
はじめに
ChatGPTを日常的に使っていると、以前話した内容をもう一度説明し直す手間が気になることがあります。私自身、毎日のようにChatGPTを文章作成や調査に使っていますが、「先週も同じ前提を伝えたのに」という場面は決して少なくありませんでした。利用頻度が高い人ほど、この繰り返しのコストは蓄積されていきます。
OpenAIが展開を始めた新しいメモリの仕組み「Dreaming」は、過去の会話から文脈を自動で合成し、常に最新の状態に保つことでこの課題を解消しようとする機能です。本記事では、Dreamingの定義や仕組み、具体的な活用場面、プライバシー面の注意点、そして実務的な使い方まで順を追って説明します。
Dreamingの定義と背景
ChatGPTメモリ機能の進化
ChatGPTのメモリ機能は段階的に進化してきました。2024年に導入された保存メモリ(Saved Memories)は、ユーザーが明示的に「これを覚えて」と指示した内容だけを保持する仕組みでした。2025年にはSaved Memoriesに加えて初期版のDreaming(V0)が補助的に導入され、手動のメモに加えてバックグラウンドでの学習が加わりました。そして2026年に展開が始まったDreaming V3は、完全に自動化された自己更新型のメモリへと進化し、主要なシステムとして位置づけられています(参照*1)。
Dreamingへの移行は、メモリの仕組みが「ユーザーが自分で管理するもの」から「システムが自動で構築・維持するもの」へと変わった点にあります。つまり、ユーザーの意識的な操作がなくても、会話の流れから文脈が抽出され、次の会話に反映される設計です。
Dreamingが生まれた理由
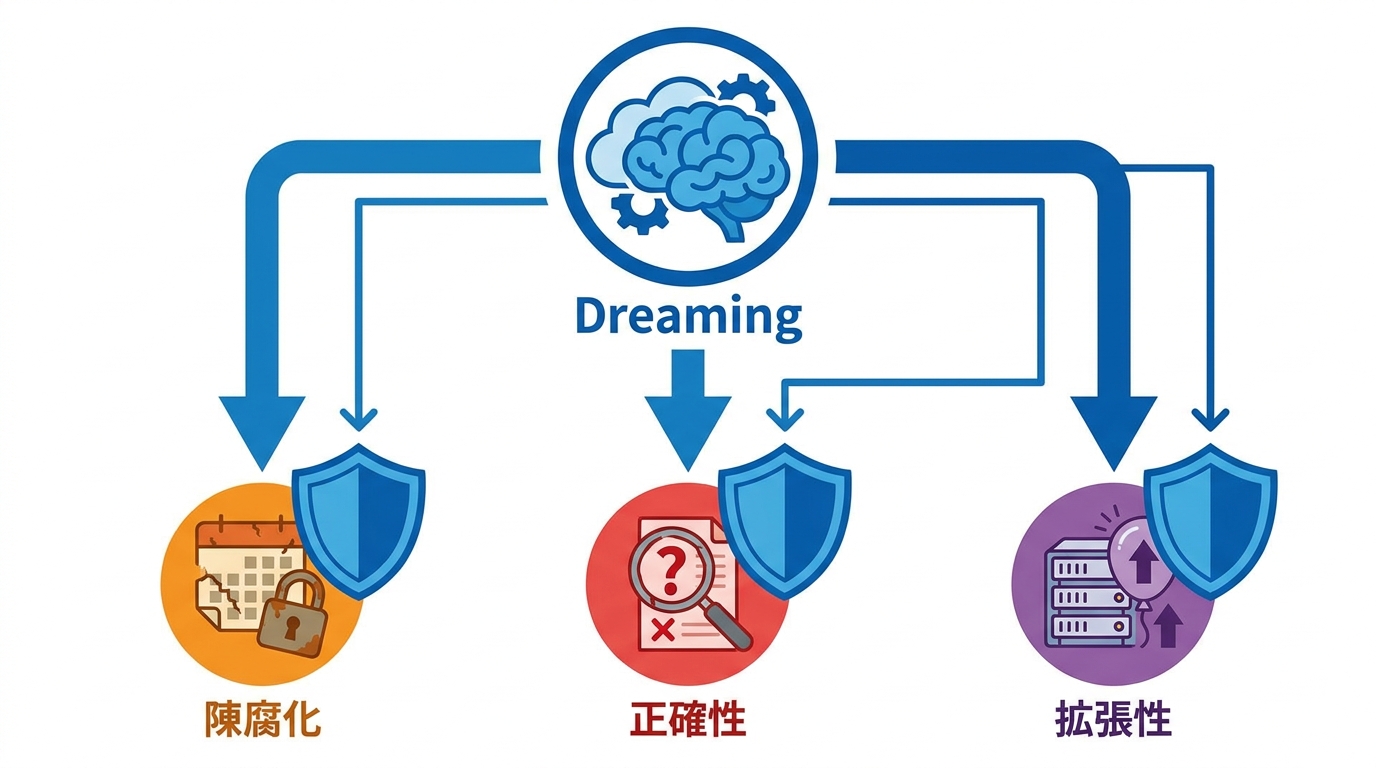
Dreamingは、ChatGPTにおけるメモリ合成のためのより高性能かつ拡張性の高いシステムと説明されています。このシステムは、数億人規模のユーザーと数年単位の利用期間においてメモリを適用するときに生じる3つの大きな課題、すなわち「陳腐化」「正確性」「拡張性」に対処する目的で開発されました(参照*2)。
