
はじめに
MicrosoftがAIモデルの自社開発を本格化させています。外部モデルへの依存を減らしながら、推論・コード生成・画像・音声まで幅広い領域を自前でカバーする動きは、企業のAI活用に新たな選択肢をもたらすものです。私はこれを、単なる製品ラインナップの拡充ではなく、AIスタックの主導権を誰が握るかという、より大きな構造変化の一部として見ています。
MicrosoftはBuild 2026で、MAIシリーズとして7つの自社開発AIモデルを一挙に発表しました。蒸留に頼らず一から訓練されたこれらのモデルは、推論からマルチモーダル生成までを網羅しています。本記事では、各モデルの性能や用途、競合との比較、企業向けの活用方法まで詳しく解説します。
MAIシリーズの全体像
Build 2026での発表経緯
Build 2026ではMicrosoftが自社開発の7つのAIモデルを公開しました。MicrosoftのAI超知能チーム(Microsoft AI Superintelligence Team)は、Build 2026において自社開発の7つのAIモデルを公開し、このモデル群には、Microsoftとして初の推論モデルとなるMAI-Thinking-1が含まれています。すべてのモデルはゼロ蒸留、つまり他社モデルからの知識転写を行わず、公開データとライセンス済みの人間が作成したデータで一から訓練されています(参照*1)。
この発表は、MicrosoftがAI分野での自社能力をさらに多角化し、OpenAIのモデルへの依存を軽減する動きの一環として位置づけられています(参照*2)。私がこの動きを重要視するのは、OpenAIとの関係が将来的にどう変化しても対応できる「保険」を、Microsoftが内部で構築しつつあると読めるからです。
7つのモデルはすべて共通の基盤に立ち、同じデータ規律、同じインフラ、同じ評価枠組みを共有しています。互いに連携して動作し、日常的に利用される製品へ直接統合されることを前提に設計されています(参照*3)。
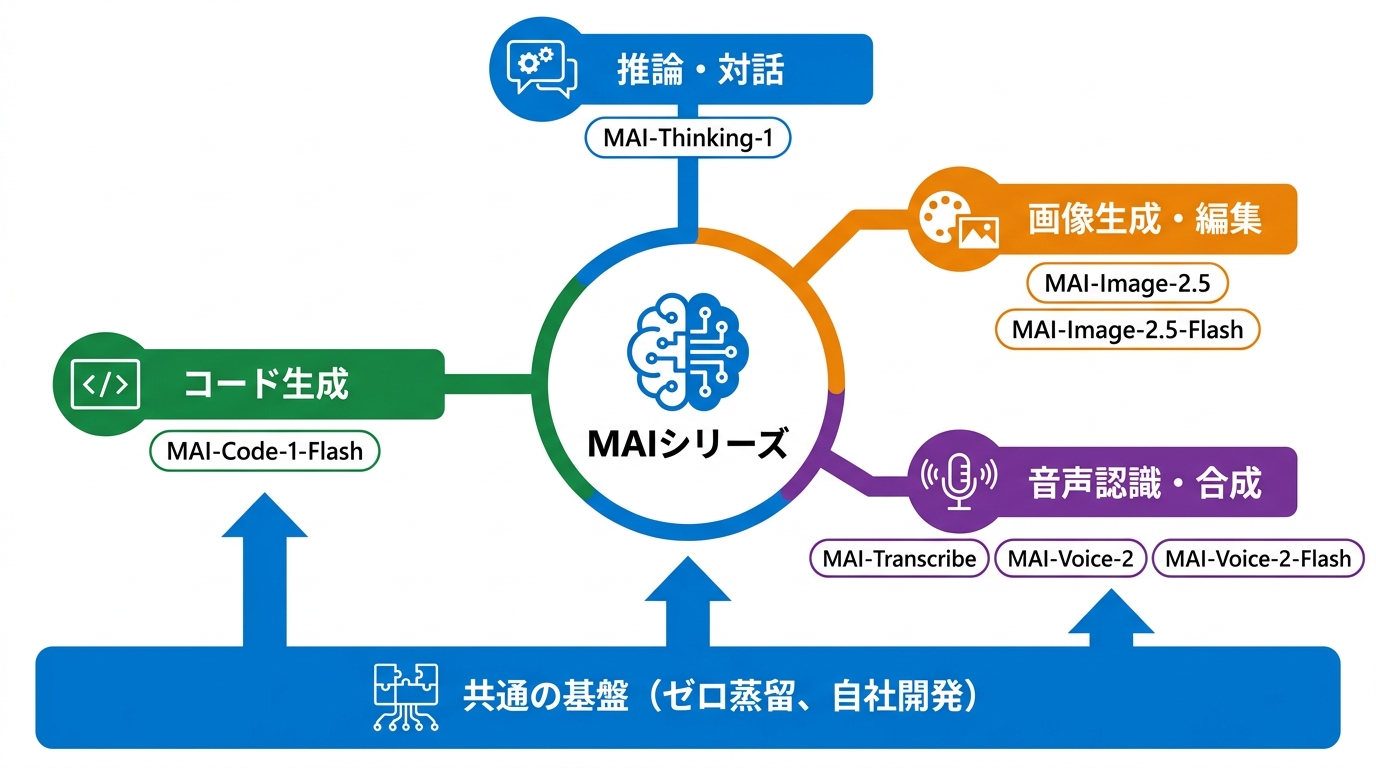
7モデルの一覧と対応モダリティ
Build 2026の時点でMicrosoft Foundryにおいてパブリックプレビューに入ったMAIモデルは4つあります。対話と推論を担う中規模言語モデルのMAI-Thinking-1、画像生成・画像編集に対応するMAI-Image-2.5、話者分離とコンテンツバイアシングを備えた音声認識モデルのMAI-Transcribe、そして多言語対応のテキスト読み上げモデルMAI-Voice-2です(参照*4)。
これら4つに加えて、コーディングに特化した軽量モデルMAI-Code-1-Flash、高速処理向けのMAI-Image-2.5-Flash、そしてMAI-Voice-2-Flashを合わせた7モデルが、MAIシリーズの全容となります。テキスト推論、コード生成、画像生成・編集、音声認識、音声合成というマルチモーダルな領域を一つのモデルファミリーで網羅している点が特徴です。
