
はじめに
Geminiを使えば、会議の録画や講演のmp4ファイルを、音声抽出なしでそのまま渡して文字起こしできます。従来は音声だけを抽出してから専用ツールにかける手間が必要でしたが、その工程が丸ごと省けます。私自身、議事録作成や取材音声の整理にAIを使い倒してきましたが、この「そのまま渡せる」という手間のなさは、実務での定着率に直結します。
ただし、Geminiでmp4を文字起こしする際には、モデルの選び方やプロンプトの工夫、ファイルサイズの制限といった実務上の注意点を押さえておく必要があります。本記事では、具体的な手順から精度を引き上げるテクニック、他ツールとの使い分けまでを順を追って解説します。
Geminiによる文字起こしの仕組み
マルチモーダルAIとしての特徴
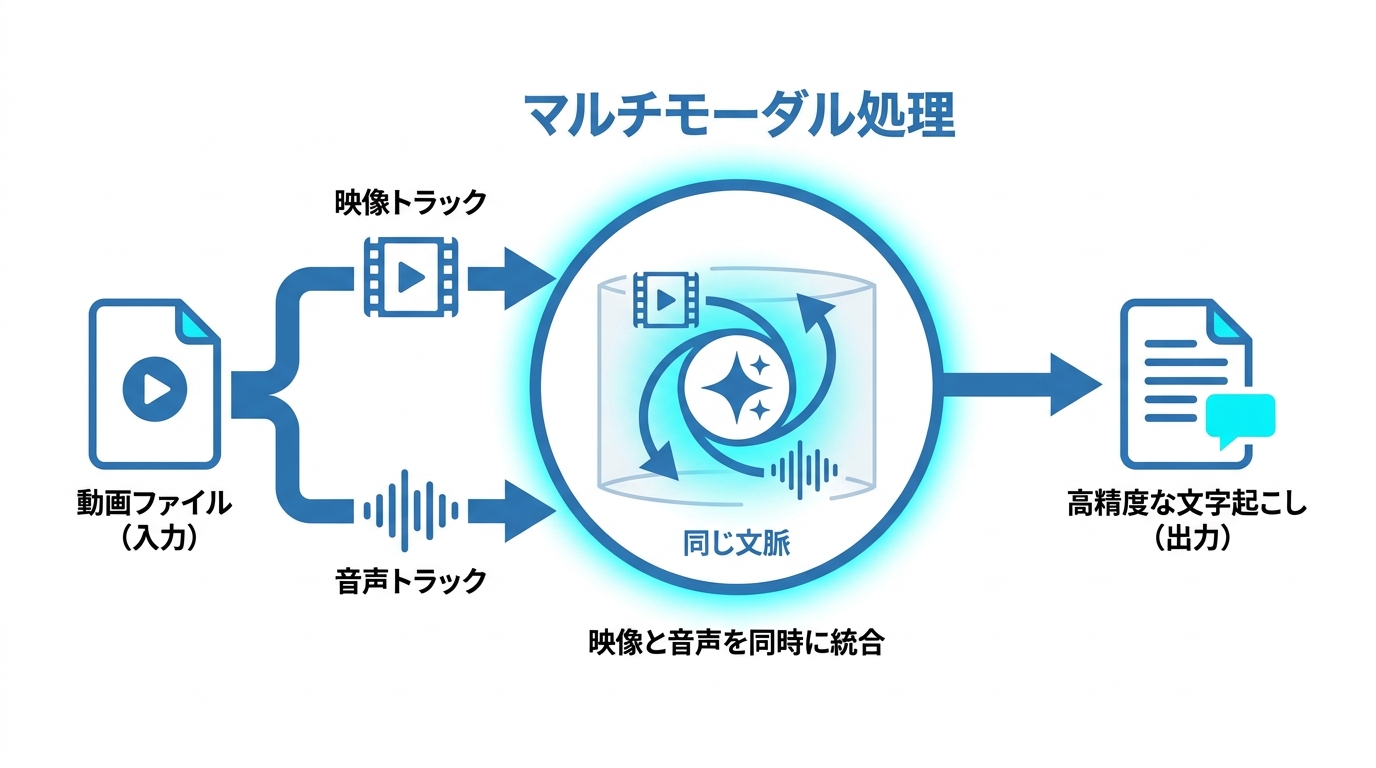
Geminiは、テキスト・音声・画像・動画など複数の種類の情報を同じ文脈で同時に処理できるAI(マルチモーダルAI)です。従来の機械学習モデルは、テキスト・音声・画像といった情報を別々に処理する設計が一般的でした。複数の種類の情報をまとめて扱おうとすると、処理が分断されたり、情報が変換の途中で失われたりする課題がありました。Geminiはこれらの問題を、すべての情報を同じ文脈の中で同時に処理する仕組みによって解決しています(参照*1)。
Gemini 2.0 Flashは、テキスト・コード・画像・音声・動画を入力として受け付け、最大100万トークンの文脈長に対応しています(参照*2)。この特徴により、動画に含まれる映像と音声の両方を一度に読み取り、発話内容をテキスト化しながら映像の文脈まで考慮した文字起こしが可能になります。音声だけを切り出して別のツールに渡す、という工程を省ける点が従来の手法との大きな違いです。私が文字起こし業務でAIを使い始めた当初は、音声抽出→専用ツール→テキスト整形という複数ステップを踏んでいましたが、Geminiはその流れを一気に短縮してくれます。
mp4を直接処理できる理由
Geminiは、mp4を含む複数の動画フォーマットを受け付け、プランによって分析できる長さの目安が異なります。Geminiは動画形式としてmp4のほか、MOV・MPEG・AVI・WMV・FLV・WEBMなど幅広いフォーマットに対応しています。標準プランでは1本あたり最大5分の動画を分析でき、Gemini Advanced(AI ProまたはUltra)に加入すると最大1時間まで処理できます(参照*3)。
