
はじめに
生成AIによる画像作成は、想像力をかき立てる革新的な技術として注目を集めています。専門的な知識がなくても、文章による指示だけで多様な画像を生み出せる点は、クリエイティブ業界だけでなく、広告、教育、マーケティングなど幅広い分野で活用が進んでいます。一方で、仕組みや活用法を十分に理解しないまま利用すると、誤解を招く生成物や信頼性の問題に直面することもあります。
本記事では、生成AIで画像作成を行う際に押さえておきたい基礎知識を解説します。テキストツーイメージの技術的背景から、実務での応用ノウハウ、安全性や信頼性を高めるための取り組みまで、全体像を整理しながら、効果的な活用とリスクの理解を促進します。
生成AIで画像を作成する仕組み
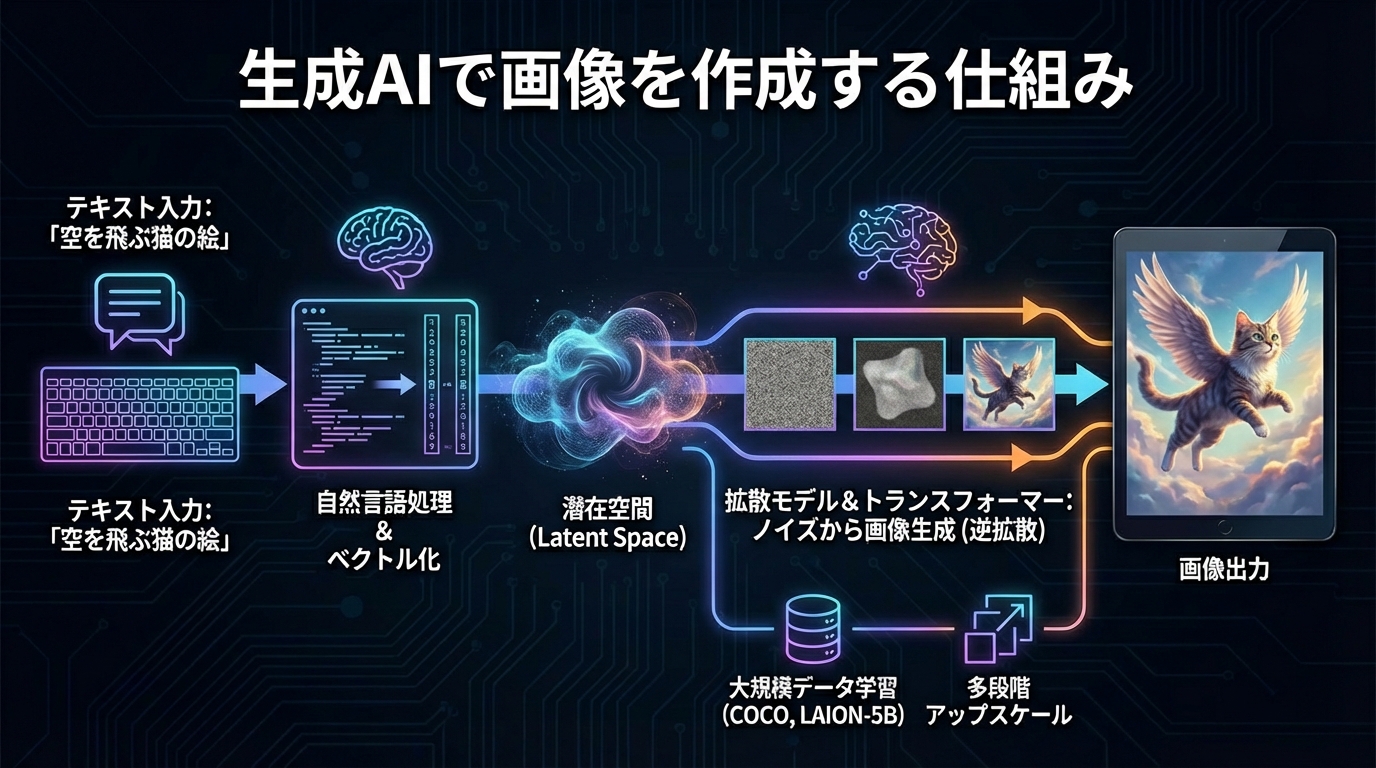
テキストツーイメージの基本
テキストツーイメージとは、文章で指示した内容から自動的に画像を生成する仕組みです。たとえば「空を飛ぶ猫の絵」と入力すれば、生成AIがその内容を解釈し、対応する幻想的な画像を出力します。これを可能にしているのは、大規模なデータ学習と自然言語処理技術です。2010年代半ばに深層学習が大きく進歩し、テキストツーイメージも飛躍的に発展しました。OpenAIのDALL-EやGoogle BrainのImagen、Stability AIのStable Diffusion、Midjourney、RunwayのGen-4など、多くの高性能モデルが登場し、2022年には実写写真と見分けがつかない水準の画像生成が実現しています(参照*1)。
これらのモデルは、入力された文章を言語モデルでベクトル化し、そのベクトルを基に画像の潜在空間を構築します。初期にはリカレントネットワーク(LSTM)やGAN(敵対的生成ネットワーク)が使われていましたが、現在はトランスフォーマーと拡散モデルが主流です。低解像度の画像を一度に生成し、それを段階的に高解像度へアップスケールする多段階手法も広く採用されています(参照*1)。学習データとしてはCOCOやLAION-5Bなどの大規模データセットが有名で、ごく短い文章からでも多様な画像バリエーションを作り出すことが可能です。
潜在拡散モデルの役割
潜在拡散モデルは、近年の生成AIで中心的な役割を果たしている画像作成技術です。これはノイズを少しずつ取り除く逆方向の工程を繰り返し、元の画像を復元していく仕組みを拡張し、テキストの条件付けを行うことで、指示されたイメージを生成します。特徴的なのは、最終的な高解像度画像を直接生成するのではなく、潜在空間を扱うことで効率的な処理を実現している点です。高画質かつ多様な応答が可能になる一方で、学習データの偏りが画像にも反映されるリスクがあると指摘されています(参照*2)。