Foundry以外にも、OpenRouter、Fireworks、Basetenを通じて開発者向けに広く提供される予定であり、初めてモデルの重みを開発者自身が調整できるようになります(参照*4)。
開発思想と技術基盤
Hill-Climbing Machineの設計原則
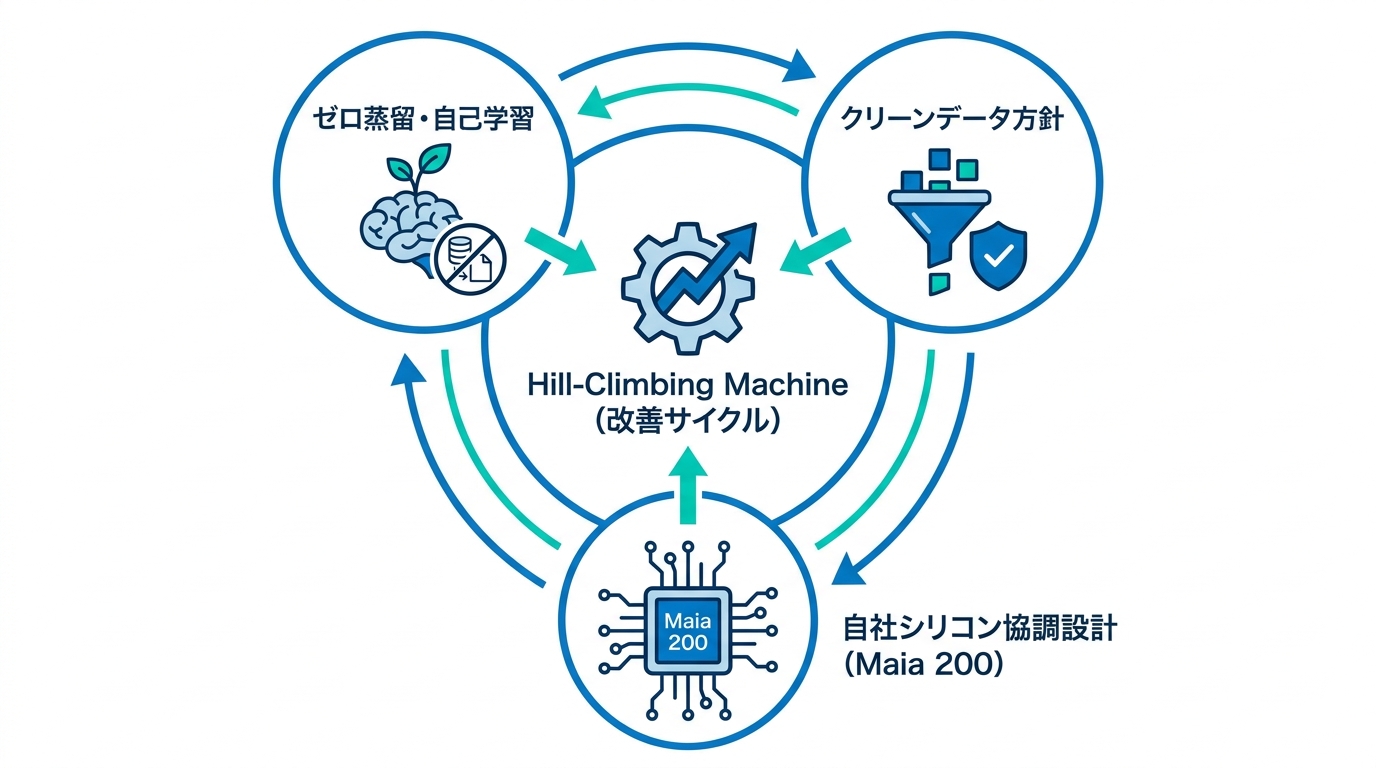
MAIシリーズの開発を貫く中核思想は、改善サイクルの仕組み(Hill-Climbing Machine)と呼ばれる考え方です。これはデータパイプライン、訓練インフラ、強化学習の環境と報酬設計、評価スイート、安全性テストを統合し、特定の領域に対するモデル開発を経験的な最適化の繰り返しに変えるプロセスを指します。MAI-Thinking-1は、このプロセスで生まれた最初のモデルです(参照*5)。
開発チームは3つの柱を掲げています。第1に、能力は継承するのではなく学習によって獲得すべきだという原則です。模倣者は教師の設計上の制約に縛られ、新しい状況への適応に苦しむため、第三者モデルからの蒸留を用いず、モデル自身に課題を真に学ばせるアプローチを採っています(参照*6)。生成AIの業務導入を支援してきた経験から言うと、モデルの操作性と再現性は、実際に企業が使い続けられるかどうかを左右する重要な要素です。この方針はその点で合理的です。
この設計思想により、各モデルは特定の用途に合わせた操作性を確保しやすくなります。既存モデルの知識を転写して速度を稼ぐ代わりに、独自の学習ループで精度と制御性を高めるという方針は、企業利用での信頼性に直結する選択といえます。
ゼロ蒸留とクリーンデータ方針
MAIシリーズの基盤モデルであるMAI-Base-1は、公開データとライセンス済みの人間が作成したデータの混合で訓練されています。事前学習時にはAIモデルが生成した合成データを一切使用しておらず、収集データ内のAI生成コンテンツの検出と除去にも取り組んでいます。さらに、オープンソースの訓練データセットも使用せず、一般的な機械学習のベンチマーク用データベースを訓練データから分離する「汚染除去」を行っています(参照*5)。
こうしたデータ方針は、企業が安心してモデルの上にサービスを構築できるよう配慮されたものです。クリーンで適切にライセンスされたデータで訓練されているため、知的財産やライセンス上のリスクを抑えた状態でモデルを利用できます。私が企業のAI導入を支援する際、「自社データを入力してよいか」「生成物の権利はどうなるか」という質問は必ずと言っていいほど出てきます。その文脈でデータクリーン性を前面に出す姿勢は、企業の意思決定者に刺さる訴求です。
自社シリコンMaia 200との協調設計