mp4から直接文字起こしできるのは、映像トラックと音声トラックを内部で読み取り、同一の文脈で処理できる設計にあります。mp4ファイルをアップロードすると、Geminiは映像トラックと音声トラックの両方を内部で読み取ります。テキスト・音声・映像を同一の文脈で処理するマルチモーダル設計がその土台にあるため、音声を事前に抽出する手順なしにmp4から直接文字起こしが行えます。つまり、手元にあるmp4ファイルをそのまま渡すだけで、音声の書き起こし結果を得られる仕組みです。
mp4文字起こしの手順
Google AI Studioでの操作方法
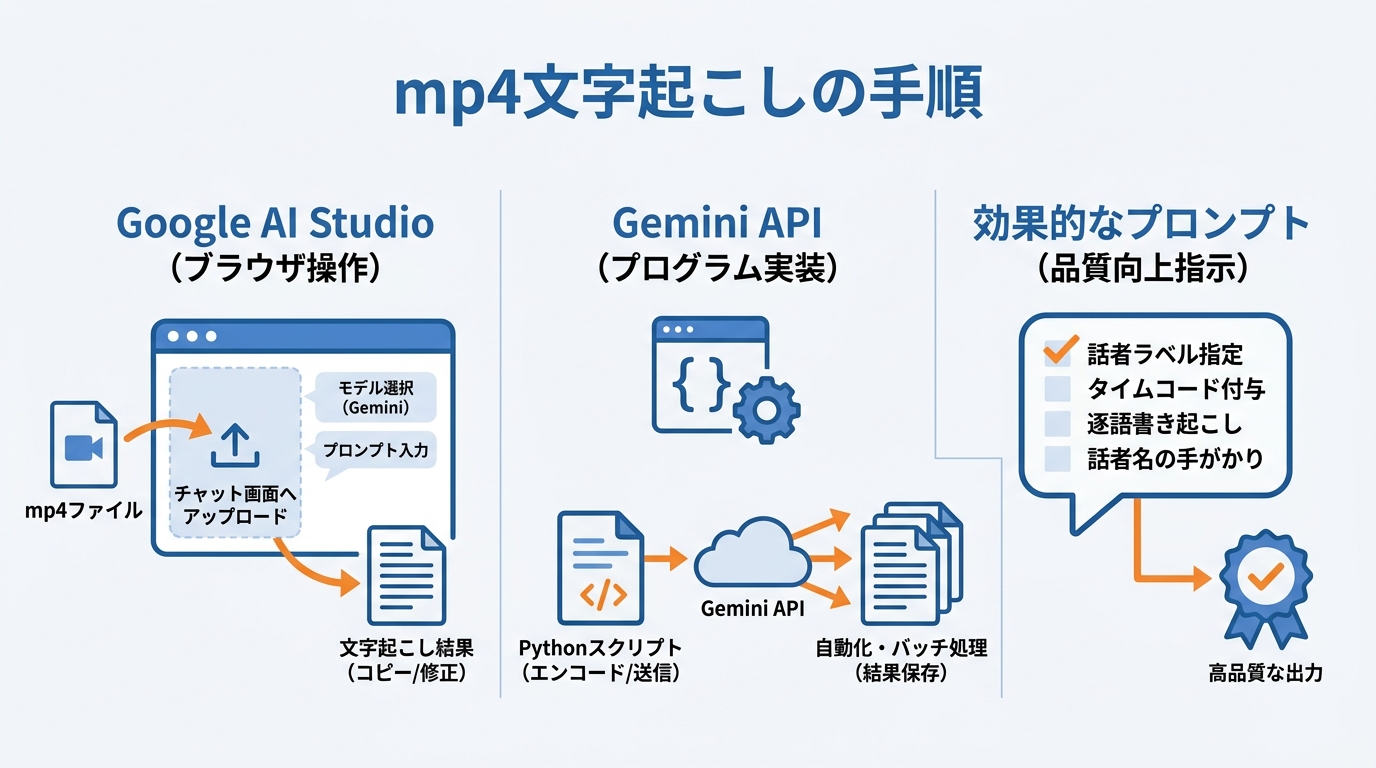
Google AI Studio(aistudio.google.com)を使うと、ブラウザ上でmp4(または音声)をアップロードして文字起こしできます。ウェブブラウザでGoogle AI Studioを開き、mp4ファイルをチャット画面にアップロードします。次に、モデル選択のドロップダウンメニューから使いたいGeminiモデルを選びます(参照*4)。
プロンプトで出力形式を具体的に指示すると、書き起こし結果を使いやすい形で受け取れます。ファイルをアップロードしたら、どのように文字起こしをしてほしいかをプロンプトで指示します。たとえば「この動画の音声をプレーンテキストで書き起こしてください。話者ラベルを付けてください」のように、出力形式や話者の区別について具体的に伝えます。私の経験では、「プレーンテキストで」「話者ごとに分けて」「タイムスタンプをMM:SS形式で」と条件を一度に列挙するだけで、後工程の編集量が大きく減ります。Geminiがファイルを処理すると書き起こし結果が表示されるので、内容を確認してコピーや修正ができます(参照*5)。
APIを使ったプログラム実装
Gemini APIを使うと、mp4文字起こしを処理フローに組み込み、自動化できます。mp4の文字起こしを自動化したい場合は、Gemini APIをプログラムから呼び出す方法が適しています。Pythonの場合、mp4ファイルをBase64でエンコードし、MIMEタイプを「video/mp4」に指定してAPIに送信します。リクエストのparts配列にテキスト指示とファイルデータの両方を含めることで、1回のAPI呼び出しで文字起こし結果を取得できます(参照*6)。
