus 4.7と同じツール群およびプラットフォーム機能をそのまま使えます。既存のOpus 4.7向けに構築したワークフローやツール連携は、基本的にそのままOpus 4.8へ移行できる設計です。モデルIDを変えるだけで移行できるという設計は、実務上は大きなメリットです。切り替えコストが低いほど、試しやすくなります。
これらの仕様を踏まえると、Opus 4.8は大量の文書を一度に処理する業務や、長い対話を維持するエージェント用途に適したスペックを持っています。プラットフォームごとのコンテキスト上限の違いには注意が必要です。
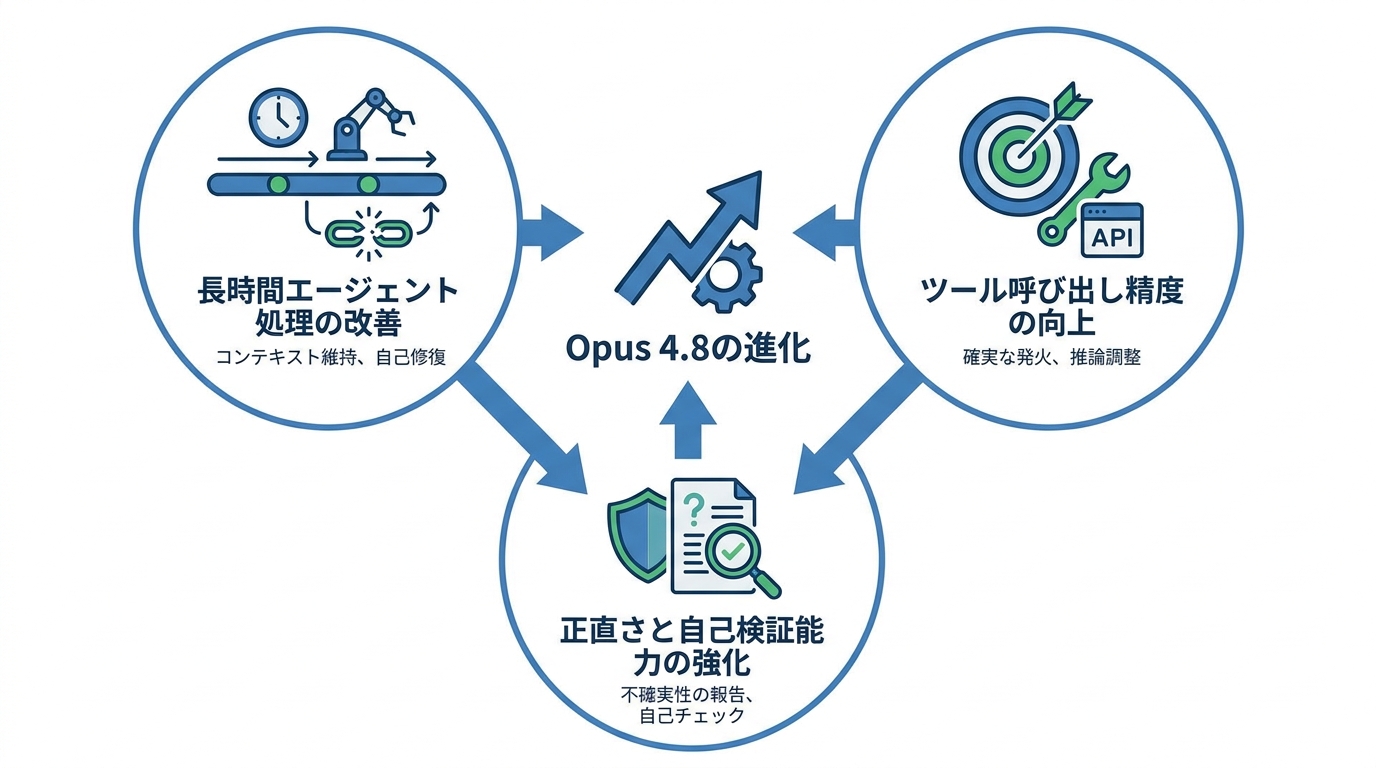
Opus 4.7からの主な進化点
長時間エージェント処理の改善
Opus 4.8では、長時間にわたるエージェント型のコーディング作業が改善の対象となっています。具体的には、長いコンテキストの扱いが向上し、圧縮(compaction)の発生頻度が減少し、圧縮後のリカバリも改善されました(参照*3)。
実務的な動作として、Opus 4.8は複数の段階にまたがる計画を保持し、完了した作業と残りのタスクをより正確に追跡できるようになりました。何かが壊れたときにエラーで止まるのではなく、軌道修正を行う動きが確認されています。私がエージェント系の処理で感じてきた最大の不満のひとつは、途中でコンテキストが壊れたときの回復力の低さでした。この点が改善されているなら、長時間タスクの安定性は実際に上がるはずです(参照*4)。
エージェント型タスクにおいては、障害に直面したとき回避策を見つける能力、自身のエラーからの復旧能力、そして助けを求めるべきか自力で続けるべきかの判断が向上しています(参照*5)。
ツール呼び出し精度の向上
Opus 4.8では、タスクが必要としているにもかかわらずツール呼び出しをスキップしてしまうケースが減少しています。Opus 4.7では、この「ツールの呼び忘れ」が一部で報告されていましたが、Opus 4.8では必要な場面でのツール発火がより確実になっています(参照*3)。
加えて、推論の労力調整(reasoning effort calibration)も改善されており、各努力レベルにおいて幅広い領域でより安定した動作が得られるようになりました。たとえば、低い努力レベルを指定したときには素早く応答し、高い努力レベルでは深い推論を行うという切り替えが、以前よりも一貫して機能するようになっています。
