
はじめに
Anthropicが送り出したClaude Fable 5は、同社がこれまで一般公開したモデルの中で最も高い性能を備えています。私は新しいモデルが出るたびに、宣伝文句ではなく手元のタスクで実力を確かめる姿勢をとっていますが、Fable 5はソフトウェア開発や知識労働、科学研究など幅広い領域で従来モデルを上回ることが複数の検証から確認できました。一方で、安全分類器によるフォールバックや30日間のデータ保持など、導入前に把握すべき制約も明確に存在します。
この記事では、Claude Fable 5の基本仕様から従来モデルとの性能差、トークン単価を踏まえたコストパフォーマンス、そして具体的な活用法と注意点までを順に解説します。単に「すごい」で終わらせず、実務でどう使うかを軸に整理しました。
Claude Fable 5の概要
Mythos-classモデルの位置づけ
Claude Fable 5は、Anthropicが最上位カテゴリ(Mythos-class)と呼ぶモデルを、一般利用向けに安全対策を施したうえで公開したものです。同じMythos-classにはClaude Mythos 5がありますが、こちらは安全分類器を搭載せず、Project Glasswingを通じた限定公開にとどまっています(参照*1)。
つまりFable 5は、Mythos-classの高い能力をできるだけ維持しながら、幅広いユーザーが安全に使える形へ仕上げたモデルといえます。テストしたほぼすべてのベンチマークで最先端の結果を示しており、ソフトウェア開発、知識労働、画像認識、科学研究など多岐にわたる分野で高い性能を発揮します(参照*2)。私がこれまでChatGPT、Claude、Gemini、Perplexityなどを同じ課題で比較してきた経験からいうと、モデルのブランド名より「実際の業務課題に対してどこまで使えるか」が問題です。Fable 5はその観点で、明らかに一段上の水準に来ています。
AWSでも即日利用可能となっており、複雑な知識労働やコーディングのタスクを長時間にわたり人手を介さず実行できる点が、従来のAIモデルとの根本的な違いとして紹介されています(参照*3)。
基本スペックとAPI仕様
Fable 5のAPI料金は、入力トークンが100万トークンあたり10ドル、出力トークンが100万トークンあたり50ドルに設定されています。キャッシュ書き込み時の入力は100万トークンあたり12.50ドル、キャッシュ読み込み時は1ドルです(参照*4)。