Microsoftは自社開発の推論アクセラレータ「Maia 200」を発表しています。Maia 200はTSMCの3nmプロセスで製造され、FP8/FP4対応のテンソルコアをネイティブで搭載します。メモリシステムには216GBのHBM3eを7TB/sの帯域幅で接続し、272MBのオンチップSRAMとデータ移動エンジンにより、大規模モデルへ高速にデータを供給する設計です(参照*7)。
MAIシリーズはこのMaia 200との協調設計が進められており、すでに1.4倍の効率向上が確認されています。Microsoftはこれを、同社とパートナーにとっての長期的な自立に向けた取り組みだと位置づけています(参照*3)。
モデルとハードウェアの両方を自社で持つことで、推論コストの削減や応答速度の改善を、外部の半導体ベンダーに頼らず継続的に進められる体制が整いつつあります。
各モデルの性能と用途
MAI-Thinking-1:推論モデル
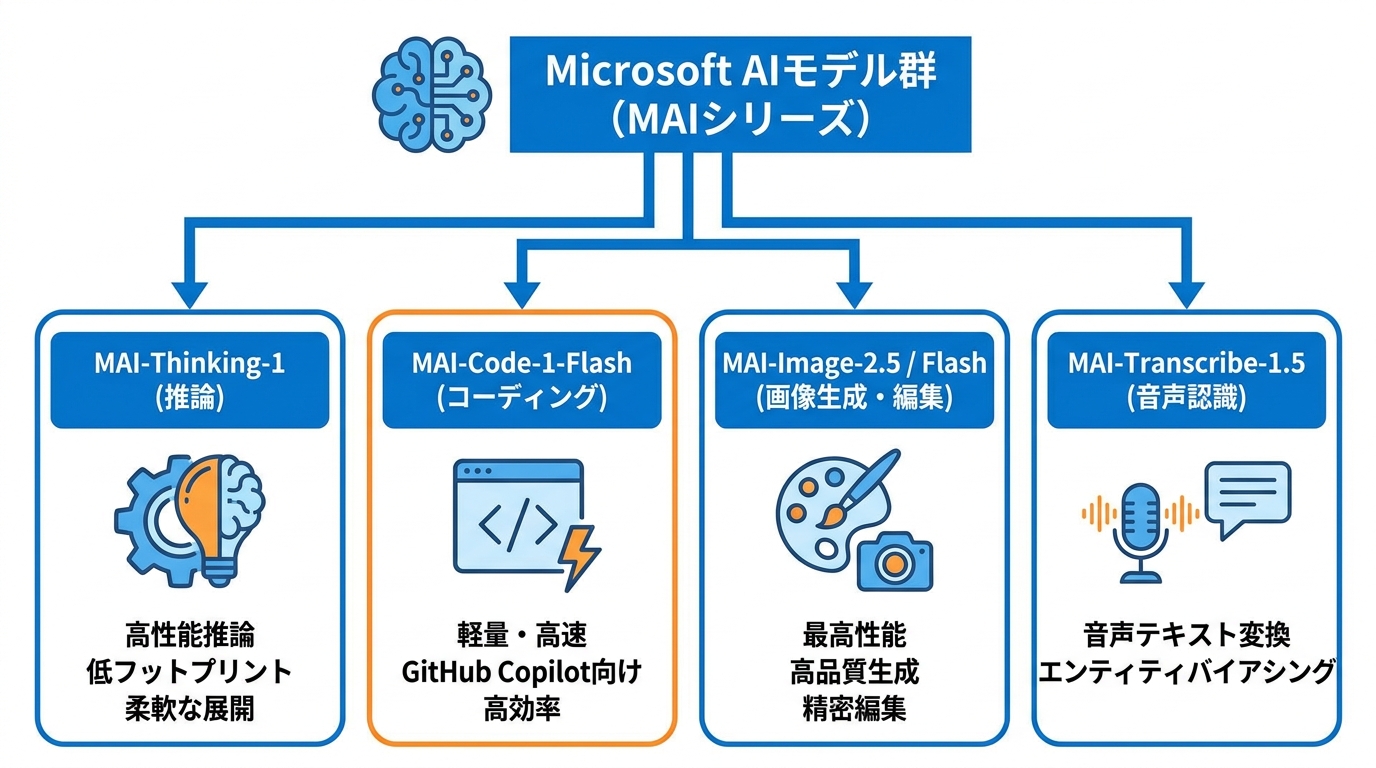
MAI-Thinking-1はMicrosoftにとって初の推論モデルであり、アクティブパラメータ数350億、総パラメータ数約1兆のスパースMixture of Experts構造を採用しています。大型モデルと比べて推論時のフットプリントが小さく、コスト面や導入場所の柔軟性で有利です(参照*6)。
数学・科学の推論力を示すAIMEベンチマークでは、2025年版で97.0%、2026年版で94.5%を達成しました。ソフトウェアエンジニアリング領域では、SWE-Bench ProにおいてClaude Opus 4.6と同等の水準に達しています(参照*5)。
モデルの規模が小さいほど、高度なコーディング支援をどこに配置できるか、どのくらいの頻度で使えるか、特別なタスクから日常的なワークフローへ移行できるかが変わります。私が生成AI活用を検証してきた中で実感しているのは、「使える場面が限られる高性能モデル」より「日常的に回せる中規模モデル」のほうが、組織全体での定着率は高いという点です。MAI-Thinking-1の設計はその方向を意識していると見ています。
MAI-Code-1-Flash:コーディング特化
MAI-Code-1-Flashは、Microsoftが開発した軽量なコーディング特化モデルです。テストされたすべての主要コーディングベンチマークでClaude Haiku 4.5を上回る成績を記録し、特にSWE-Bench Proでは51.2%対35.2%と16ポイントの差をつけています。SWE-Bench Verifiedでは最大60%少ないトークンで難度の高い問題を解いており、精度と効率の両立を実現しています(参照*8)。
GitHub Copilot向けに設計・調整された初のMicrosoft製モデルでもあり、VS Codeから順次展開が始まっています。小規模モデルとして同クラスの中で最高水準の品質を発揮し、軽量なコーディング作業に適しています(参照*9)。