ツール呼び出しの信頼性は、外部APIやデータベースと連携するエージェントを構築する開発者にとって、直接的に成果物の品質に影響する要素です。この改善は、自動化パイプラインの安定性を高める方向に寄与します。
正直さと自己検証能力の強化
Opus 4.8でもっとも顕著な改善のひとつとして挙げられているのが「正直さ」です。AIモデルには、根拠が薄いにもかかわらず作業が進んだと自信を持って主張してしまう問題がありました。生成AIを検証し続けてきた立場から言うと、これは深刻な問題です。文章がうまく見えるほど読者は内容も正しいと錯覚しやすい。Opus 4.8は不確実な点を報告する傾向が強まり、裏づけのない主張を行う頻度が下がっているとされています(参照*1)。
評価結果によると、Opus 4.8が自身の書いたコードの欠陥を見逃す確率は、前世代と比べて約4分の1にまで低下しています。早期テスターからも、不確実な箇所を自ら指摘する動作が増えたとの報告が寄せられています(参照*1)。
知識系の業務においても、長い文書や複雑な出典を横断的に統合する能力が向上し、出力の自己チェックを行ったうえで、レビューに耐えうる構造化された成果物を提供できるようになっています(参照*5)。
ベンチマーク比較と実績
主要ベンチマークの数値比較
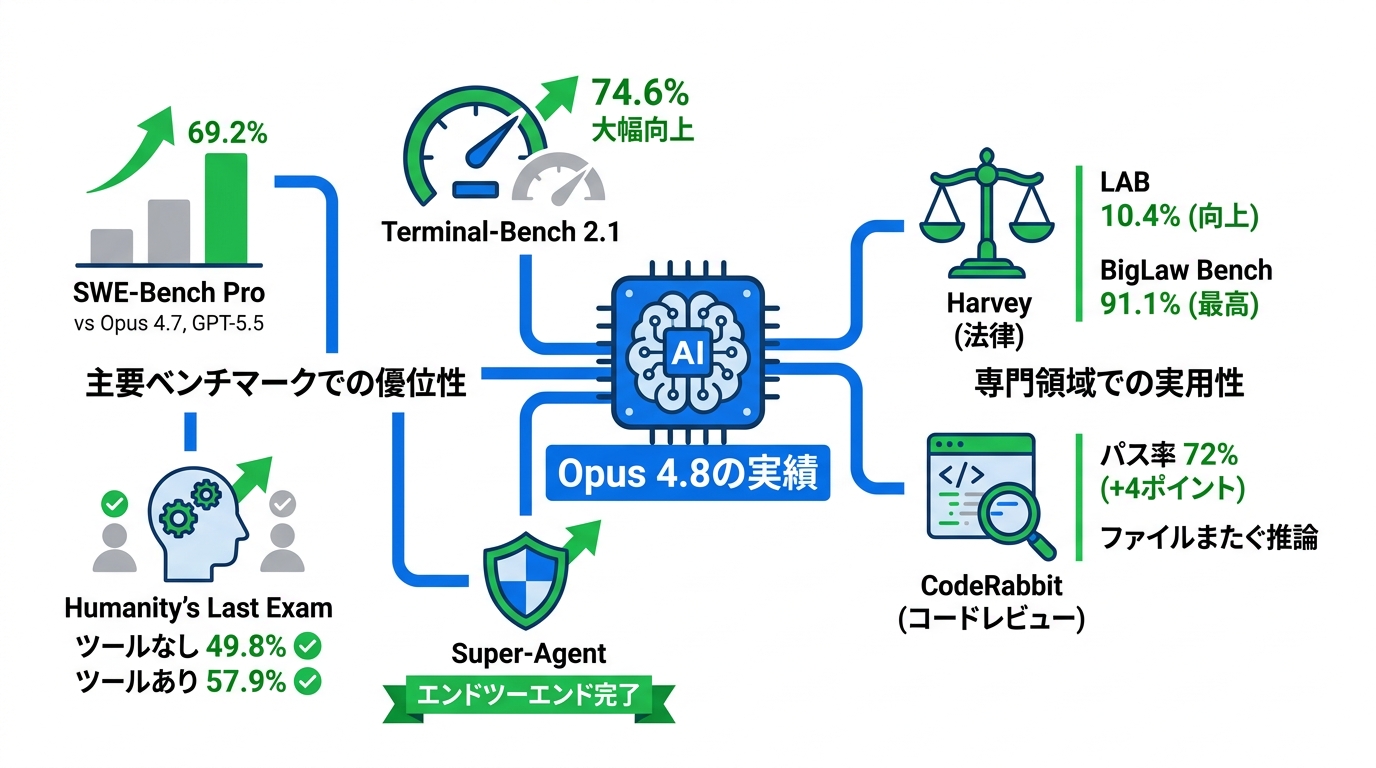
Opus 4.8は複数の主要ベンチマークにおいて、前世代および競合モデルを上回るスコアを記録しています。エージェント型コーディングの指標であるSWE-Bench Proでは69.2%を獲得し、Opus 4.7の64.3%、GPT-5.5の58.6%、Gemini 3.1 Proの54.2%を超えました。ターミナルでのコーディングを測定するTerminal-Bench 2.1では74.6%で、GPT-5.5の78.2%には及ばないものの、Opus 4.7の66.1%からは大幅に向上しています(参照*6)。