プログラム実装では、大量のmp4ファイルをバッチ処理しやすくなります。ファイルの読み込みからエンコード、APIリクエスト、結果の保存までをスクリプトにまとめておけば、手動操作なしに文字起こしが完了します。自社システムやワークフローツールとの連携にも向いており、定期的に録画が発生する業務では特に有効です。私自身、メディア運営の現場でこうした自動化を試してきましたが、「動く仕組みを作る」よりも「品質チェックの工程をどう組み込むか」のほうが実務上の難題だと感じています。出力をそのまま使うのではなく、確認・修正のステップを自動化フローの中に残しておくことを強くお勧めします。
効果的なプロンプトの書き方
出力形式(話者ラベル・タイムコード・逐語など)を先に決めてプロンプトに明記すると、文字起こしの品質が安定しやすくなります。文字起こしの品質は、プロンプトの書き方に大きく左右されます。ある手法では、JSON形式で出力キーを指定し、話者ごとの識別番号(voice ID)を振りつつ、各発話の開始タイムコード(MM:SS形式)を含めて逐語書き起こしを行うよう指示しています(参照*1)。私がAI活用の現場で繰り返し確認してきたのは、「AIに何をさせるか」を曖昧にしたままでは、どれだけ高性能なモデルを使っても結果がばらつくという事実です。プロンプトは設計であり、出力形式・禁止事項・評価基準まで書いて初めて安定します。
話者名などの手がかりをプロンプトに含めると、話者ラベルの振り分けが改善する場合があります。話者の名前が分かっている場合は、プロンプトの中で明示するとさらに精度が上がります。たとえば「Nickが最も多く話す人で、もう一人はNevilleです」のように伝えると、Geminiがその情報をもとに話者ラベルを正確に振り分けます(参照*4)。出力のフォーマット、話者の指定、タイムスタンプの有無といった条件をプロンプトで明確にすることが、求める結果を得るための鍵になります。
精度を高めるテクニック
モデル選択とパラメータ設定
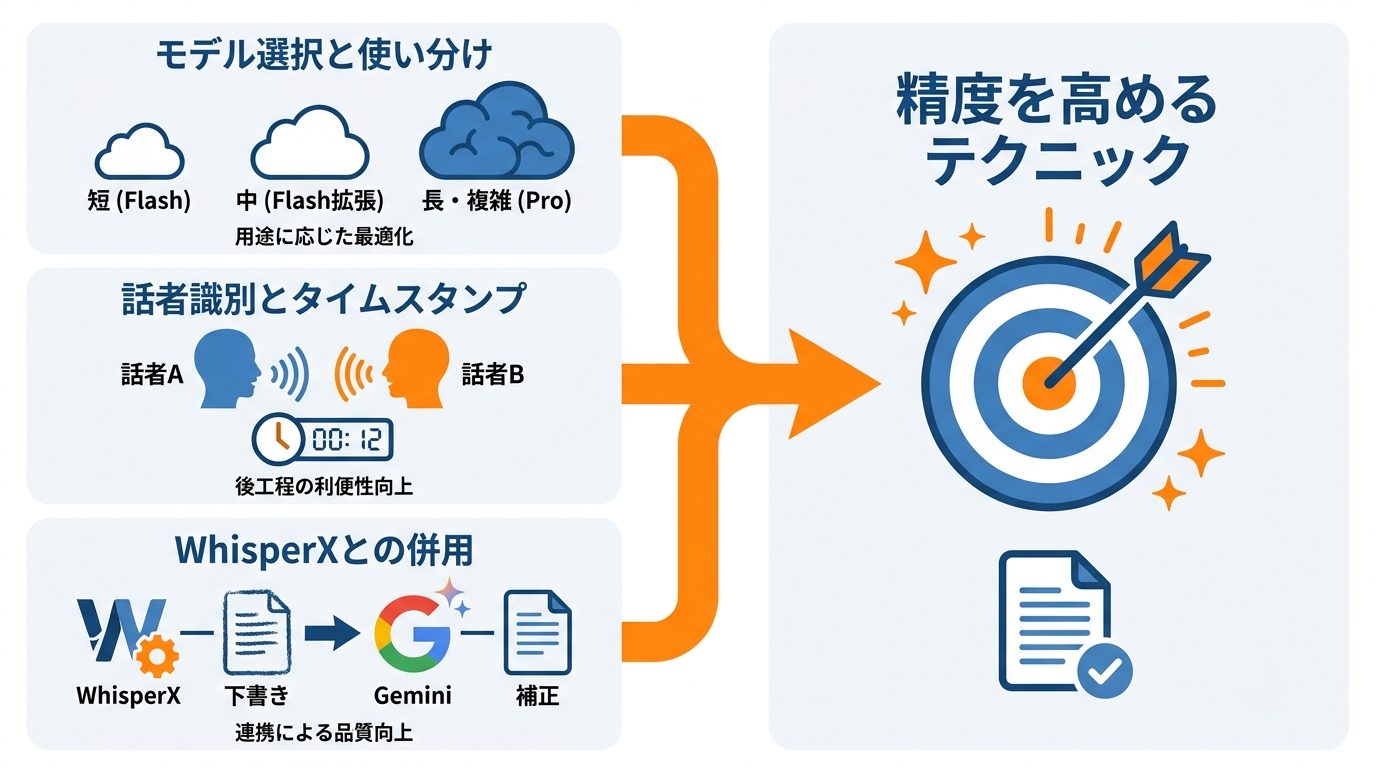