トークン消費が少ないことは、応答の遅延低減やコスト削減に直結します。開発者が日常的にコード補完や修正を繰り返す場面では、この効率の良さが大きな意味を持ちます。コーディング支援ツールは、一発の回答品質だけでなく、1日に何十回も呼び出すことを前提に設計されなければならない。その観点で、MAI-Code-1-Flashのトークン効率は実務的な強みです。
MAI-Image-2.5 / Flash:画像生成・編集
MAI-Image-2.5は、Microsoftの画像モデルの中で最も高い性能を持つモデルです。Arenaの画像編集リーダーボードで2位にランクインし、Nano Banana 2を上回りました。テキストから画像を生成する領域でも3位を獲得しており、GPT-Image-1.5やNano Banana Pro 2Kを超えるArenaスコアを達成しています(参照*10)。
高品質な画像生成と精密で制御しやすい編集の両方に対応しており、開発者やMicrosoft製品に本番運用可能な画像ワークフローを提供します。最高画質を追求するMAI-Image-2.5と、高速かつ大量処理向けのMAI-Image-2.5-Flashという2つの構成で展開されています。
用途に応じて忠実度と処理速度のどちらを優先するか選べる構成は、マーケティング素材の制作から大量の商品画像生成まで、異なるニーズに対応する狙いが読み取れます。
MAI-Transcribe-1.5:音声認識
MAI-Transcribe-1.5は音声をテキストに変換する音声認識モデルで、エンティティバイアシング機能を備えています。これは業界用語や科学用語、固有名詞といった分野固有の語彙を認識しやすくする仕組みです(参照*11)。
43言語を対象としたFLEURSベンチマークでの平均単語誤り率(WER)は4.86%です。比較対象となるElevenLabs Scribe v2が5.53%、OAI-transcribeが5.73%、Google Gemini-flash-liteが5.63%であるため、テスト対象の中で最も低い誤り率を達成しています(参照*11)。
多言語環境での正確な書き起こしに加え、専門用語の認識精度を高められる点は、医療や法律など特定分野の文書作成で役立つ可能性があります。
MAI-Voice-2 / Flash:音声合成
MAI-Voice-2はテキストを音声に変換するテキスト読み上げ(TTS)モデルで、多言語に対応し、音声クローン機能も備えています(参照*4)。
先行バージョンのMAI-Voice-1のモデルカードによると、このモデルファミリーは高忠実度で自然かつ表現力豊かな音声を生成します。人間に近い抑揚やリズム、感情の微妙なニュアンスを捉え、臨場感のある対話体験を実現します。提供されたテキストに忠実に従いながら、発話ごとに感情を制御できる仕組みも取り入れられています(参照*12)。