学際的推論を測るHumanity’s Last Examでは、ツールなしで49.8%、ツールありで57.9%を記録し、いずれもOpus 4.7やGPT-5.5、Gemini 3.1 Proを上回っています。パソコン操作のエージェント能力を測るOSWorld-Verifiedでは83.4%、知識業務のGDPval-AAでは1890、金融分析のFinance Agent v2では53.9%を達成しました(参照*6)。
また、Super-Agentベンチマークでは、Opus 4.8はすべてのケースをエンドツーエンドで完了した唯一のモデルとされており、翻訳、深掘り調査、スライド作成、分析といったエージェント型の業務で高い信頼性を発揮しています(参照*1)。
企業テスターの評価
法律分野のAIサービスを提供するHarveyは、自社のLegal Agent Benchmark(LAB)でOpus 4.8を評価しています。LABは複雑な法律タスクのエンドツーエンドの完遂を「全件合格」という厳格な基準で測定する指標です。Opus 4.8はこのLABで10.4%を記録し、Opus 4.7の7.1%から向上しました。LABの厳格な全件合格方式で10%を超えた最初のモデルとされています。BigLaw Benchでも91.1%を記録し、Claude系モデルとして最高のスコアです(参照*7)。
コードレビュー分野では、既定のOpus 4.8設定が、チューニング済みのアンサンブル構成と比較して全体のパス率で4ポイント上回る72%を記録しました(既存構成は68%)。実用的コメントのパス率は61%対62%と誤差の範囲内ですが、精度は33.8%を維持しています。特にファイルをまたぐ推論が上級レベルのプルリクエストで顕著だったとの報告があります(参照*8)。
これらの実環境での評価は、ベンチマーク上の数値改善が特定の専門領域でも実際に効果を発揮していることを示しています。私が新モデルの評価で重視するのはまさにこの部分です。公式のベンチマークより、実業務に近い評価軸でどう動くかのほうが、導入判断の精度が上がります。
同時リリースの新機能
Dynamic Workflows
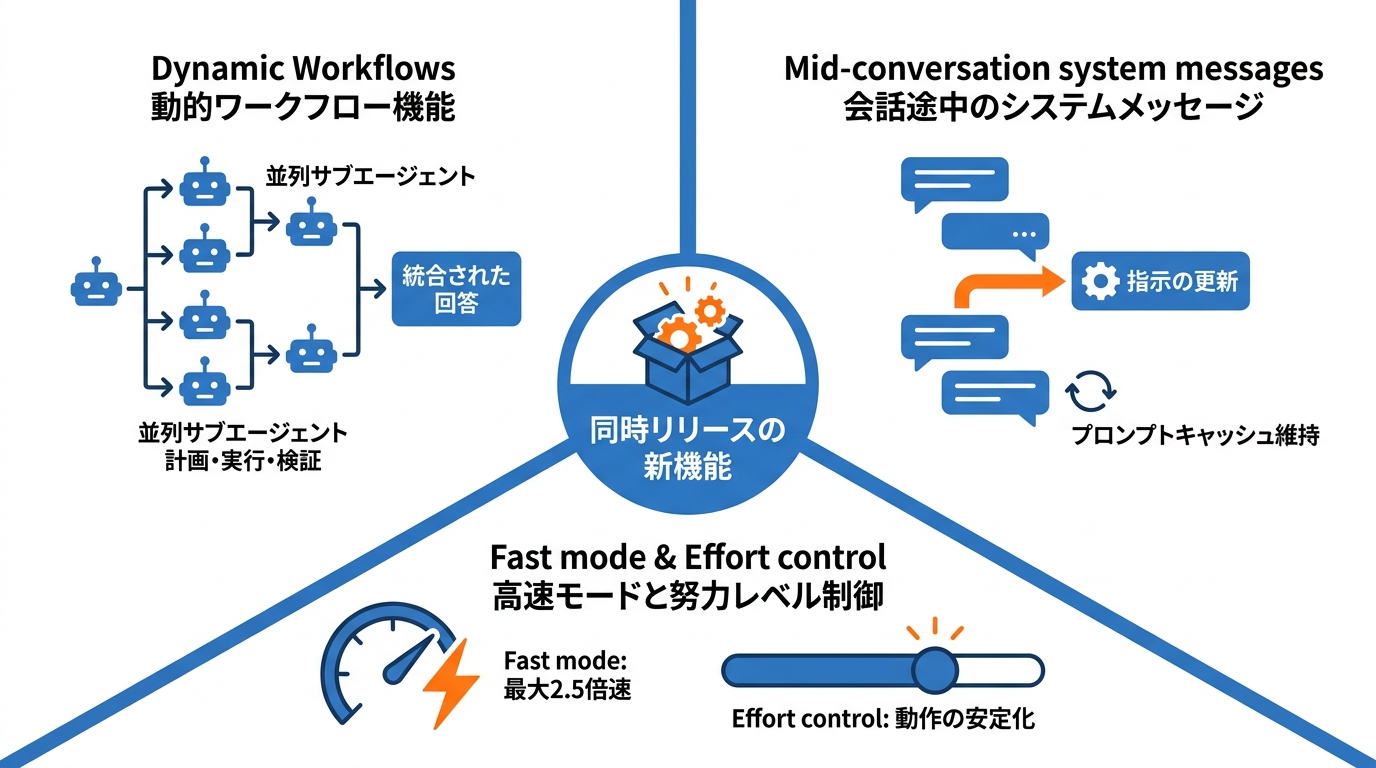
Opus 4.8と同時に、動的ワークフロー機能(Dynamic Workflows)がリサーチプレビューとして公開されました。この機能は、Opusのような大規模モデルが数百の並列サブエージェントを使って複雑なタスクを管理できるよう設計されています(参照*9)。