この価格は、以前公開されていたClaude Mythos Previewの半額以下にあたります(参照*2)。利用プランとしてはPro、Max、Team、Enterpriseの各プランで利用できますが、6月23日以降は利用クレジットが必要になると案内されています(参照*5)。
高いeffort設定で複雑なタスクを処理する場合、個々のリクエストが数分から場合によっては数時間規模の自律実行に及ぶことがあります。クライアント側のタイムアウトやストリーミングの設定を事前に調整しておく必要があります(参照*6)。これは見落としやすい実装上の注意点です。APIを試しに叩いてタイムアウトでつまずくのは、仕様を読み込まずに動かし始めるときに起きがちな失敗です。
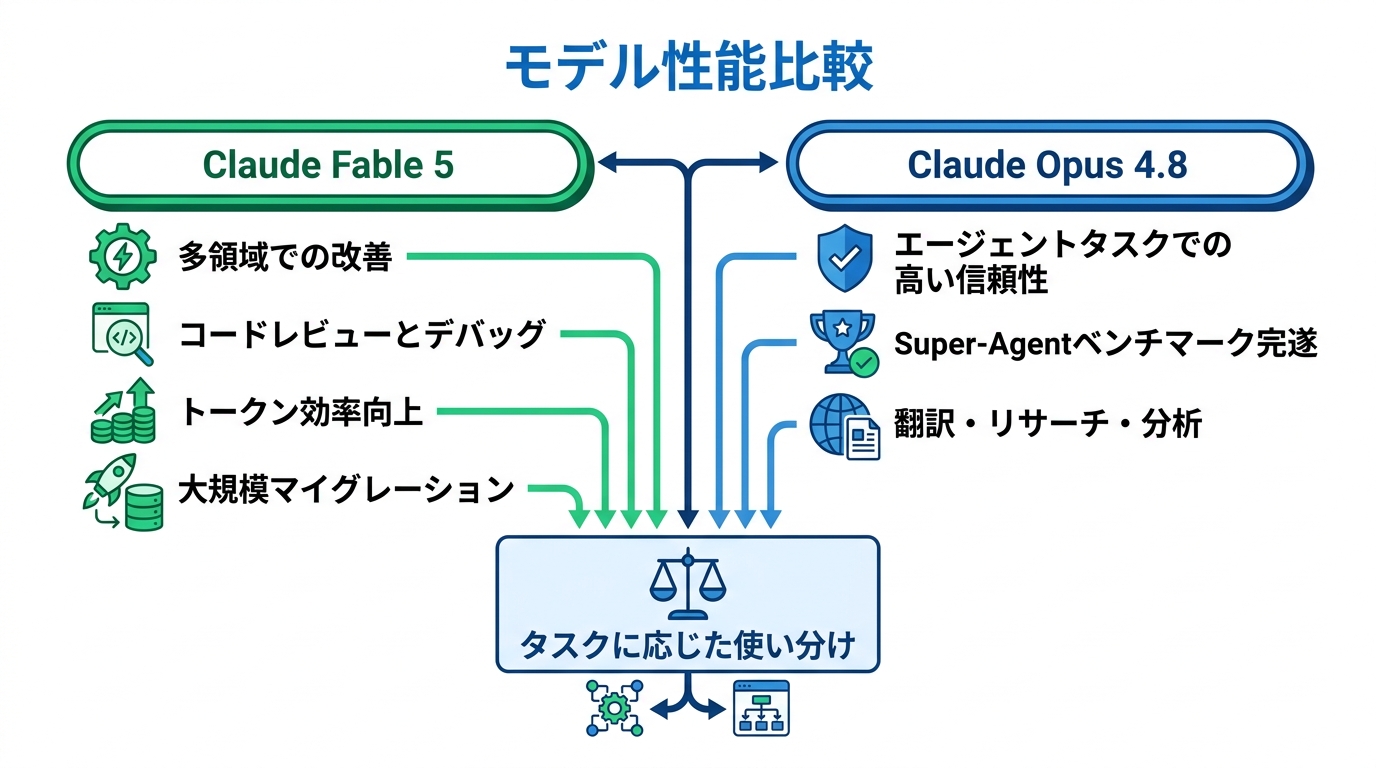
従来モデルとの性能比較
Opus 4.8との能力差
Claude Fable 5は、前世代のClaude Opus 4.8と比較して複数の領域で改善が確認されています。長時間にわたる自律動作、複雑かつ要件が明確な問題への初回正答率、画像認識、企業向けワークフロー、コードレビューとデバッグ、そしてあいまいな指示への対応力やタスクの委任・協調動作が向上しました(参照*6)。
特にバグの検出能力は、安全分類器が対象とするサイバーセキュリティ領域を除いた範囲で、Opus 4.8より目に見えて高くなっています。コードベース全体やリポジトリ履歴の横断検索においても、その差が顕著です。
一方でOpus 4.8には独自の強みがあります。Super-Agentベンチマークでは、Opus 4.8がすべてのケースをエンドツーエンドで完了した唯一のモデルとして報告されており、翻訳やリサーチ、スライド作成、分析といったエージェント製品において高い信頼性を示しています(参照*7)。したがって、タスクの性質に応じて使い分けることが実務上のポイントになります。
ベンチマークと実測評価
Claude Fable 5はトークン効率の面でも過去のClaudeモデルを上回っています。CognitionのFrontierCode評価では、本番品質のコードベース基準を満たしながら難度の高いコーディングタスクをこなす能力を測定しますが、Fable 5はmediumのeffort設定でも最前線モデルの中で最高スコアを記録しました(参照*2)。
実際のプロジェクトでも顕著な成果が報告されています。Stripeの初期テストでは、5,000万行規模のRubyコードベースに対するコードベース全体のマイグレーションを1日で完了しました。手作業であればチーム全体で2か月以上を要する規模の作業です。