たとえば、転職したのに古い職業情報が残り続ける陳腐化、事実と異なる内容が記憶される正確性の問題、そしてユーザー数の急増に耐えうるインフラの拡張性は、いずれも従来のSaved Memoriesだけでは対応が難しい領域でした。Dreamingはこれら3つの課題を同時に解決するために設計されています。
Dreamingの仕組みと特徴
バックグラウンド記憶合成の全体像
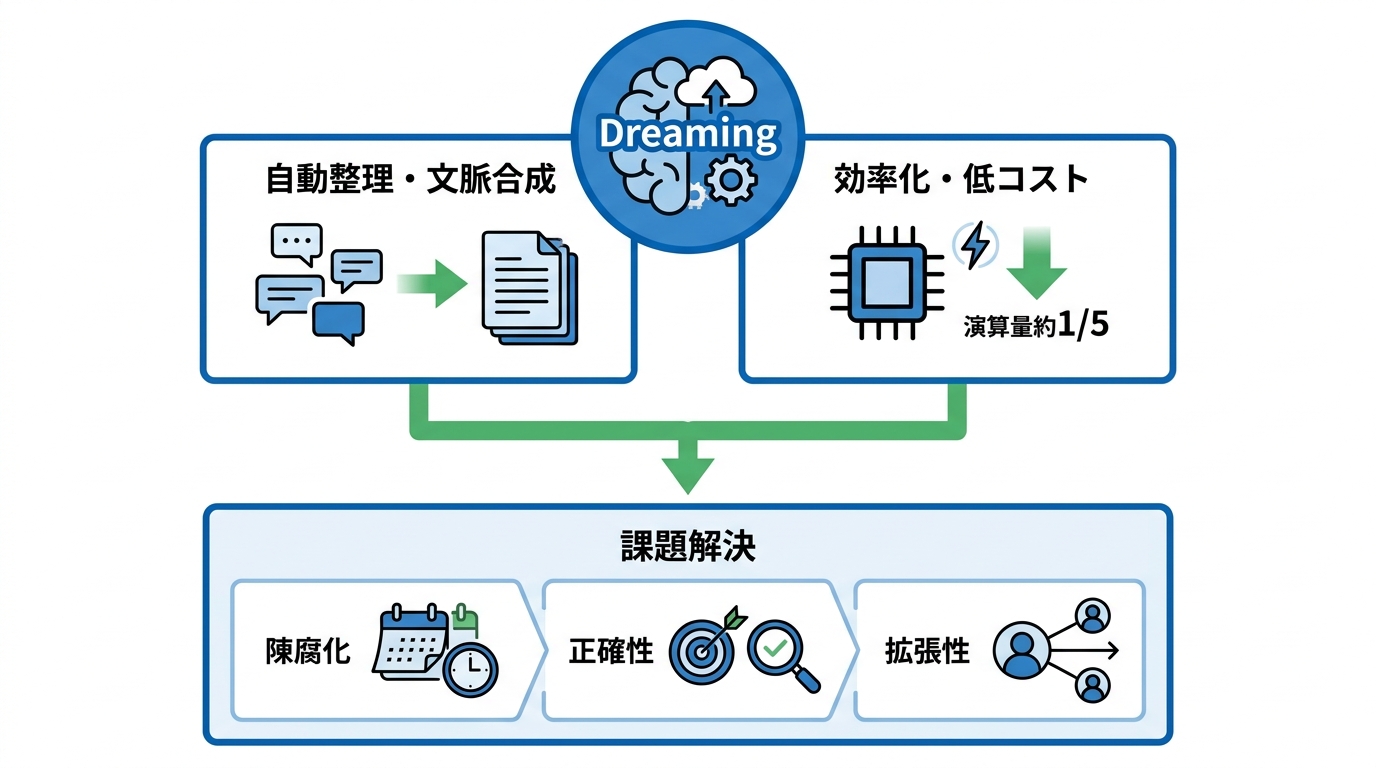
Dreamingは、ユーザーが「これを覚えて」と指示しなくても、会話履歴を参照しながらバックグラウンドで自動的にメモリを整理する仕組みです。会話の中で自然に出てきた文脈をメモリに取り込みやすくする点が特徴で、明示的な記憶リクエストだけに頼らない設計になっています(参照*2)。
具体的には、過去のやり取りから文脈を合成し、次の会話が始まるときに最も新しく関連性の高い情報が反映された状態を自動で用意します(参照*1)。さらに、2026年のアップデートでは計算処理の効率も向上しており、従来と比べて演算量を約5分の1に削減したことで、無料プランのユーザーへの展開も可能になりました(参照*3)。
陳腐化・正確性・拡張性への対応
Dreamingが対処する3つの課題は「陳腐化」「正確性」「拡張性」です。まず「陳腐化」とは、時間が経つにつれて記憶された情報が現実と合わなくなる問題です。たとえばユーザーが引っ越しや転職をした場合、古い情報のまま回答が生成されると的外れな結果になります。Dreamingでは会話履歴を継続的に参照し、情報を自動更新することで鮮度を保つ仕組みをとっています。
次に「正確性」について、メモリは単なる保存の仕組みではなく、何を保存し何を捨てるか、適切なタイミングで適切な情報を取り出せるか、そして陳腐化やドリフト、汚染、過度な一般化を避けられるかという品質管理が本質的な難しさだと指摘されています(参照*4)。そして「拡張性」については、数億人のユーザーに対して個別のメモリを維持しながら計算コストを抑える必要があり、演算量を約5分の1に減らした効率化がこの課題への直接的な回答となっています。