Dynamic Workflowsが起動すると、Claudeはプロンプトに基づいて動的に計画を立て、タスクを細分化し、サブエージェントへ並列で作業を振り分けます。各サブエージェントは独立した角度から問題に取り組み、別のエージェントがその結果に反論を試み、回答が収束するまで繰り返しが続きます。結果は統合前に検証され、最終的にひとつのまとまった回答として返されます(参照*10)。設計として興味深いのは、反論するエージェントを組み込んでいる点です。単一エージェントが自己完結するより、複数の視点で検証するほうが出力品質は安定しやすい。
実用例として、Claude CodeとOpus 4.8を組み合わせることで、数十万行規模のコードベース移行を開始からマージまで一貫して実行でき、既存のテストスイートを合格基準として使えるとされています(参照*9)。
Mid-conversation system messages
Messages APIに、会話途中のシステムメッセージ(mid-conversation system messages)を挿入できる機能が追加されました。長時間の会話やエージェント実行の途中で指示を更新する際に、システムプロンプト全体の再送が必要になる場合がありましたが、この機能によりプロンプトキャッシュを維持したまま更新しやすくなります(参照*11)。
具体的な活用場面として、エージェントの実行中に権限の更新、トークン予算の変更、環境コンテキストの切り替えを行うことが挙げられています。たとえば、長時間動作するエージェントが処理の途中で外部環境の変化に応じた新しい制約を受け取れるようになります。
プロンプトキャッシュを維持したまま指示を更新できる点は、キャッシュによるコスト削減効果を損なわずに柔軟な制御を実現するうえで実用的な改善です。
Fast modeとEffort control
Claude Opus 4.8では、高速モード(Fast mode)がリサーチプレビューとして利用可能になりました。APIでspeedパラメータを”fast”に設定すると、同じモデルから最大2.5倍の速度で出力トークンを得られます。ただし、割増料金が適用されます(参照*3)。