動画の長さや音声の複雑さに合わせてGeminiモデルを選ぶと、文字起こしの精度と運用コストのバランスを取りやすくなります。Geminiには複数のモデルがあり、用途に応じた使い分けが精度を左右します。Gemini 2.0 Flashは速度とコストに優れ、最大出力8,192トークン、25分程度までの標準的な動画に向いています。Gemini 2.5 Flashは最大出力65,536トークンに拡張され、25分以上の動画にも対応します。Gemini 2.5 Proは最も性能が高い一方で速度とコスト面では劣るものの、複雑な動画や1時間超の長尺動画に適しています(参照*1)。
短い録画は軽量モデル、長尺・複雑な音声は高性能モデル、という使い分けが現実的です。短い会議の録画であればGemini 2.0 Flashで十分な精度が得られ、コストも抑えられます。一方、長時間のセミナーや複数人が話す複雑な音声では、Gemini 2.5 Proを選ぶことで内容の正確さが向上します。私はChatGPT、Claude、Geminiなど複数のモデルを同じタスクに当てて比較することを習慣にしていますが、文字起こし用途ではモデルのブランドよりも「処理できる長さ」と「話者識別の精度」を基準に選ぶのが実用的です。処理する動画の長さと複雑さに合わせてモデルを切り替えるのが、現時点での判断基準として妥当だと考えています。
話者識別とタイムスタンプの活用
複数話者の音声では、話者ラベルとタイムスタンプを付けると後工程(議事録・字幕・検索)が扱いやすくなります。複数の話者がいる録音では、誰がどの発話をしたかを区別できるかが文字起こしの実用性を決めます。Geminiに会議の録音を渡し、話者ラベル付きの書き起こしを指示したところ、自動的に会話を分離して「Speaker 1」「Speaker 2」のようにラベルを振り分け、結果は良好だったという検証結果があります(参照*5)。
タイムスタンプもプロンプトで指示して付与できます。タイムスタンプの付与もプロンプトで指示できます。発話ごとに開始時刻を記録しておけば、書き起こしテキストから該当の箇所を動画上でたどることが容易になります。議事録の作成や動画の字幕生成など、後から特定の発言を参照する必要がある用途では、話者ラベルとタイムスタンプの両方をプロンプトに含めておくことが実務上有効です。