こうした実測データは、ベンチマークスコアの向上が実務上の時間短縮に直結していることを示しています。特に大規模コードベースを扱う開発現場では、初回正答率とトークン効率の両方が改善された恩恵を受けやすい構造です。私がコンサルティング現場で見てきた感覚でいえば、「何度もやり直す時間」が減ることのインパクトは、単純な処理速度の向上以上に大きいことが多いです。
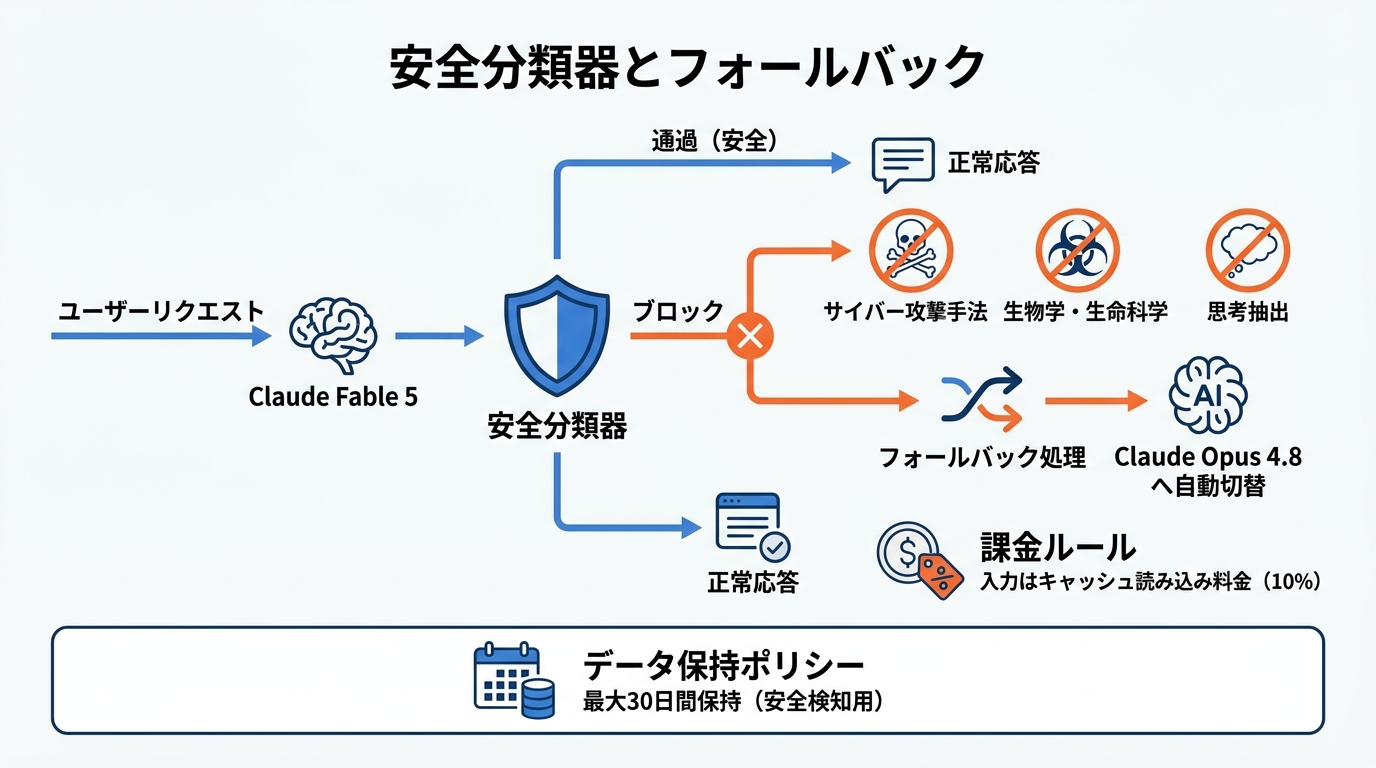
安全分類器とフォールバック
3つのブロック領域
Claude Fable 5には、すべてのリクエストに対して自動的に安全チェックが実行される仕組みが組み込まれています。ブロック対象となる領域は3つあり、攻撃的なサイバーセキュリティ手法(エクスプロイト、マルウェア、攻撃ツールの作成)、生物学・生命科学(実験手法や分子メカニズム)、そしてモデルの要約思考の抽出です(参照*8)。
これらの制限が設けられた背景として、Fable 5の高いサイバーセキュリティ能力が悪用された場合に深刻な被害をもたらしうるという判断があります。安全分類器は当初やや保守的に調整されており、無害なリクエストを誤ってブロックするケースもありますが、平均してセッション全体の5%未満にとどまるとされています(参照*2)。5%という数字は決して無視できる水準ではありませんが、フォールバック先がOpus 4.8であることを考えると、実務への影響は限定的です。ただし、機密性の高い分野では誤検知の傾向を事前に把握しておく必要があります。
サーバー側・クライアント側の実装
安全分類器がリクエストをブロックした場合、該当するクエリは次に高性能なモデルであるClaude Opus 4.8にフォールバック(自動的に切り替え)されます。ユーザー側で特別な設定を行わなくても、APIレベルで自動的にこの処理が走る仕組みです(参照*2)。
このフォールバック時の課金にも独自のルールが適用されます。安全分類器が直接ブロックして出力トークンが返されなかった場合、入力トークンへの課金は発生しません。一方、Fable 5からOpus 4.8にフォールバックした際の入力トークンは、通常のモデル切り替え時に適用されるキャッシュ書き込み料金ではなく、キャッシュ読み込み料金として扱われます。これは基本入力単価の10%にあたり、コスト面での負担を抑える設計です(参照*8)。