努力レベルの制御(Effort control)については、Opus 4.8ではClaude API、Claude Codeを含むすべての利用環境で既定値が”high”に設定されています。前世代では各努力レベルでの動作にばらつきが見られましたが、Opus 4.8では幅広い領域でレベルごとの動作がより安定するよう改善されています(参照*3)。
速度を優先するユースケースと、深い推論を優先するユースケースを同一モデル内で切り替えられる設計になっているため、タスクの性質に応じた運用が可能です。
料金体系と利用方法
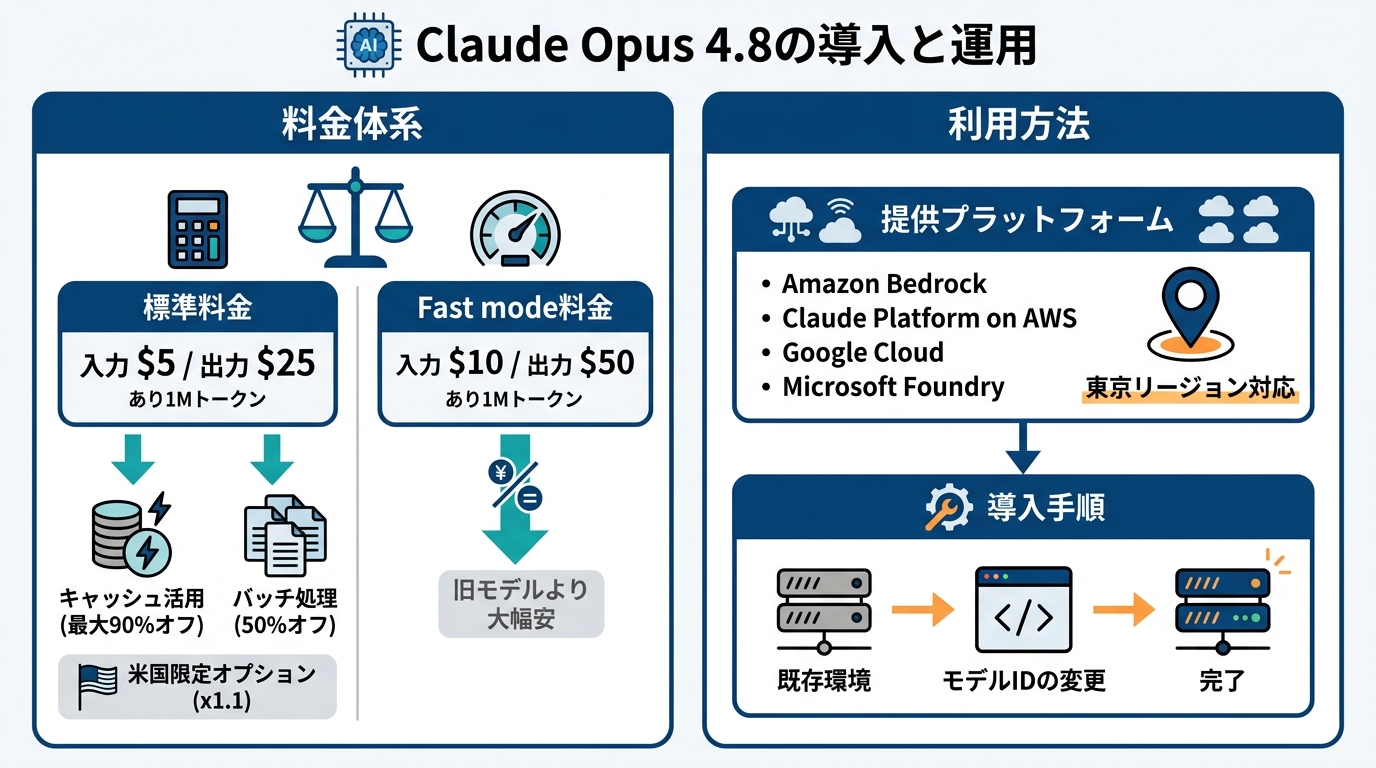
標準料金とFast mode料金
Opus 4.8の標準料金は、入力が100万トークンあたり5ドル、出力が100万トークンあたり25ドルです。プロンプトキャッシュを活用すると最大90%のコスト削減が可能で、バッチ処理では50%の削減が見込めます。米国内のみで推論を行うオプションを選択した場合は、入出力トークンに1.1倍の料金が適用されます(参照*2)。
Fast modeの料金はこれとは別体系です。Opus 4.8のFast modeでは入力が100万トークンあたり10ドル、出力が100万トークンあたり50ドルとなっています。比較として、Opus 4.6およびOpus 4.7のFast modeは入力30ドル、出力150ドルであり、Opus 4.8のFast modeはこれらより大幅に安い設定です(参照*12)。
速度と費用のバランスは利用規模によって大きく変わります。私が企業への導入支援で必ず確認するのは、呼び出し頻度と1回あたりの費用を掛け合わせた月間費用の試算です。標準モードとFast modeの料金差を踏まえ、タスクの性質ごとに使い分ける設計を先に決めておかないと、思わぬコスト超過につながります。
提供プラットフォームと導入手順
Claude Opus 4.8は、Amazon Bedrockにおいて米国東部(バージニア北部)、アジア太平洋(東京)、欧州(アイルランド)、欧州(ストックホルム)の各リージョンで利用できます。Claude Platform on AWSでは、北米・南米・欧州・アジア太平洋と、より広い地域で提供されています(参照*4)。