WhisperXとの併用による精度向上
字幕制作などでタイムスタンプと内容の両方の正確さが必要なら、WhisperXとGeminiの併用が選択肢になります。Gemini単体で高い精度が得られますが、さらに正確さを求める場合にはWhisperXとの組み合わせが有効です。WhisperXはタイムスタンプの正確性と単語レベルの位置合わせに優れる一方、内容の誤認識が起きることがあります。Geminiは文脈を理解してエラーを修正する力に長けています(参照*7)。
併用は、WhisperXで下書きを作ってからGeminiで内容を補正する流れになります。この方法では、WhisperXで時間精度の高い下書きを作り、その結果と音声の両方をGeminiに渡して内容の誤りを補正させます。汎用LLMに全工程を任せるのではなく、それぞれの得意分野に特化した処理を組み合わせることで、単独使用を超える品質が実現できるという考え方です。字幕制作のように時間と内容の両方の正確さが求められる場面で、この併用手法は特に力を発揮します。
mp4ファイルの注意点と対処法
ファイルサイズとアップロード制限
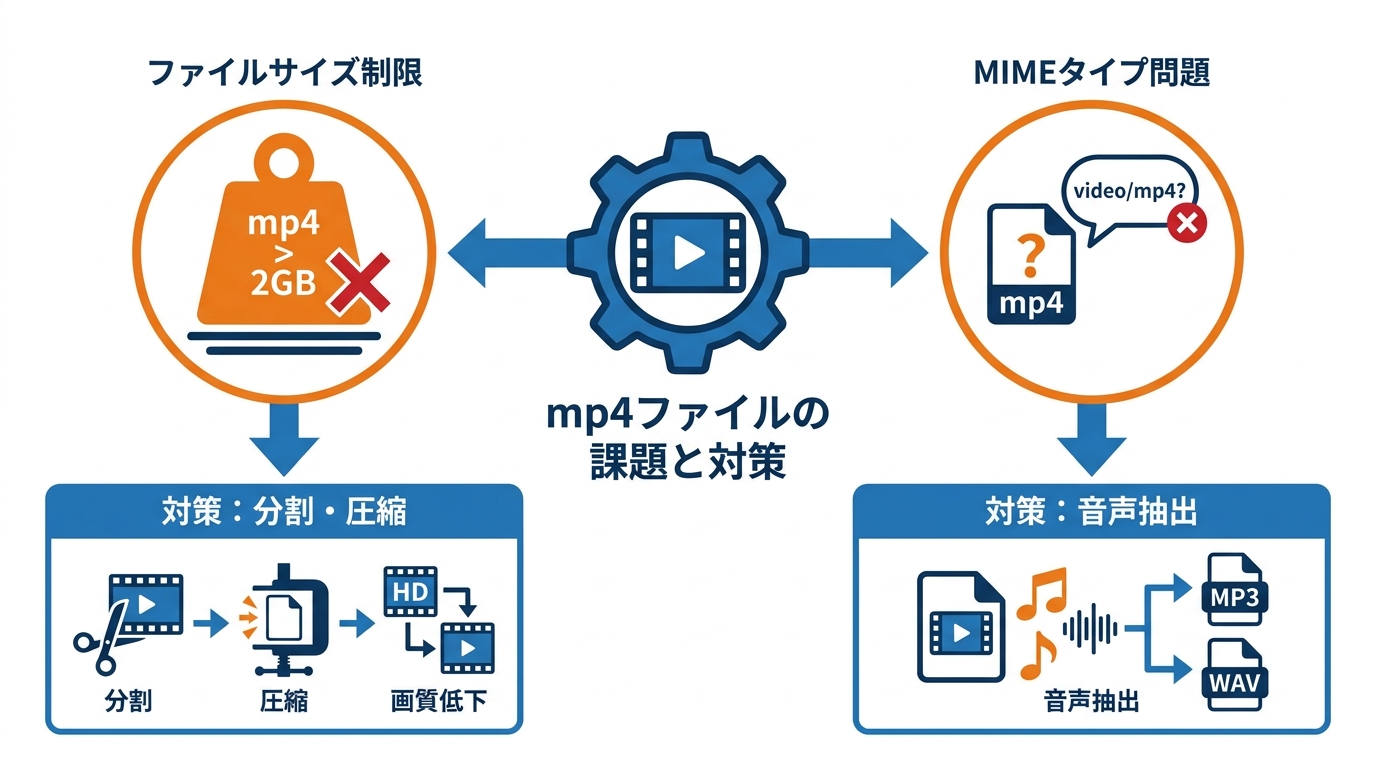
mp4のアップロード上限や保持期間は、利用する画面やAPIによって異なります。Geminiにmp4ファイルを渡す際、ファイルサイズの上限は利用方法によって異なります。一般のGeminiアプリでは動画1本あたり最大2GBまでアップロード可能です。Gemini APIのFiles APIを使う場合は、1ファイルあたり最大2GB、プロジェクト全体で最大20GBの容量が確保されており、アップロードしたファイルは通常48時間にわたって再利用できます(参照*8)。
上限を超える場合は、分割や圧縮でサイズを下げる必要があります。長時間のmp4ファイルはサイズが大きくなりやすいため、上限を超える場合は事前に動画を分割するか、解像度・ビットレートを下げてファイルを圧縮する対処が必要です。文字起こしが目的であれば映像の画質は結果にほとんど影響しないため、映像部分の圧縮は有効な手段です。FFmpegを使って音声だけを抽出してしまうのも、ファイルサイズを大幅に削減できる実用的な選択肢です。
MIMEタイプ問題と音声抽出の判断