たとえばMidjourneyやHugging Faceのサービスでは、テキスト入力だけでなく既存の画像に部分的な修正を加える機能や、複数画像を組み合わせるハイブリッド生成機能も利用できます。こうしたツールの登場により、クリエイター以外の一般ユーザーでも高品質な画像作成に取り組みやすくなりました(参照*2)。一方で、商用レベルの制作物を扱う場合は、十分な精度検証とデータライセンスの確認が重要です。
画像生成AIの活用と実務ノウハウ
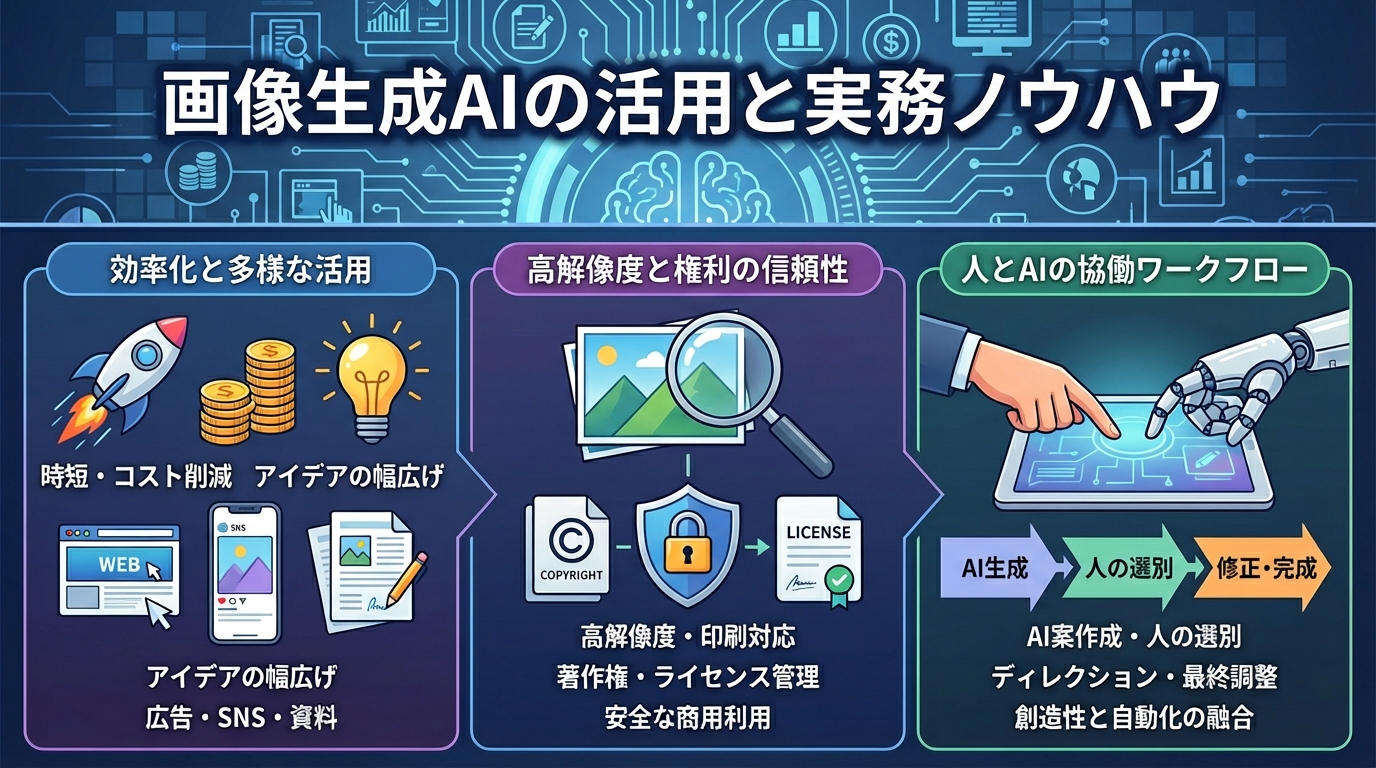
実務活用のメリット
企業や教育機関で情報発信を行う際、生成AIによる画像作成を取り入れることには多くの利点があります。たとえば広告バナーや資料用イラストを短時間で量産できるため、コスト削減や制作期間の短縮が期待できます。また、クリエイターが段階ごとにチェックしながら微調整を繰り返すよりも、まず生成AIを使ってたたき台となる案をいくつか自動で作り出すことで、効率的にアイデアの幅を広げられます。こうしたメリットは、大規模データの活用や複数モデルの連携による手法の進歩によってさらに拡大しています(参照*1)。
広告デザインやSNS投稿画像での活用事例も増えています。たとえばブログのアイキャッチ画像を瞬時に制作することで、担当者の負担を大きく軽減できます。商業施設のキャンペーンビジュアルなどにも適用され、新しい企画や表現の幅を広げる技術として活用範囲が拡大しています。ただし、実務利用ではクオリティや著作権リスク管理が重要なポイントです。
高解像度と商用利用
実務では、印刷物や大型ディスプレイなど高解像度が求められるケースも多く、生成AIはこの高解像度化にも対応する機能を備えています。イラストだけでなく写真レベルの表現でも解像度を上げる専用モデルが登場し、アップスケール時の画質劣化を抑える技術も進化しています。特にDeepFloyd IFのような研究や、Adobe Fireflyのようにライセンス取得済みコンテンツを活用するツールが増えたことで、本格的な商用利用も広がっています(参照*3)。
実務レベルの画像作成では、モデルが学習に使ったデータの著作権や成果物の利用条件(ライセンス)を正しく把握することが不可欠です。ウェブ上から取得された大量画像を無制限に使うモデルの場合、成果物に含まれる要素の権利関係が複雑になることがあります。逆に、ライセンスクリアなデータで学習された生成AIを活用することで、二次利用リスクを軽減し、トラブル回避につながります。商用利用を検討する場合は、特にこの点に注意が必要です。