Claude Platformのほか、Amazon Web Services、Google Cloud、Microsoft Foundryの各環境からもアクセスが可能です(参照*2)。Opus 4.7と同じツール群・プラットフォーム機能をサポートしているため、既存環境からの切り替えではモデルIDの変更が基本的な導入手順の中心となります。
東京リージョンが初期提供に含まれている点は、日本国内でレイテンシを重視する業務にとって確認しておくべきポイントです。クラウドサービスのリージョン選択は後から変更しにくいケースもあるため、初期設計の段階で確認しておく価値があります。
導入時の注意点と制約
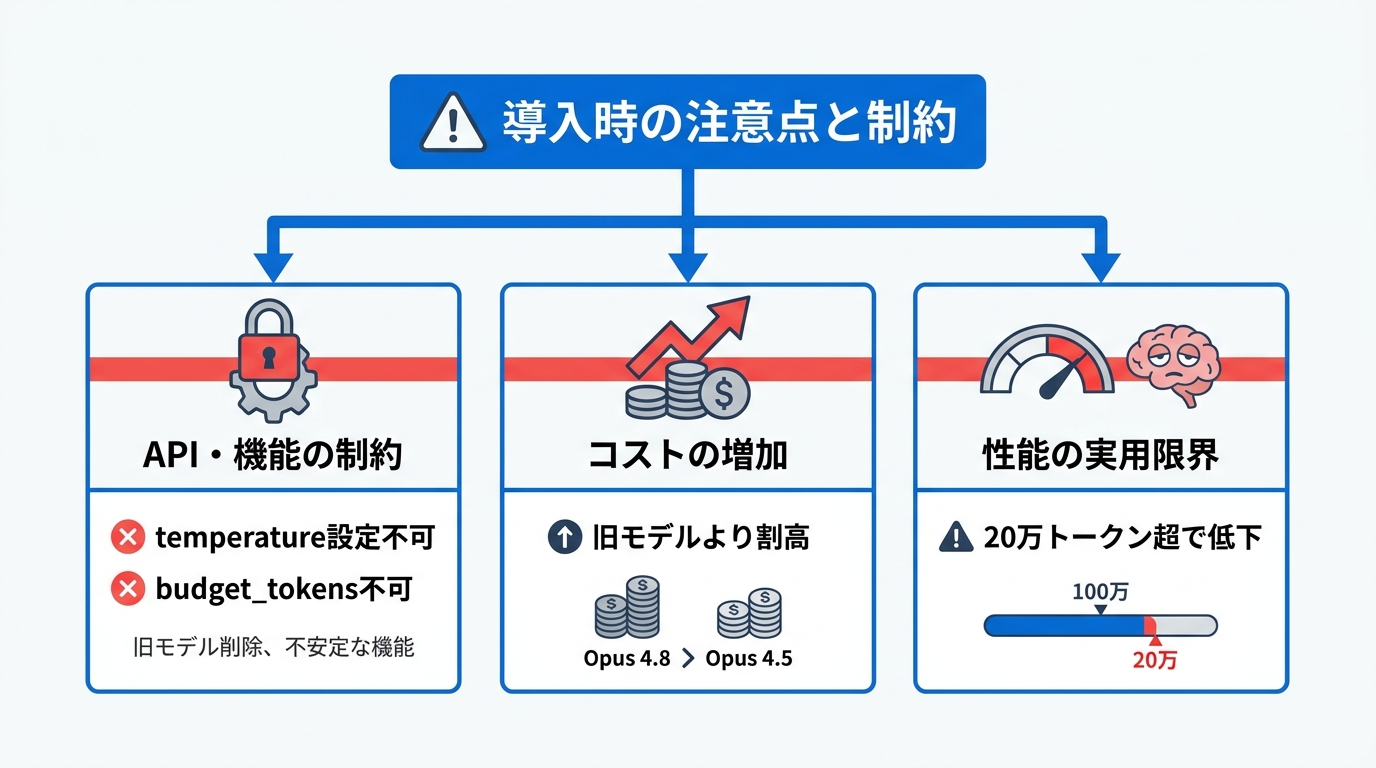
APIパラメータの制約事項
Opus 4.8では、temperature、top_p、top_kを既定値以外に設定するとHTTP 400エラーが返されます。これはOpus 4.7と同様の仕様であり、モデルの出力傾向を調整したい場合はこれらのパラメータではなくプロンプトの工夫で対応する必要があります(参照*3)。
さらに、拡張思考(extended thinking)の予算設定にも制約があります。thinking: {“type”: “enabled”, “budget_tokens”: N}を指定すると400エラーが発生するため、拡張思考の細かなトークン予算制御は利用できません(参照*3)。
Opus 4.6を本番環境で使用しているチームについては、モデルセレクタからの即時削除が行われ、ロールバック手段が提供されないとの報告があります。生成AIの導入支援をしていると、こうしたモデル廃止への対応が現場では意外と大きな負担になります。特定モデルへの依存度が高い設計を避け、モデルIDの切り替えだけで移行できる構成にしておくことを勧めています。また、Dynamic Workflowsはリサーチプレビュー段階であり、APIが不安定なため、これを基盤にマルチエージェント製品を構築する場合は正式リリース前に仕様が変更されるリスクがある点も念頭に置いてください(参照*13)。
コスト増とコンテキスト長の限界
Opus 4.8の1回あたりの呼び出しコストは、既定設定で0.20ドルから0.28ドル程度と測定されています。これはOpus 4.5の約0.13ドル、Sonnet 4.5の0.04ドルから0.12ドルと比べて明確に高い水準です(参照*8)。