メモリサマリーと操作方法
メモリサマリーページの機能
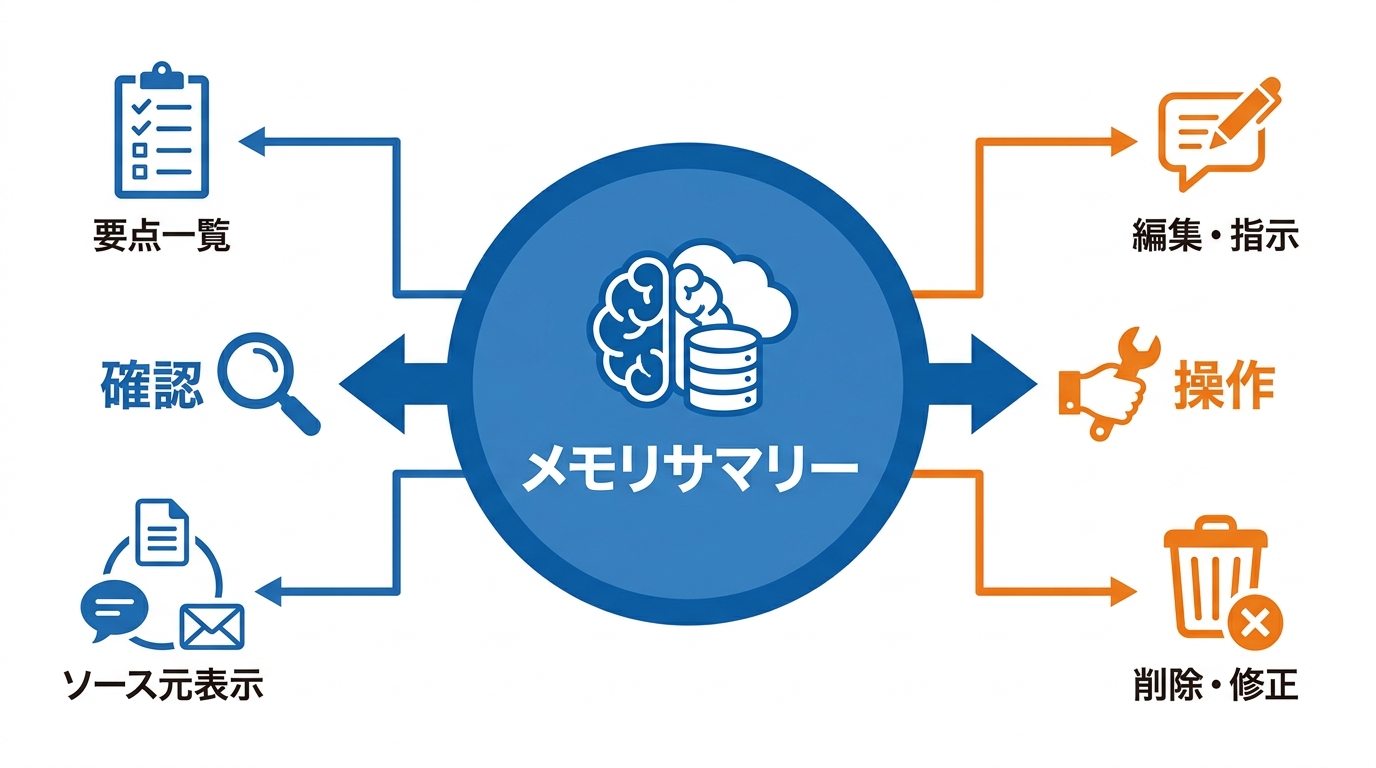
Dreamingによって合成されたメモリは、メモリサマリーページを通じて確認できます。このページでは、ChatGPTが自分について何を把握しているかの要点をすばやく一覧でき、情報の追加や更新、さらにはどの話題をいつ持ち出すべきかといった指示を与えることも可能です。ただし、メモリサマリーは重要な情報を表示するものの、ChatGPTが記憶しているすべてを網羅しているわけではないとFAQで示されています(参照*2)。
加えて、回答がどの記憶に基づいてパーソナライズされたかを確認できるメモリソース(memory sources)機能も導入されています。回答の下にあるソースアイコンをタップすると、保存されたメモリ、過去のチャット、カスタム指示といった関連情報の出どころを表示できます(参照*5)。
メモリの確認・編集・削除手順
メモリの管理はメモリサマリーページから行えます。新しいメモリシステムでは、ChatGPTが覚えている内容をメモリサマリーで確認し、文脈がどのように使われているかをより細かく見たうえで操作できます(参照*6)。
情報が古くなった場合や誤りがある場合には、該当するメモリを修正したり、削除したり、「関連性なし」とマークしたりすることが可能です。PlusやProユーザーの場合は、ライブラリ内のファイルや接続したGmailアカウントからの参照メールもソースとして表示されるため、それぞれの情報源に対して個別に操作を行えます(参照*5)。
主なユースケース
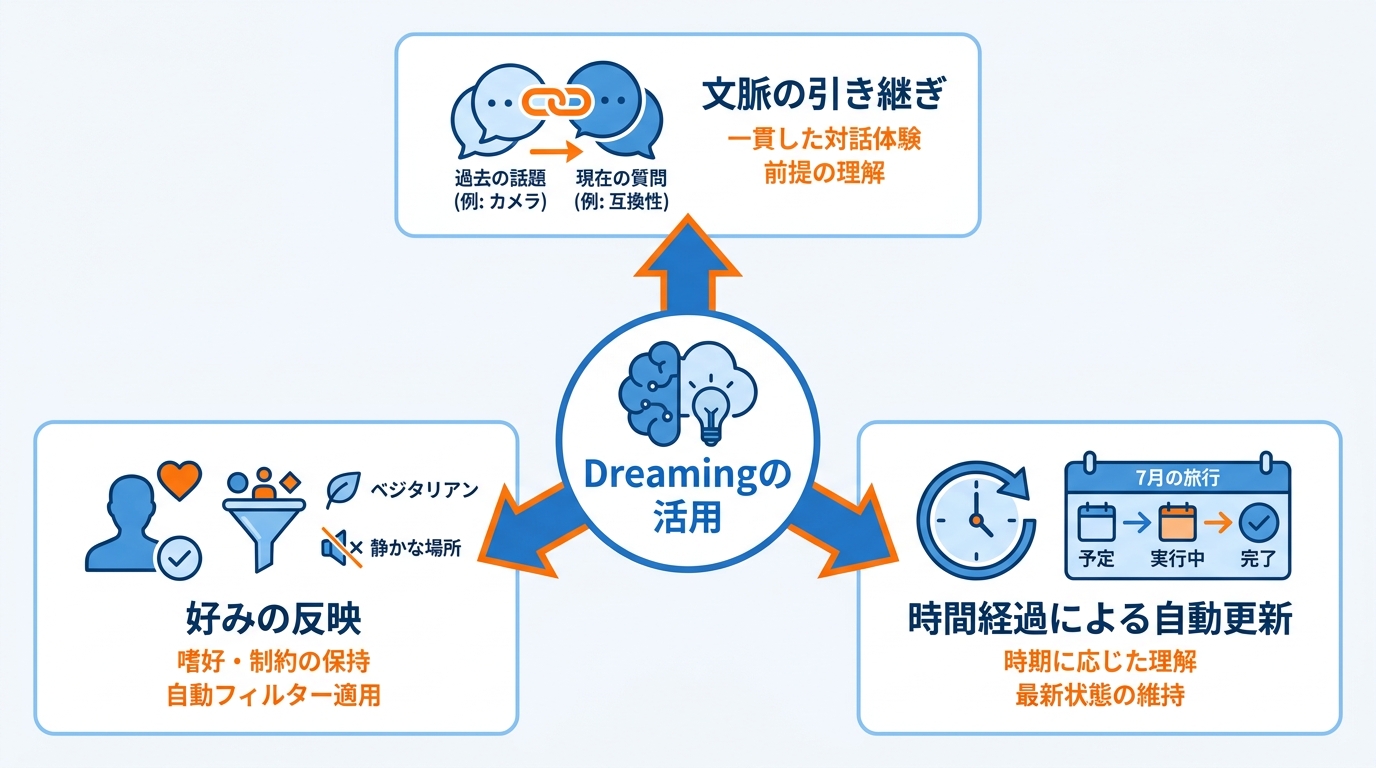
文脈の引き継ぎと好みの反映
Dreamingの活用場面は大きく分けて「文脈の引き継ぎ」と「好みの反映」の2つがあります。文脈の引き継ぎの例として、カメラ機材を一度話題にしただけで、翌週に互換性のあるアクセサリーを尋ねたときには既にユーザーの機材構成を踏まえた回答が得られるケースが挙げられています(参照*1)。