効率化のポイント
生成AIを実務でスムーズに活用するには、作業プロセス全体を俯瞰し、必要な工程をうまく組み合わせることが重要です。たとえばSNS投稿用ビジュアルを量産したい場合、まずAIで複数のデザイン案を作り、人が選別し、必要に応じて手動で修正を加える手法が効果的です(参照*4)。これにより短時間で多様なイメージを絞り込み、デザイン打ち合わせの効率を高めることができます。
ビジネス現場での導入事例では、社内プレゼン資料や雑誌広告、ウェブサイトのトップイメージ制作のスピードが大きく向上したという声もあります。ここで大切なのは、人の創造的な視点と生成AIの自動化を併用することです。完全にAIに任せるのではなく、ディレクションやプロンプト設計の工夫、人による最終チェックを徹底することで、独創性と正確性の両立が可能になります。
安全性と信頼性を高めるための取り組み
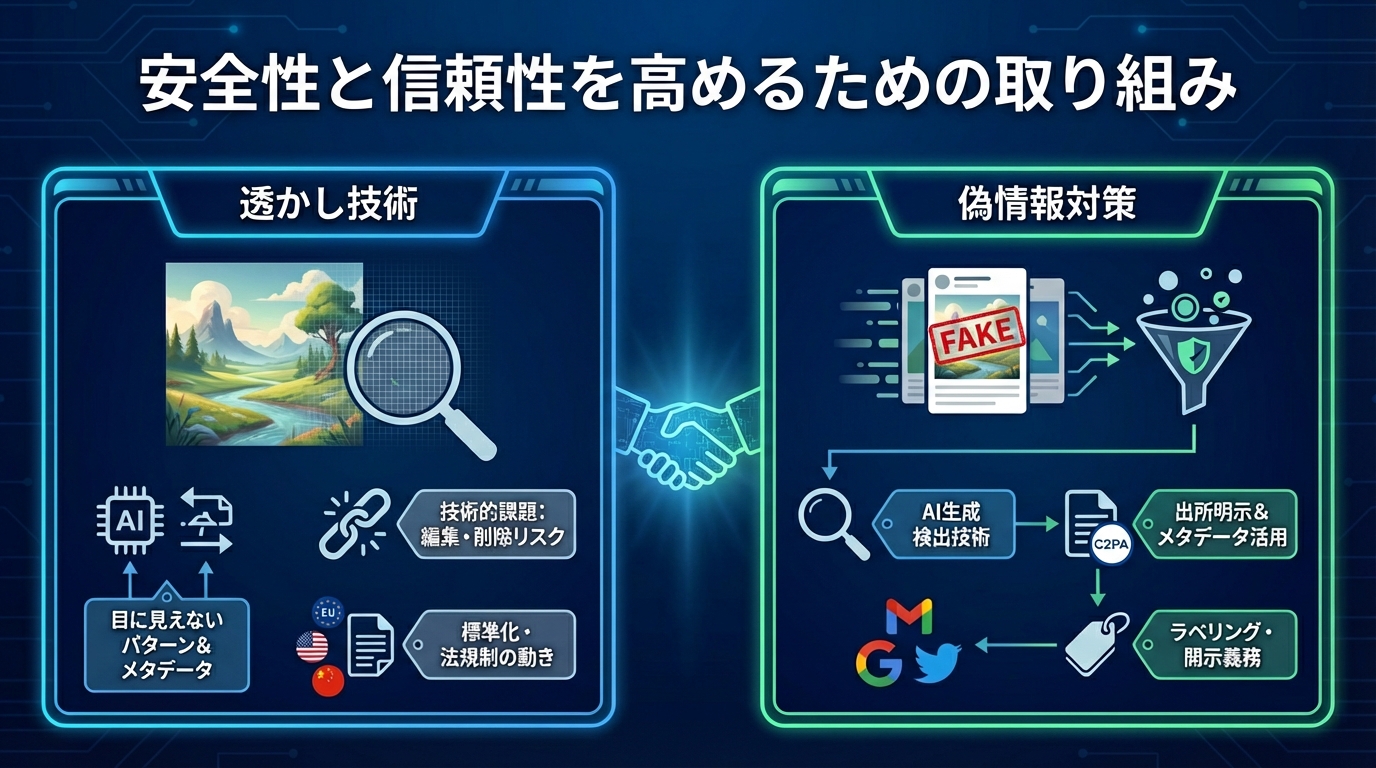
透かし技術
生成AIによる画像作成の普及に伴い、出力された画像を本物の写真と見分ける手段として透かし(ウォーターマーク)の活用が注目されています。透かしは画像の中に埋め込まれた目に見えないパターンやメタデータによって、生成AIが作成したことを後から判定できる場合があります(参照*5)。しかし、技術的に完全な対策とは言えず、画像のリサイズや編集によって透かしが消えることもあり、除去方法も開発されています。実際、Google DeepMindのSynthIDのような技術は画像の改変にもある程度耐性を持たせていますが、完全な耐久性はまだ課題です(参照*6)。
大手企業やニュース機関では、透かし技術の標準化やAI生成画像のラベリングを推進する動きが進んでいます。欧州連合(EU)のAI法では、AI生成コンテンツへの表示・ラベリング義務が規定され、米国や中国でも水印付与の法的義務化が進められています(参照*7)(参照*8)。ただし、透かしやラベルの削除・改変リスク、プライバシーや表現の自由への影響など、技術面・社会面での課題も残されています(参照*9)。
偽情報対策
画像や動画における偽情報の拡散は、生成AIの普及とともに深刻な社会課題となっています。AIを使うことで、人の目では区別が難しい偽写真が大量に作成され、インターネット上で拡散される事例が増えています。たとえば2024年の選挙時にはAI生成画像が議論を呼び、現実の報道と市民の理解を分断させかねない状況も指摘されています(参照*10)。