MAI-Voice-2-Flashは高速処理向けのバリエーションとして位置づけられており、品質と速度の要件に応じて使い分ける構成です。カスタマーサポートの音声応答や教育コンテンツなど、大量の音声を生成する場面での活用が想定されます。
競合モデルとの比較と選定基準
推論・コード領域の性能比較
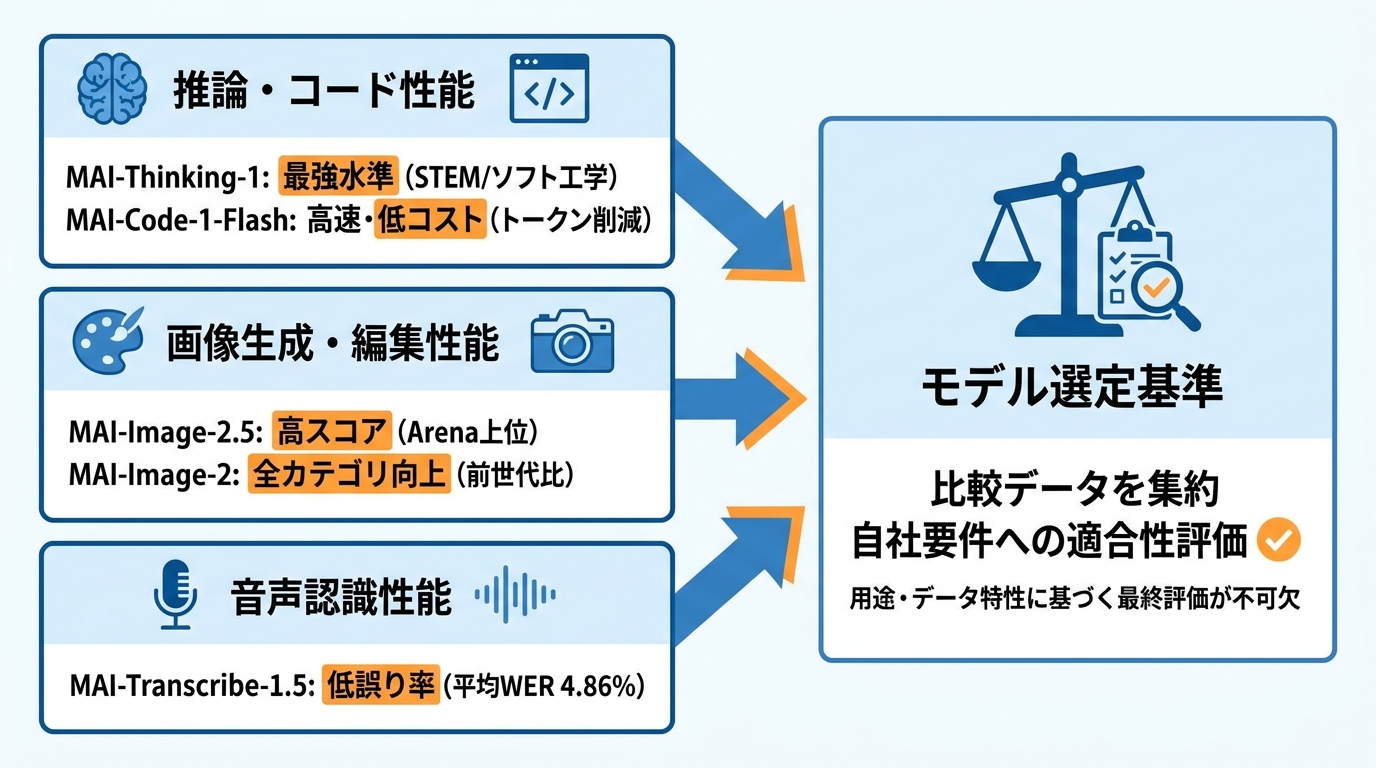
MAI-Thinking-1は350億のアクティブパラメータ/1兆の総パラメータというMoE構成で、STEM推論とソフトウェアエンジニアリングのタスクにおいて同じ重量クラスで最強水準のモデルの一つに位置づけられています。第三者モデルからの蒸留なしで訓練された点が、独自の操作性を確保する上での差別化要素となっています(参照*5)。
コーディング領域では、MAI-Code-1-Flashがより難しい問題を最大60%少ないトークンで解決しています。これは応答の遅延低減、コスト削減、トークンあたりの成果向上につながり、対話的なワークフローの体感速度も改善します(参照*8)。
GitHub Copilotの年間プランにおけるMAI-Code-1-Flashのモデル乗数は0.33(プロモーション価格)であり、利用コストの面でも小規模モデルとしての経済性が反映されています(参照*13)。
画像・音声領域のベンチマーク
画像生成の領域では、MAI-Image-2.5がArenaスコアでGPT-Image-1.5やNano Banana Pro 2Kを超え、テキストから画像生成で3位、画像編集で2位にランクインしています(参照*10)。
前世代モデルとの比較では、MAI-Image-2のArenaスコアが全カテゴリでMAI-Image-1を上回っています。総合スコアはMAI-Image-2が1190±8に対しMAI-Image-1が1093±4で、フォトリアリスティック画像、商業デザイン、3Dモデリング、アニメ、ポートレート、テキスト描画のいずれでも向上が見られます(参照*14)。
音声認識のMAI-Transcribe-1.5は43言語の平均WERで4.86%を記録しており、テスト対象の競合モデルより低い誤り率を示しています。画像・音声ともにベンチマーク上は競争力のある位置にありますが、ここで注意が必要です。ベンチマーク上の数字と、実際の業務での適合性は別問題です。私自身、複数のAIモデルを同じ業務課題で試してきた経験から言うと、スコアが高いモデルが自社の用途に合うとは限りません。自社のデータ特性、言語環境、専門用語の頻度を踏まえた実環境での検証が欠かせません。
Frontier Tuningと企業活用
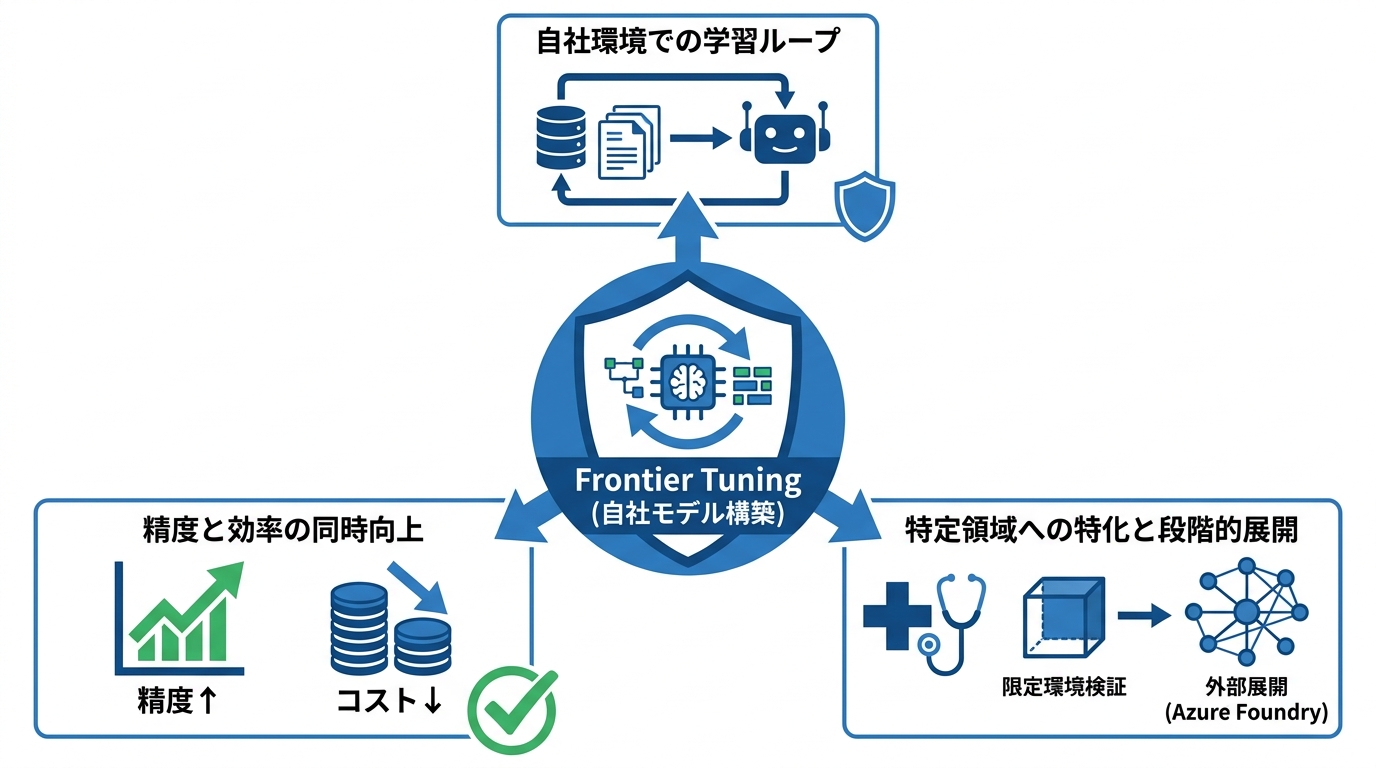
強化学習による自社モデル構築