好みの反映では、ベジタリアンであること、静かなレストランを好むこと、エアコンが効いたホテルを選びたいことなど、ユーザーの嗜好や制約条件をメモリが保持し、推薦のたびにそれらを自動的にフィルターとして適用します。毎回同じ条件を伝え直す手間がなくなるため、繰り返し利用する場面ほど恩恵が大きくなる設計です。
時間経過に伴う記憶の自動更新
Dreamingの強みの1つは、時間の経過に合わせてメモリを自動的に更新できる点です。たとえばユーザーが「7月に旅行を計画している」と伝えた場合、メモリはその旅行が「これからの予定」なのか、「まさに実行中」なのか、「すでに終わった」のかを時期に応じて理解し、それに合った回答を返すようになります(参照*6)。
改善の重点領域としては、有用な文脈の引き継ぎ、好みや制約条件の追従、そして時間の経過に伴う最新状態の維持という3つが挙げられています(参照*7)。状況が変化しても古い情報のまま回答が返ってくるという従来の不満に対して、Dreamingは時間軸を意識した記憶管理で応えようとしています。
プライバシーとデータ管理
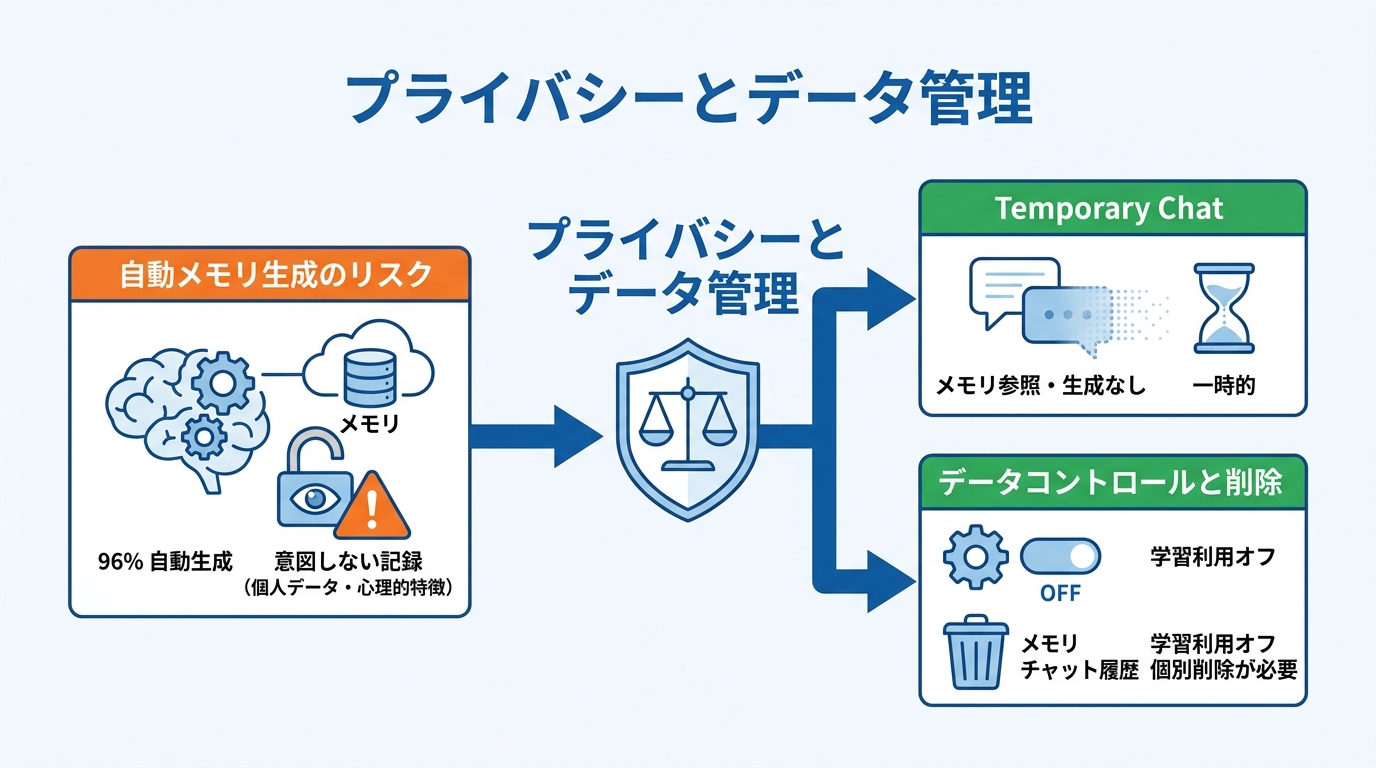
記憶される情報の範囲とリスク
自動でメモリが生成される仕組みには、利便性と引き換えにプライバシー上の懸念も伴います。ChatGPTのメモリに関する分析では、データセット内のメモリの96%がシステム側によって一方的に生成されており、ユーザーの主体的な関与なしに記憶が形成されている可能性が指摘されています。さらに、メモリの28%にはGDPR(EU一般データ保護規則)が定義する個人データが含まれ、52%にはユーザーの心理的な特徴に関する情報が含まれていたという分析結果もあります(参照*8)。
一方で、メモリの84%は実際の会話内容に直接基づいており、会話を忠実に反映しているとも報告されています。つまり、でたらめな情報が記憶されるリスクは低いものの、ユーザーが意図しない範囲の個人情報や心理的傾向までもが記録される可能性がある点は認識しておく必要があります。
Temporary Chatとデータコントロール