Anthropicはリリース前にジェイルブレイク(安全制限の回避)への耐性も検証しています。社内で実施した外部バグバウンティでは、1,000時間以上のテストを通じて汎用的なジェイルブレイクは発見されず、外部のレッドチーム組織による検証でも同様の結果だったと報告されています(参照*9)。
30日データ保持ポリシー
GitHub CopilotにおけるClaude Fable 5には、データ保持の要件があります。Anthropicの安全アーキテクチャの一部として、有害または不正な利用を検知する安全分類器を運用するために、プロンプトと出力が最大30日間保持されます。30日を過ぎたデータは削除され、保持されたデータがAnthropicのモデル学習に使われることはありません(参照*10)。
GitHub Copilotでは、このデータ保持ポリシーはClaude Fable 5にのみ適用される点が特徴です。機密性の高い情報を扱うプロジェクトでは、30日間の保持期間が社内のデータガバナンス方針と合致するかを事前に確認しておく必要があります。
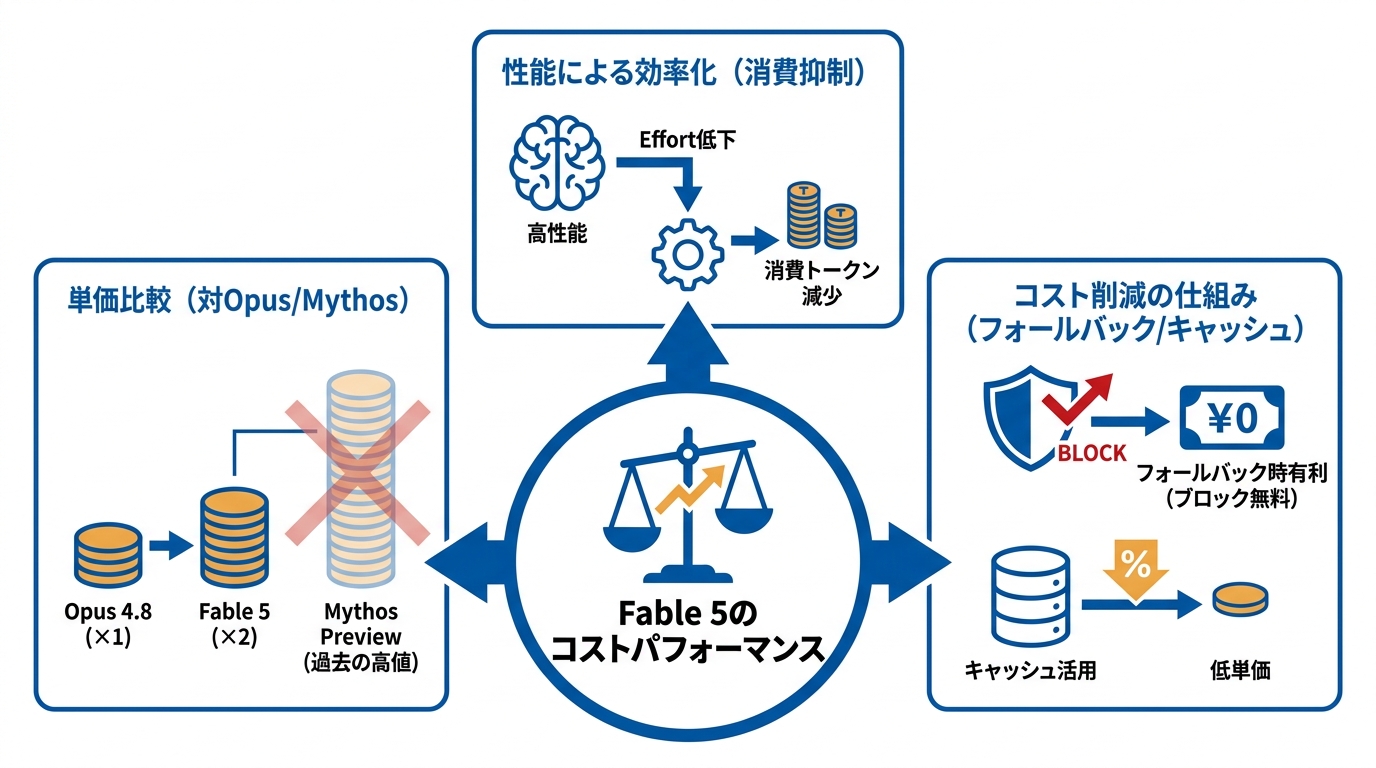
価格とコストパフォーマンス
トークン単価と他モデル比較
Claude Fable 5のトークン単価を同社のClaude Opus 4.8と並べると、入力が100万トークンあたり10ドル対5ドル、出力が50ドル対25ドルとなり、Fable 5はOpus 4.8の2倍の価格設定です。キャッシュ書き込みは12.50ドル対6.25ドル、キャッシュ読み込みは1ドル対0.50ドルとなります(参照*4)。
ただしFable 5とMythos 5の入力10ドル・出力50ドルという単価は、以前提供されていたClaude Mythos Previewの半額以下です(参照*2)。Mythos-classの性能にアクセスするコストとして捉えれば、大幅な値下げが行われた形になります。
Opus 4.8と比較した際の単価差は2倍ですが、Fable 5はmediumのeffort設定でも従来の最上位モデルを超える精度を出せる場面があります。タスクの難易度に応じてeffortを下げられれば、消費トークン数そのものを抑えられるため、単価差だけで割高と判断するのは早計です。私がAI活用コンサルティングで繰り返し伝えているのは、「1リクエストのコスト」ではなく「成果物を得るまでの総コスト」で評価すべきだということです。初回正答率が上がれば、やり直しにかかるトークンと人件費が減ります。
Batch APIやキャッシュの活用