mp4(video/mp4)コンテナが原因で、音声の文字起こし処理が失敗するケースが報告されています。mp4ファイルを扱う際に注意が必要なのがMIMEタイプの問題です。音声しか含まれないファイルでもコンテナ形式がmp4の場合、MIMEタイプが「video/mp4」となり、処理ツールによってはエラーが発生する事例が報告されています。Geminiノードに「video/mp4」のバイナリデータを渡したところ、内部エラーで文字起こしに失敗したケースがありました(参照*9)。
ワークフローツール経由や長い録音では、音声だけを抽出して渡すほうが安定する場合があります。Geminiはmp4から音声トラックを自動的に抽出して文字起こしを行える場合もありますが、長い録音やワークフローツール経由での処理では、あらかじめ音声を別ファイルとして抽出してからアップロードするほうが安全です(参照*5)。FFmpegなどで音声だけをMP3やWAV形式に変換してから渡すと、MIMEタイプの不一致によるエラーを回避でき、処理も安定します。
他ツールとの比較と使い分け
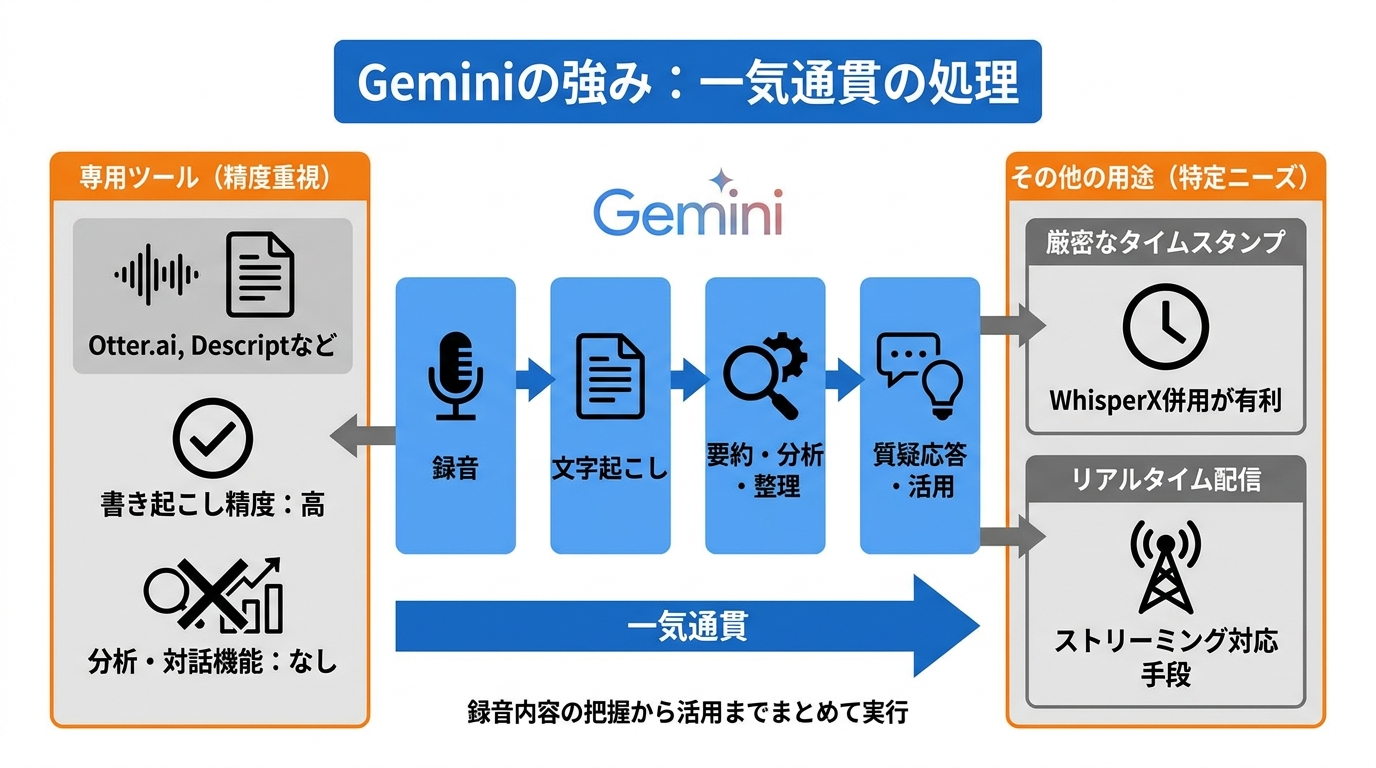
Whisper・専用ツールとの違い
文字起こしは、要約・分析まで一気に進めたいのか、書き起こし専用で精度を追求したいのかで選択肢が変わります。文字起こしに使えるツールは複数ありますが、それぞれ得意とする領域が異なります。ChatGPTはWhisperと連携すれば文字起こしが可能ですが、追加の設定が必要です。Perplexityは情報検索に特化しており、文字起こし機能には重点を置いていません。Otter.aiやDescriptなどの専用ツールは書き起こし精度に優れる一方、内容の分析・要約・対話的な操作といった機能は備えていません(参照*10)。私が複数のツールを実際に試してきた感覚では、「書き起こし精度」だけで比べるなら専用ツールに分があることもありますが、書き起こした後に何をするかを含めた全体の手間で考えると、Geminiの一体感は大きな強みになります。
Geminiは、文字起こし後の要約や整理、質疑応答まで同じ環境で行える点が特徴です。Geminiの特徴は、文字起こしだけでなく、書き起こした内容の要約や整理、質疑応答まで1つの環境で行える点にあります。書き起こし結果を別のツールにコピーして加工する手間が省けるため、録音内容の把握から活用までを一気通貫で進めたい場面に向いています。