メモリに情報を残したくない場面では、一時的なチャット(Temporary Chat)を使う方法があります。一時的なチャットでは既存のメモリが参照されず、新しいメモリも生成されません(参照*2)。
また、設定画面のデータコントロールから「Improve the model for everyone」をオフにすると、過去のチャットや保存されたメモリがモデル改善に利用されなくなります。なお、Business、Enterprise、Eduプランの顧客データは既定では学習に使用されません。ただし、パーソナライズに使われた情報を完全に消したい場合は、保存されたメモリ、チャット、アーカイブ済みチャット、ファイル、メモリサマリー、接続アプリなど、情報が存在する場所ごとに個別に削除する必要があります。
従来メモリや競合との比較
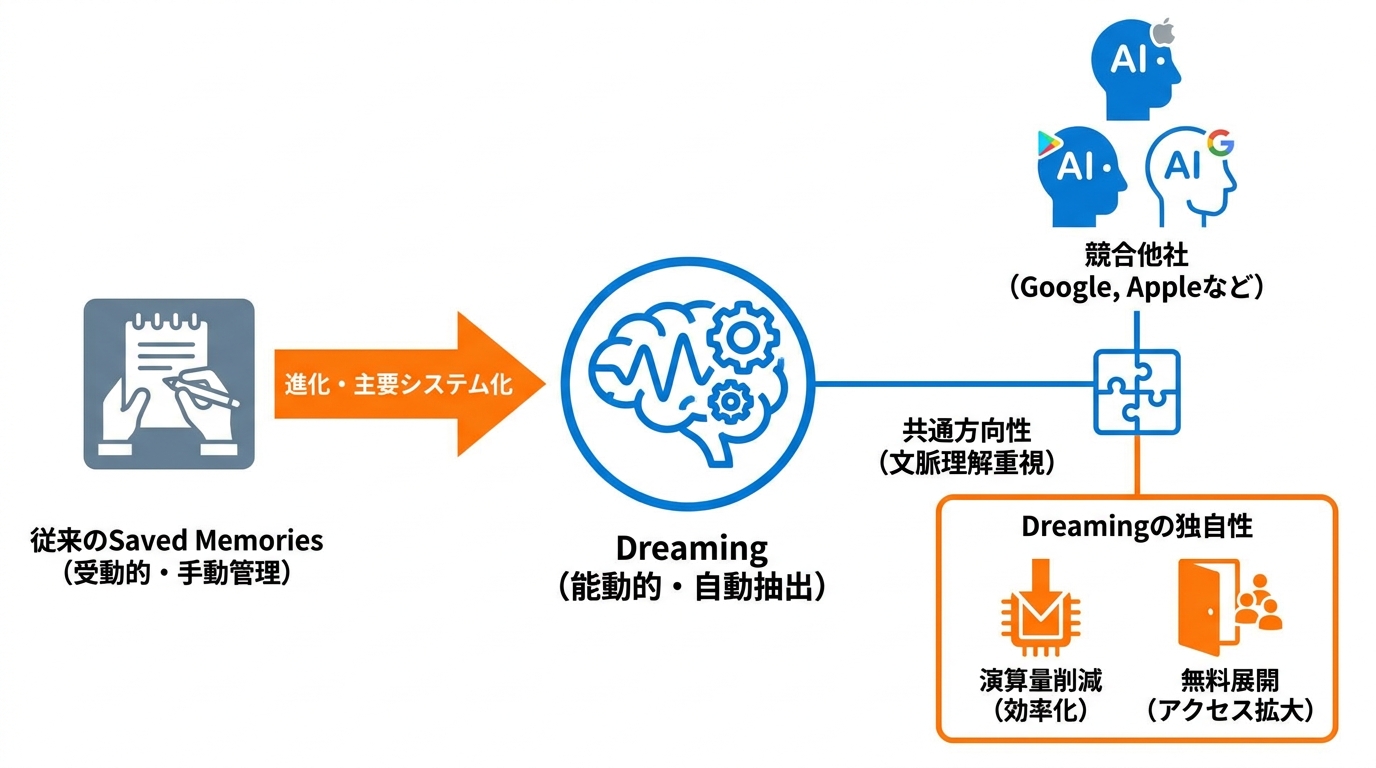
Saved Memoriesとの違い
従来のSaved Memoriesは、ユーザーが明示的に指示した内容だけを保存する受動的な仕組みでした。2025年4月に登場したDreamingの初期版はSaved Memoriesを補完する位置づけでしたが、2026年に展開が始まった現行版では主要システムとして位置づけられています(参照*1)。
この変化の本質は、記憶の管理主体がユーザーからシステムへ移行した点にあります。Saved Memoriesでは「覚えてほしいこと」をその都度伝える手間が必要でしたが、Dreamingでは会話の流れから自動的に文脈が抽出・合成されます。手動管理が不要になった反面、何が記憶されているかを定期的にメモリサマリーで確認する習慣が求められるようになりました。私の感覚では、AIツールは「便利になるほど、ユーザーの確認コストが別の形で残る」という構造を持っています。Dreamingも例外ではありません。
他社AIアシスタントとの比較