コストを抑えるうえで知っておきたいのが、フォールバック時の課金ルールです。安全分類器がリクエストを直接ブロックし、出力トークンが返されなかった場合、入力トークンには課金されません。この仕組みはFable 5を含むすべての本番モデルに自動適用されています(参照*8)。
さらに、Fable 5からOpus 4.8にフォールバックした場合の入力トークンは、キャッシュ読み込み扱いとなり基本入力単価の10%で済みます。通常のモデル切り替えではキャッシュ書き込み扱いとなり、5分TTL時で1.25倍、60分TTL時で2倍の入力コストがかかりますが、Fable 5のフォールバックではこの増額が発生しません。
安全分類器の発動率が平均5%未満である点を考慮すると、フォールバック起因のコスト増は限定的です。キャッシュ読み込みの低単価も組み合わせれば、予算への影響をさらに小さくできます。
活用法とプロンプティング
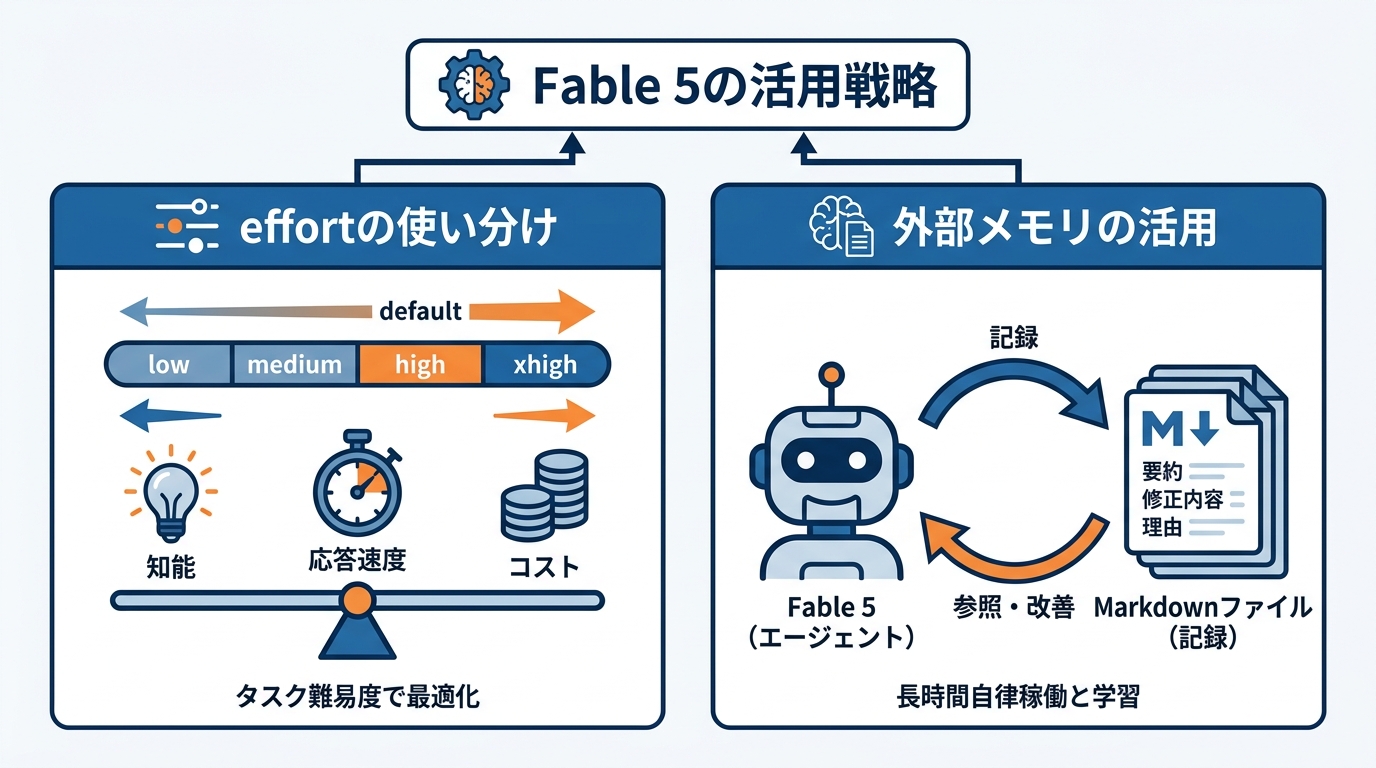
effortパラメータの使い分け
Claude Fable 5では「effort」パラメータが、知能レベル・応答速度・コストのバランスを制御する主要な手段として位置づけられています。推奨されるデフォルトはhighで、最も精度を求めるワークロードにはxhigh、定型的な作業にはmediumまたはlowを使い分ける運用が案内されています(参照*6)。
注目すべきは、Fable 5のlowやmedium設定でも、従来モデルのxhigh設定を上回る性能が出るケースが多いという点です。すべてのリクエストにxhighを適用しなくても十分な品質を確保できる場合があり、タスクの難易度を見極めてeffortを段階的に使い分けることで、コストと応答時間の両方を効率化できます。実務的には「まずmediumで試し、品質が足りなければhighへ上げる」という運用が現実的です。プロンプトを設計するときと同じ発想で、effortも調整対象として最初から組み込んでおくとよいでしょう。
長時間自律稼働とメモリ構築
Claude Fable 5は長時間にわたる自律的なタスク実行に特化した設計が施されており、数百万トークン規模の長いコンテキストでも集中力を維持できます。さらに、自分自身が書いたメモを参照して出力を改善する能力を備えています(参照*2)。
この特性を活かすために、Markdownファイルのようなシンプルな記録先を用意し、1つの学びごとに1ファイルとして保存する運用が推奨されています。ファイルの先頭に1行の要約を置き、修正内容と確認済みのアプローチの両方を、それが重要だった理由とともに記録する形式です(参照*6)。