Frontier Tuningは、企業のコンプライアンス境界の中で強化学習を適用し、エージェントが実際の業務プロセスを学ぶ仕組みです。自社のデータ、専門知識、ワークフローを活用することで、エージェントが稼働するほど精度が磨かれる学習ループが形成されます。現在プライベートプレビューとして提供されています(参照*1)。
Microsoft社内や顧客企業での実績として、MAIをチューニングしたExcel向けモデルはGPT 5.4と同等の性能を発揮しつつ、最大10倍の効率を達成しています。McKinseyの厳格な企業基準に合わせて調整した場合にも、テストされた全モデル中で最高の勝率をおよそ10分の1のコストで記録しています(参照*3)。
汎用モデルをそのまま使う場合と比べて、業務に特化したチューニングを施すことで精度とコスト効率を同時に引き上げられる事例が出始めています。ただし、私が導入支援の現場で何度も見てきたのは、「チューニングすれば解決する」という過信です。Frontier Tuningの恩恵を受けるには、まず業務を言語化し、評価基準を定め、どの出力が良くてどれが悪いかを判断できる体制を自社で整えることが前提になります。
Mayo Clinicなどの先行事例
医療分野では、臨床推論とヘルスケアの幅広いユースケースに特化したモデルの開発が進められています。このモデルは、汎用AIでは到達できない水準の臨床推論を目指して設計されています(参照*3)。
まずMayo Clinicの環境内に展開され、早期かつ正確な診断や治療計画の立案を含む幅広い機能の実現が見込まれています。検証を経た後は、Azure Foundryを通じて他の医療機関にも提供される予定であり、Mayo Clinicの専門知識をより多くの組織が活用できる形を目指しています(参照*3)。
特定領域の専門家と協力してモデルを鍛え、まず限定環境で検証してから外部に展開するという段階的なアプローチは、信頼性が求められる医療のような分野で今後の参考になる進め方です。私はAI導入プロジェクトで「いきなり全社展開」を狙って失敗する事例を繰り返し見てきました。小さく始め、検証し、拡大するというプロセスはAI全般に共通する原則です。
導入方法と注意点
Foundryでのデプロイ手順
MAIモデルはMicrosoft Foundry Modelsの一部として提供されており、Azureが販売する安全で企業向けのアクセス環境を通じて利用できます。画像モデルの場合はテキストから画像を生成する機能に加え、一部のモデルでは画像を入力とした編集にも対応しています(参照*15)。
Foundry以外にも、OpenRouter、Fireworks、Basetenといった外部プラットフォーム経由でも利用可能です。開発者が初めてモデルの重みを自分で調整できるようになる点も、今回の展開における大きな特徴です(参照*4)。