AIがユーザーを理解する方向性は、各社で共通しつつあります。GoogleのGemini、Apple Intelligenceなど各社が同じ方向を目指しており、純粋な処理能力よりも「文脈を知っているかどうか」が使い勝手を大きく左右するという認識で一致しつつあります。箇条書きと長文のどちらを好むか、マラソンのトレーニング中であるか、転職したばかりかといった個別の事情を把握しているAIは、毎回ゼロから始まる高性能なAIよりも実用的だという点は、私も実感として同意します(参照*9)。
ChatGPTのDreamingは、演算量を約5分の1に削減しつつ無料ユーザーへの展開にも踏み切った点で、パーソナライズ機能を幅広い層に届けるアプローチをとっています(参照*3)。ただし、各社のメモリ機能を選ぶ際に重要なのは、スペックよりも「自分の業務フローに定着するか」です。機能として優れていても、ユーザーが確認・修正の習慣を持てなければ、誤った記憶が回答の精度を下げる要因になりかねません。
利用時の注意点と失敗例
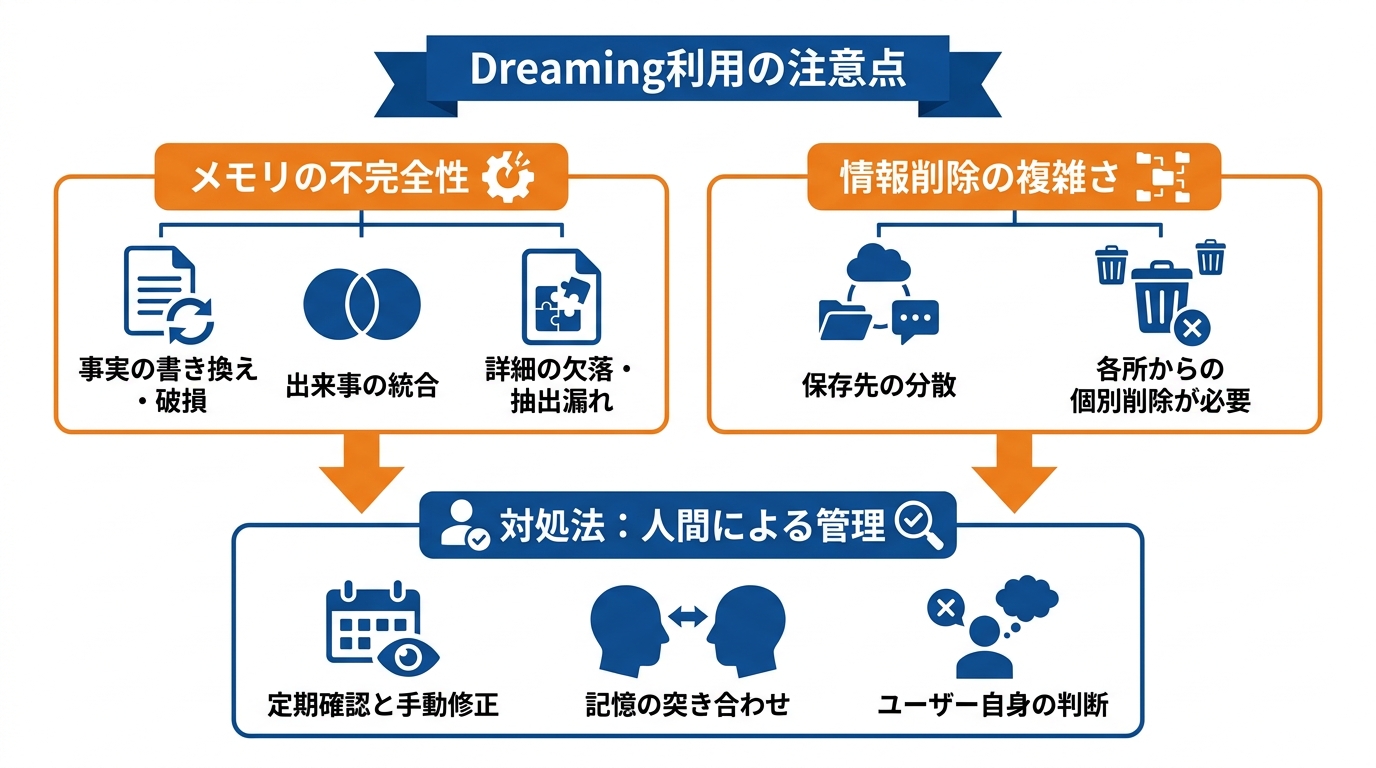
メモリの不完全性と対処法
Dreamingは強力な仕組みですが、メモリが完全に正確であるとは限りません。メモリの更新時に、以前は正しかった事実が書き換えられて壊れるケース、繰り返し発生した別々の出来事が1つに統合されてしまうケース、後から比較や再確認に必要な関係性や出典の詳細が削ぎ落とされるケースが報告されています。また、事実の抽出時にも、相対的な日付、時間に関する条件、否定形の好み、短い評価コメント、特定の感情表現、構造化された計画、アシスタントが提供したリストなど、一定の形式の情報がメモリに取り込まれにくいという課題があります(参照*10)。
こうした不完全性に対処するには、メモリサマリーを定期的に確認し、誤った情報や欠落した情報を手動で修正・補足することが有効です。自動化されたシステムだからといって完全に任せきりにせず、自分の記憶とChatGPTの記憶を突き合わせる作業が精度を維持するうえで欠かせません。私がAI導入支援の現場で繰り返し伝えているのも、この点です。「AIが候補を出す、人間が確認・補正する」という役割分担を崩すと、便利なはずのツールが誤情報の温床になります。
情報削除の複雑さ