コンテキスト長については、仕様上は100万トークンに対応していますが、実際の運用では20万トークンを超えるとパフォーマンスの低下が確認されています。モデルの処理速度が落ち、低いコンテキスト量であれば拾えていた参照や例外的なケースを見落とし始めるとの報告があります(参照*8)。
仕様上の上限値と実用上の性能限界には差がある点を踏まえ、長大なコンテキストを扱うタスクでは入力の分割やプロンプト設計による対処を検討する必要があります。Deep Research系の機能でも同様のことが言えますが、見た目の仕様が大きいほど、実際の限界を確認せずに設計してしまうリスクがあります。コスト面でも、呼び出し頻度と1回あたりの費用を掛け合わせた月間費用を事前に試算しておくことが、予算超過を防ぐ基本的な手段です。
おわりに
Claude Opus 4.8は、長時間のエージェント処理、ツール呼び出し精度、そして正直さの面でOpus 4.7から着実に改善されたモデルです。主要ベンチマークや法律・コードレビューといった実務領域でも数値の向上が確認されており、特に「不確実な点を自ら報告する」という正直さの改善は、AIの出力を業務に組み込む際の信頼性に直結する変化だと見ています。
一方で、APIパラメータの制約やコンテキスト長の実用上の限界、コスト増といった注意点も存在します。Dynamic WorkflowsやFast modeなどの新機能はリサーチプレビュー段階のものを含むため、本番環境への適用は仕様の安定性を見極めたうえで判断してください。新モデルへの移行は、宣伝文句ではなく自社の業務課題に照らして判断するのが、結局は遠回りのようで確実な方法です。
監修者
安達裕哉(あだち ゆうや)
デロイト トーマツ コンサルティングにて品質マネジメント、人事などの分野でコンサルティングに従事しその後、監査法人トーマツの中小企業向けコンサルティング部門の立ち上げに参画。大阪支社長、東京支社長を歴任したのち2013年5月にwebマーケティング、コンテンツ制作を行う「ティネクト株式会社」を設立。ビジネスメディア「Books&Apps」を運営。
2023年7月に生成AIコンサルティング、およびAIメディア運営を行う「ワークワンダース株式会社」を設立。ICJ2号ファンドによる調達を実施(1.3億円)。