Geminiを選ぶべきケース
Gemini 2.5 Proは、文字起こし用途で有力な選択肢として言及されています。Gemini 2.5 Proは、現時点で文字起こしに最も適したAIモデルの1つと評価されています。ある検証では、病院の録音を使ってAssemblyAIの最新モデルと比較したところ、Geminiのほうが話者ラベルの正確さと文脈の手がかりを活かした書き起こし精度で上回ったという結果が報告されています(参照*4)。
用途によっては、WhisperX併用や別手段のほうが適する場合もあります。一方で、タイムスタンプの厳密な精度が求められる字幕制作ではWhisperXとの併用が有利であり、リアルタイムの配信音声を処理する場合にはストリーミング対応の別手段が適しています。Geminiは事前に録画・録音されたmp4ファイルを一括で渡し、文字起こしから内容の活用までをまとめて行いたいケースで特に力を発揮します(参照*7)。
おわりに
Geminiは、mp4ファイルをそのままアップロードして文字起こしでき、要約や整理まで一連で進めやすい点が強みです。モデルの選択やプロンプトの工夫、ファイルサイズへの対処といったポイントを押さえることで、結果の品質をさらに引き上げられます。ただし、出力をそのまま使うのは危険です。文章がそれらしく整っているほど、内容の誤りを見落としやすくなります。最終的なファクトチェックと修正は、必ず人間が引き受ける必要があります。
まずはGoogle AI Studioで手元のmp4ファイルを試し、用途に応じてAPI連携やWhisperXとの併用へと段階的に活用の幅を広げてみてください。小さな業務から始めて、入力・出力・確認・修正のサイクルを回すことが、現場への定着への近道です。
監修者
安達裕哉(あだち ゆうや)
デロイト トーマツ コンサルティングにて品質マネジメント、人事などの分野でコンサルティングに従事しその後、監査法人トーマツの中小企業向けコンサルティング部門の立ち上げに参画。大阪支社長、東京支社長を歴任したのち2013年5月にwebマーケティング、コンテンツ制作を行う「ティネクト株式会社」を設立。ビジネスメディア「Books&Apps」を運営。