実際の効果を示す検証として、デッキ構築型ゲーム「Slay the Spire」をFable 5にプレイさせた実験があります。ファイルベースの永続メモリを与えた場合、Opus 4.8よりも永続メモリによる性能改善幅が3倍大きく、ゲームの最終幕に到達する頻度も3倍に増えました。長時間稼働するエージェント的な用途では、メモリ構築の仕組みを組み込むことが性能を引き出す鍵になります。
企業の導入事例と評価
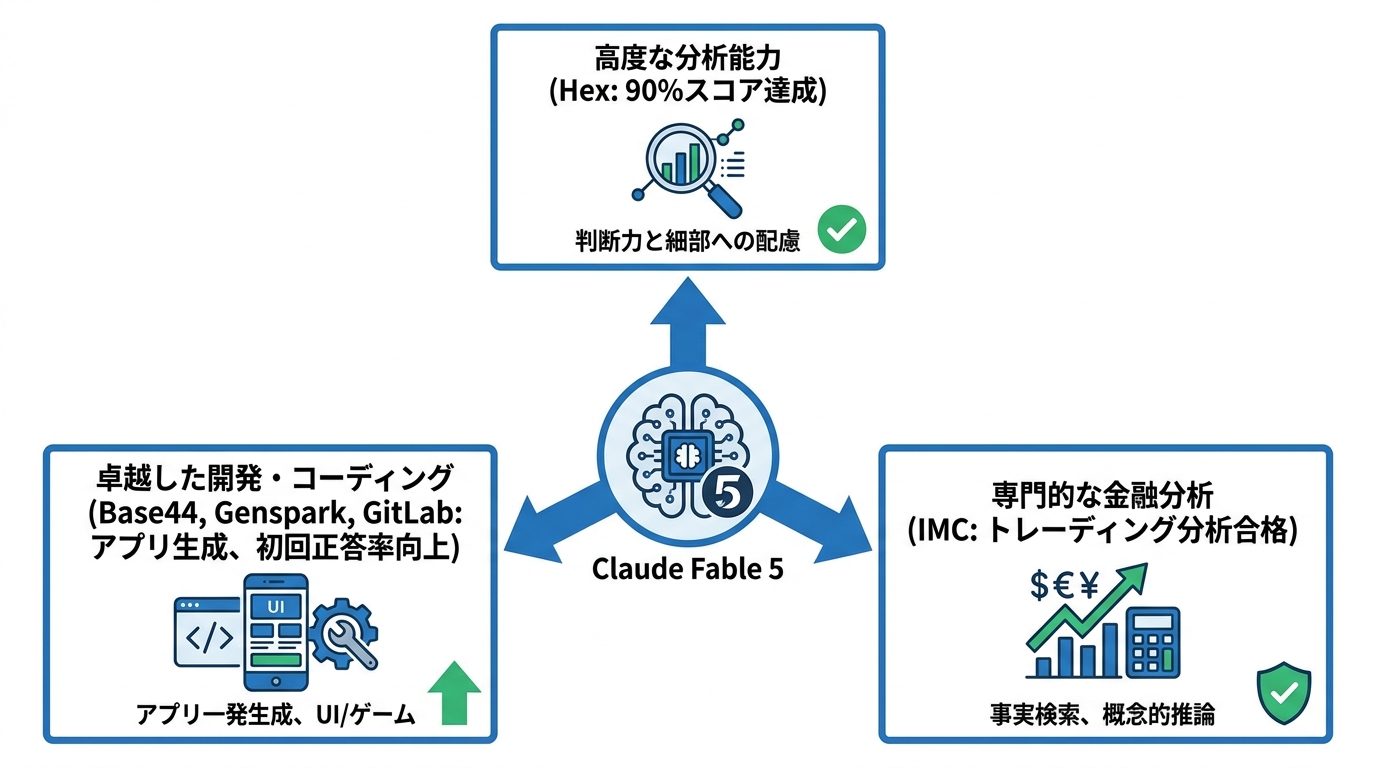
Claude Fable 5に対しては、複数の企業や外部評価機関から具体的な成果が報告されています。分析プラットフォームのHexは、複雑で長時間にわたる分析タスクを扱う自社のコア分析ベンチマークで、Fable 5が初めて90%のスコアを達成したと発表しました。最も難しい問題においても優れた判断力と細部への配慮を示したと評価されています(参照*9)。
同じ外部テストでは、バイブコーディング(対話型コーディング)プラットフォームのBase44がFable 5について「アプリ全体を一発で生成する能力」とツール呼び出しの精度を高く評価しました。AIワークスペースのGenspark もFable 5が自社の全評価で他のモデルを上回り、UIデザインやゲームコーディングで特に顕著な差を見せたと報告しています。
GitLabのDuo Agentic Chatでも、Fable 5は複雑かつ要件が明確な問題での初回正答率に測定可能な改善をもたらしました。初期テスターからは、従来モデルでは数日間の反復作業を要したシステムが単一のパスで実装できたとの報告が寄せられており、やり取りの往復回数が減少しています(参照*11)。
金融分野でも評価が進んでおり、IMCはFable 5が自社のトレーディング分析評価をほぼ全項目で合格したと報告しています。対象には事実の検索、概念的推論、原因分析、期待値分析が含まれます(参照*2)。こうした事例は、Fable 5の汎用性がソフトウェア開発にとどまらず、分析・金融領域にまで及んでいることを裏付けています。ただし、企業の導入事例は発表段階の情報であり、自社の業務に当てはまるかどうかは別途検証が必要です。外部の成功事例をそのまま信じるより、小さなタスクで自社の条件に合うかを確かめるほうが確実です。
導入時の注意点と制約
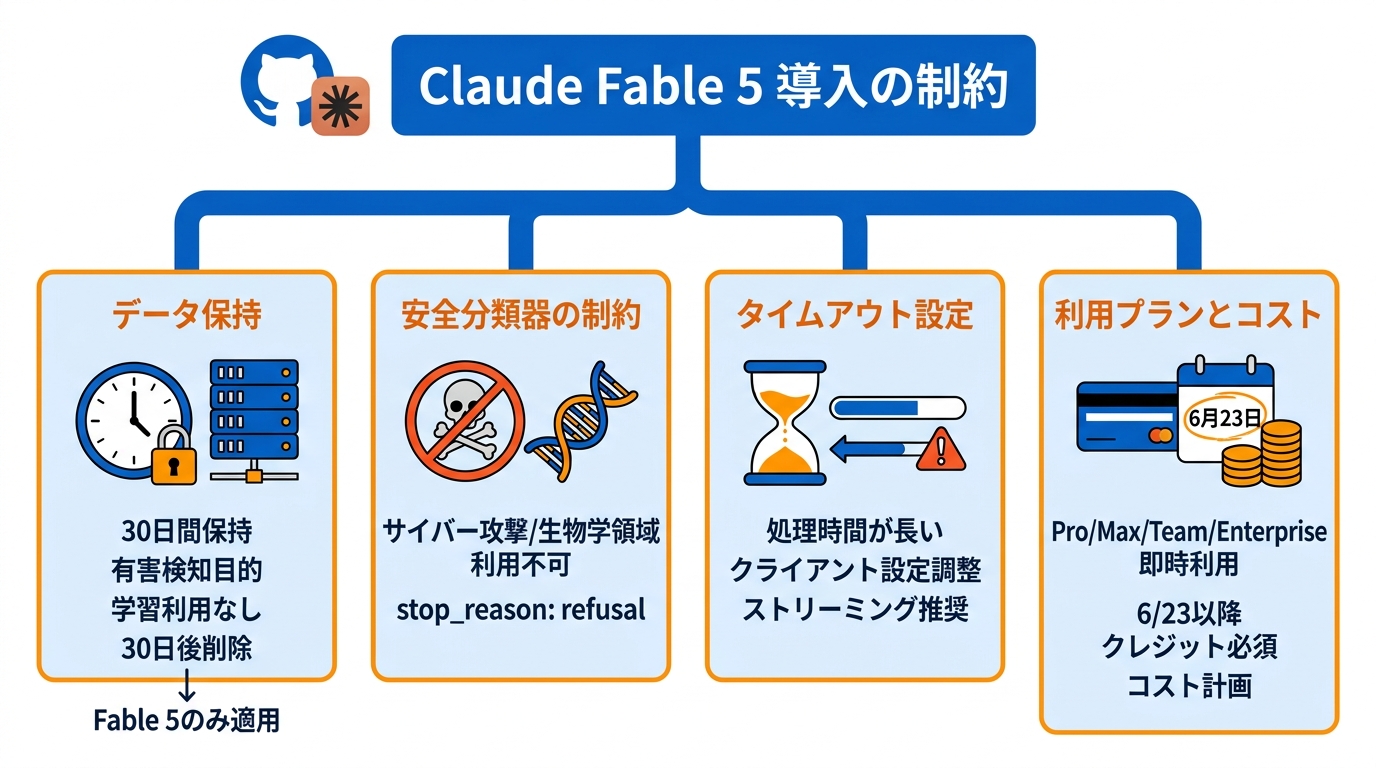