著書「頭のいい人が話す前に考えていること」 が、82万部(2025年3月時点)を売り上げる。
(“2023年・2024年上半期に日本で一番売れたビジネス書”(トーハン調べ/日販調べ))
参照
- (*1) Introducing Claude Opus 4.8
- (*2) Claude Opus 4.8 \ Anthropic
- (*3) Claude API Docs – What's new in Claude Opus 4.8
- (*4) Amazon Web Services – Claude Opus 4.8 is now available on AWS
- (*5) Amazon Web Services, Inc. – Claude Opus 4.8 is now available on AWS
- (*6) Classmethod's 'Hands-on Experience' Technical Media | DevelopersIO – [Update] Claude Opus 4.8 is now available on Amazon Bedrock
- (*7) Harvey – Claude Opus 4.8, Now Live in Harvey
- (*8) AI Code Reviews | CodeRabbit | Try for Free – AI Code Reviews | CodeRabbit | Try for Free
- (*9) TechCrunch – Anthropic releases Opus 4.8 with new 'dynamic workflow' tool
- (*10) Claude – Introducing dynamic workflows | Claude
- (*11) SD Times – Anthropic releases Claude Opus 4.8
- (*12) Claude API Docs – Pricing – Claude API Docs
- (*13) Claude Opus 4.8 brings effort modes and parallel subagents