Dreamingの導入によって記憶の保存先が複数に分散したことで、情報の削除はやや複雑になっています。ある情報を完全に消したい場合、保存されたメモリ、チャット履歴、アーカイブ済みチャット、ファイル、メモリサマリー、接続アプリといった各所から個別に削除する必要があります(参照*2)。
1か所を消しただけでは別の場所に同じ情報が残り続ける可能性があるため、削除の際には「どこにその情報が存在し得るか」を把握しておくことが求められます。メモリが単なる保存の仕組みではなく品質管理の問題であるという指摘が示すとおり、何を残し何を捨てるかの判断は、最終的にはユーザー自身が意識的に行う部分が残ります。
おわりに
ChatGPTのDreamingは、メモリの生成・更新・管理をバックグラウンドで自動化することで、会話のたびに文脈を伝え直す負担を減らす仕組みです。文脈の引き継ぎ、好みの反映、時間経過に伴う更新という3つの軸で実用性を高めています。毎日ChatGPTを使う立場から見ると、この方向性は正しいと思います。高性能なモデルよりも、「自分のことを知っているモデル」のほうが日常業務では使いやすい場面が多いからです。
一方で、意図しない情報が記憶されるリスクや、削除時に複数の保存先を確認する必要がある点など、ユーザー側の管理意識も引き続き求められます。AIに任せる部分と、人間が確認・判断する部分を明確に分ける習慣が、Dreamingを安全に使いこなすための前提です。メモリサマリーを定期的に確認しながら、自分に合った使い方を見つけていくことが、Dreamingを活用するうえでの基本になります。
監修者
安達裕哉(あだち ゆうや)
デロイト トーマツ コンサルティングにて品質マネジメント、人事などの分野でコンサルティングに従事しその後、監査法人トーマツの中小企業向けコンサルティング部門の立ち上げに参画。大阪支社長、東京支社長を歴任したのち2013年5月にwebマーケティング、コンテンツ制作を行う「ティネクト株式会社」を設立。ビジネスメディア「Books&Apps」を運営。