2023年7月に生成AIコンサルティング、およびAIメディア運営を行う「ワークワンダース株式会社」を設立。ICJ2号ファンドによる調達を実施(1.3億円)。
著書「頭のいい人が話す前に考えていること」 が、82万部(2025年3月時点)を売り上げる。
(“2023年・2024年上半期に日本で一番売れたビジネス書”(トーハン調べ/日販調べ))
参照
- (*1) Towards Data Science – Unlocking Multimodal Video Transcription with Gemini
- (*2) Google Cloud Documentation – Gemini 2.0 Flash
- (*3) Data Studios ‧Exafin – Google Gemini file upload: types, formats, and capabilities
- (*4) LinkedIn – Gemini 2.5 Pro is probably the best AI model for speech-to-text transcription right now.
- (*5) Vomo – How to Take Good Meeting Notes: Best Practices, Examples, and Templates
- (*6) Query audio and video models
- (*7) Dohyeon Kim – Combining WhisperX and Gemini for Accurate Subtitles
- (*8) Data Studios ‧Exafin – Google AI Studio File Uploading: Supported File Formats, Upload Size Limits, Upload Rules, And Document Processing Features
- (*9) n8n Community – Google Gemini Node fails to transcribe Instagram audio (video/mp4), but works for WhatsApp (audio/ogg)
- (*10) AI Rank Checker – Can Gemini Transcribe Audio?