GitHub CopilotでClaude Fable 5を導入する際に最も留意すべき点は、30日間のデータ保持が必須であることです。有害利用の検知を目的とした安全分類器の運用のために、プロンプトと出力が最大30日間保持されます。この保持データはモデルの学習には使われず、30日後に削除されます。またGitHub Copilotでは、このポリシーはFable 5にのみ適用される固有の要件です(参照*10)。
安全分類器の制約も実務に影響を与えます。Fable 5は攻撃的なサイバーセキュリティ用途や生物学・生命科学領域での利用を想定しておらず、これらの領域のリクエストに対してはstop_reasonが「refusal」として返る場合があります。また、高いeffort設定では個々のリクエストが数分間にわたるケースもあり、自律的な実行は数時間に及ぶこともあるため、クライアントのタイムアウト設定やストリーミング、ユーザー向けの進捗表示を移行前に調整する必要があります(参照*6)。
利用プランの面では、Pro、Max、Team、Enterpriseの各プランで即座に利用を開始できます。ただし6月23日以降は利用クレジットが必要になるため、継続的な運用を予定している場合はクレジットの確保を含めたコスト計画を早めに立てておくことが求められます(参照*5)。
おわりに
Claude Fable 5は、Mythos-classの能力を一般公開向けに安全対策を施した形で提供するモデルであり、ベンチマークと実務の両面で従来モデルを超える成果が報告されています。トークン単価はOpus 4.8の2倍ですが、effortの段階調整やキャッシュ活用で総コストを抑える余地があり、初回正答率の向上による作業時間の圧縮を考慮すれば費用対効果を見込める構成です。私自身、新モデルが出るたびに算数・調査・文章生成・資料作成といった具体的なタスクで実力を確かめていますが、Fable 5は「一段上に来た」と感じさせるモデルです。
一方で、30日間のデータ保持ポリシーや安全分類器によるフォールバック、タイムアウト設定の見直しなど、導入前に確認すべき制約も明確に存在します。生成AIの導入で最初に詰まるのは、プロンプトでもモデル選定でもなく、組織のルール整備と品質検証のプロセス設計であることが多いです。自社のデータガバナンスやユースケースと照らし合わせたうえで、小さなタスクから試して感触をつかむことをお勧めします。
監修者
安達裕哉(あだち ゆうや)