2023年7月に生成AIコンサルティング、およびAIメディア運営を行う「ワークワンダース株式会社」を設立。ICJ2号ファンドによる調達を実施(1.3億円)。
著書「頭のいい人が話す前に考えていること」 が、82万部(2025年3月時点)を売り上げる。
(“2023年・2024年上半期に日本で一番売れたビジネス書”(トーハン調べ/日販調べ))
参照
- (*1) TechnoSports Media Group – The AI That Finally Remembers Who You Are
- (*2) Kingy AI – OpenAI Dreaming Explained: ChatGPT's New Memory System Is a Big Step Toward Truly Personal AI
- (*3) 9to5Mac – OpenAI says ChatGPT's memory feature is getting smarter and coming to free users
- (*4) From Model Scaling to System Scaling: Scaling the Harness in Agentic AI
- (*5) OpenAI Help Center – ChatGPT – Release Notes
- (*6) OpenAI on X: "We’ve been researching new ways for ChatGPT memory…" / X
- (*7) The Circuitry – OpenAI Upgrades ChatGPT Memory, Extends to Free Users
- (*8) arXiv.org – Deconstructing Memory in ChatGPT
- (*9) App Vertices – ChatGPT Memory & the Future of Personalized App Experiences
- (*10) : Tracing and Attributing Errors in Large Language Model Memory Systems