複数のデプロイ先が用意されていることで、既存のインフラや開発環境に合わせた選択が可能になります。導入前には、自社のセキュリティ要件やデータ管理方針との整合性を確認しておくことが必須です。企業のAI導入相談を受けていると、プロンプトやモデル選定より先に、情報システム・法務・コンプライアンスとの調整に時間がかかるケースがほとんどです。技術的な準備と組織的な準備を並行して進める必要があります。
安全性・責任あるAIの留意事項
MAI-Thinking-1の開発過程では、開発の初期・中期・後期にわたる15回の検証を通じて、レッドチームが25のポリシーカテゴリにまたがる2,170以上の目標ベースの敵対的シナリオを実行しています(参照*5)。
画像生成モデルについては、データフィルタリングなどの技術的な緩和策を講じていても、ユーザーの入力次第で有害または予期しないコンテンツを生成するリスクがあると明記されています。暴力的・性的なコンテンツ、著名人の描写、商標や保護された素材の複製といったリスク領域が具体的に挙げられています(参照*14)。
モデルを本番環境に組み込む際には、こうした既知のリスク領域を踏まえた上で、出力のフィルタリングや利用規約の設計など、自社側での追加的な安全策を検討する必要があります。AIの出力をそのまま社外に出すことは、文章生成の問題というより、リスク管理の問題です。誰が確認したのか、根拠はどこにあるのか、間違っていた場合の責任範囲はどこかを、あらかじめ決めておくことが前提になります。
おわりに
MicrosoftはBuild 2026でMAIシリーズ7モデルを発表し、推論・コード生成・画像・音声というマルチモーダルな領域を自社開発モデルで本格的にカバーする姿勢を示しました。ゼロ蒸留とクリーンデータによる訓練、自社シリコンMaia 200との協調設計、そしてFrontier Tuningによる企業ごとの最適化という一連の仕組みが、MAIシリーズの基盤を形成しています。私が注目するのは、モデルの性能そのものより、この「モデルとハードウェアとチューニング基盤を一体で持つ」という体制の完成度です。これは単なる製品発表ではなく、Microsoftが生成AIの主導権を自社で持ち続けるための構造設計です。
各モデルの性能やコスト効率は用途によって異なります。ベンチマーク上の数字を参考にしつつも、自社の業務要件・既存インフラ・組織体制との相性を実環境で確かめてから、導入の優先順位を決める。そのプロセスを省略することが、AI活用プロジェクトが途中で止まる最大の原因です。
監修者
安達裕哉(あだち ゆうや)
デロイト トーマツ コンサルティングにて品質マネジメント、人事などの分野でコンサルティングに従事しその後、監査法人トーマツの中小企業向けコンサルティング部門の立ち上げに参画。大阪支社長、東京支社長を歴任したのち2013年5月にwebマーケティング、コンテンツ制作を行う「ティネクト株式会社」を設立。ビジネスメディア「Books&Apps」を運営。