デロイト トーマツ コンサルティングにて品質マネジメント、人事などの分野でコンサルティングに従事しその後、監査法人トーマツの中小企業向けコンサルティング部門の立ち上げに参画。大阪支社長、東京支社長を歴任したのち2013年5月にwebマーケティング、コンテンツ制作を行う「ティネクト株式会社」を設立。ビジネスメディア「Books&Apps」を運営。
2023年7月に生成AIコンサルティング、およびAIメディア運営を行う「ワークワンダース株式会社」を設立。ICJ2号ファンドによる調達を実施(1.3億円)。
著書「頭のいい人が話す前に考えていること」 が、82万部(2025年3月時点)を売り上げる。
(“2023年・2024年上半期に日本で一番売れたビジネス書”(トーハン調べ/日販調べ))
参照
- (*1) Claude API Docs – Presentamos Claude Fable 5 y Claude Mythos 5
- (*2) Claude Fable 5 and Claude Mythos 5
- (*3) Amazon Web Services, Inc. – AWS announces Claude Fable 5, the first generally available Mythos-class model
- (*4) Claude API Docs – Pricing – Claude API Docs
- (*5) Business Insider – Anthropic Releases Claude Fable 5, a 'Mythos-Class' Model
- (*6) Claude API Docs – Prompting Claude Fable 5
- (*7) Introducing Claude Opus 4.8
- (*8) Classifier fallback and billing for Claude Fable 5
- (*9) TechCrunch – Anthropic's Claude Fable 5 is a version of Mythos the public can access today
- (*10) The GitHub Blog – Claude Fable 5 is generally available for GitHub Copilot
- (*11) GitLab – Mythos-class Claude Fable 5 arrives on GitLab Duo Agent Platform