このような偽情報対策としては、AI生成物を検出する技術や、出所を明示するメタデータの活用が進められています。欧州連合のAI法や米国の政策では、AI生成コンテンツの開示・ラベリング義務が導入され、MetaやGoogleなどの大手企業も水印技術の開発を進めています(参照*5)。また、C2PA(Content Provenance and Authenticity)などの標準化団体が、画像や動画の出所情報や改変履歴をメタデータとして管理する仕組みを推進しています(参照*11)。
信頼性確保の課題
画像作成の精度が高まるほど、デマの拡散や著作権侵害などのリスクも増大します。各国政府は規制やガイドラインの整備を進め、研究機関や企業はAI生成物の識別技術の改良に取り組んでいます。しかし、透かし技術やコンテンツ真正性の検証は万能ではなく、技術者が新しい防御策を開発しても、同時にその抜け道を探す動きも続いています(参照*12)。
また、ユーザー側のリテラシーや判断力の差も問題を複雑にしています。巧妙な偽情報が一度広がると訂正は難しく、個人や企業、社会全体に影響を及ぼす可能性があります。最終的には、生成AIの活用にあたり倫理観や利用指針を確立し、国際的な議論や標準化の動向を注視することが求められます。
おわりに
生成AIを使った画像作成は、多様なアイデアを短時間で形にできる可能性を持つ一方で、技術の発展に伴う倫理や権利保護、誤用防止の仕組みづくりが重要な課題となっています。今後はさらに高性能なモデルが登場することが予想され、それをどのように活用し、どのような責任のもとで利用するかが問われます。
本記事では、生成AIによる画像作成がもたらす新たな表現力と、その裏側にあるリスクの両面を理解する必要性を解説しました。専門家でなくとも使える時代だからこそ、基礎知識を身につけ、より良い活用方法を模索することが今後のポイントとなります。
監修者
安達裕哉(あだち ゆうや)
デロイト トーマツ コンサルティングにて品質マネジメント、人事などの分野でコンサルティングに従事しその後、監査法人トーマツの中小企業向けコンサルティング部門の立ち上げに参画。大阪支社長、東京支社長を歴任したのち2013年5月にwebマーケティング、コンテンツ制作を行う「ティネクト株式会社」を設立。ビジネスメディア「Books&Apps」を運営。
2023年7月に生成AIコンサルティング、およびAIメディア運営を行う「ワークワンダース株式会社」を設立。ICJ2号ファンドによる調達を実施(1.3億円)。
著書「頭のいい人が話す前に考えていること」 が、82万部(2025年3月時点)を売り上げる。
(“2023年・2024年上半期に日本で一番売れたビジネス書”(トーハン調べ/日販調べ))
参照
- (*1) Text-to-image model
- (*2) SpringerLink – Democratization and generative AI image creation: aesthetics, citizenship, and practices
- (*3) App Store – Adobe Firefly:生成AIツールアプリ
- (*4) 法人向け生成AIチャットのナレフルチャット | 法人向けChatGPT・クローズド生成AIチャットサービス – うさぎでもわかるAI画像生成入門:2025年版最新ガイド
- (*5) Brookings – Detecting AI fingerprints: A guide to watermarking and beyond
- (*6) MIT Technology Review – Google DeepMind has launched a watermarking tool for AI-generated images
- (*7) Missing the Mark: Adoption of Watermarking for Generative AI Systems in Practice and Implications under the new EU AI Act
- (*8) Georgetown Journal of International Affairs – Should the United States or the European Union Follow China’s Lead and Require Watermarks for Generative AI?
- (*9) Access Now – Watermarking & generative AI: what, how, why (and why not)
- (*10) John S. Knight Journalism Fellowships – Seeing is no longer believing: Artificial Intelligence’s impact on photojournalism
- (*11) ITU – AI watermarking: A watershed for multimedia authenticity
- (*12) Electronic Frontier Foundation – AI Watermarking Won't Curb Disinformation