2023年7月に生成AIコンサルティング、およびAIメディア運営を行う「ワークワンダース株式会社」を設立。ICJ2号ファンドによる調達を実施(1.3億円)。
著書「頭のいい人が話す前に考えていること」 が、82万部(2025年3月時点)を売り上げる。
(“2023年・2024年上半期に日本で一番売れたビジネス書”(トーハン調べ/日販調べ))
参照
- (*1) The Official Microsoft Blog – Microsoft Build 2026: Be yourself at work
- (*2) Yahoo Finance – Microsoft debuts in-house AI models as it looks to ease reliance on OpenAI
- (*3) Microsoft AI – Building a hill-climbing machine: Launching seven new MAI models
- (*4) Microsoft Foundry Blog – What's new in Microsoft Foundry
- (*5) https://microsoft.ai/wp-content/uploads/2026/06/main_20260602_2.pdf
- (*6) Microsoft AI – Introducing MAI-Thinking-1
- (*7) The Official Microsoft Blog – Maia 200: The AI accelerator built for inference
- (*8) Microsoft AI – Introducing MAI-Code-1-Flash
- (*9) The GitHub Blog – MAI-Code-1-Flash is now available for GitHub Copilot
- (*10) Microsoft AI – MAI-Image-2.5 launches at No. 2 for image editing on Arena
- (*11) https://microsoft.ai/pdf/MAI-Transcribe-1.5-Model-Card.PDF
- (*12) https://microsoft.ai/pdf/MAI-Voice-1-Model-Card.pdf
- (*13) GitHub Docs – Model multipliers for annual plans on request-based billing (legacy)
- (*14) https://microsoft.ai/pdf/MAI-Image-2-Model-Card.pdf
- (*15) Docs – Deploy and use MAI image models in Microsoft Foundry – Microsoft Foundry
