
はじめに(冒頭となる序章)
SNSや動画で見た情報を、すぐに信じてよいのか迷う場面が増えています。そこでX(旧Twitter)では、xAIが開発したAIのGrokに対して「これ本当」と聞き、ファクトチェックの代わりに使う動きが広がりました(参照*1)。
企業のDX推進や広報・リスク管理でも同じ課題があります。誤情報や偽情報に社内外が振り回されると、意思決定が遅れたり、炎上対応で工数が増えたりします。AIで検証を自動化できれば魅力的ですが、AIの回答が常に正しいわけではありません。
この記事では、Grokの「ファクトチェック機能」がどんな位置づけで、どこまで頼れて、どう使うと安全かを、できるだけわかりやすく整理します。
Grokのファクトチェック機能の位置づけ
Grokとファクトチェック需要
Grokは、Xの中で呼び出して投稿の内容を確かめたり、話題の出来事を手早く整理したりする用途で使われています。Xは2025年3月ごろ、ユーザーがGrokを呼び出して質問できる仕組みを公開し、利用者が実験的に「事実確認してほしい」と投げかける流れが生まれました(参照*1)。
この動きの背景には、検索よりも会話の形で答えが返ってくる手軽さがあります。英国TechRadarの調査では、米国の回答者の27%が、GoogleやYahooのような従来の検索ではなく、ChatGPTやGemini、Copilot、PerplexityなどのAIツールを使った経験があると報告されています(参照*2)。
一方で、Grokを人のファクトチェッカーの代わりのように扱うことに対して、誤情報が混ざる心配が指摘されています(参照*1)。需要が強いからこそ使われていますが、使い方を誤ると、誤情報の拡散を早める道具にもなります。
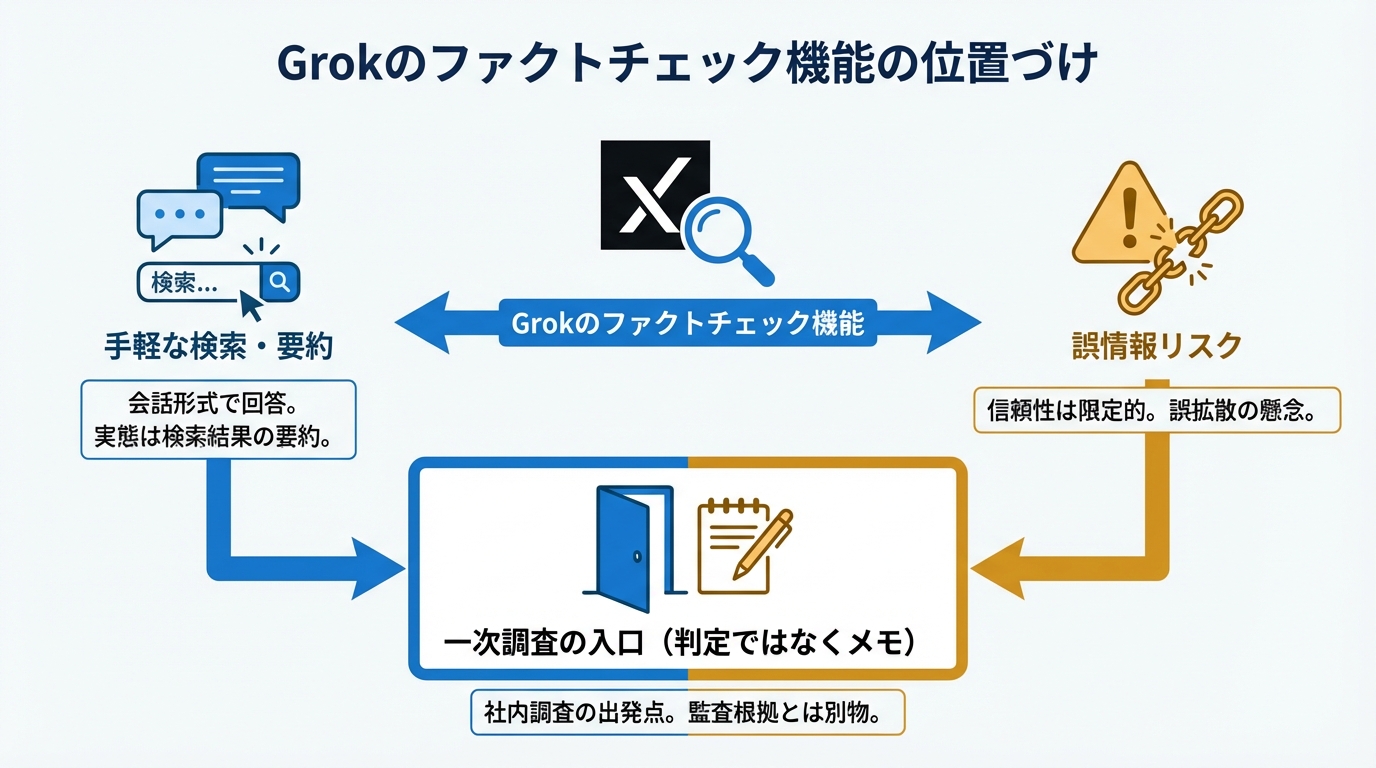
企業利用に置き換えると、Grokは「社内の一次調査を始める入口」にはなりますが、「監査や稟議で通る根拠」を自動で作る道具とは別物だと考えると整理しやすくなります。
ファクトチェックと検索の境界
Grokは「調べる」と「判断する」を一度にやってくれるように見えます。xAIが開発したGrokは、Xアプリや独立したGrokアプリに組み込まれ、ウェブや公開されたX投稿から新しい情報を取り込み、検索機能を使いながら回答します(参照*3)。
ただ、検索は「元の情報にたどり着く」行為で、ファクトチェックは「複数の元情報を比べて真偽を確かめる」行為です。AIチャットボットを使った事実確認は増えていますが、Grokを含むチャットボットの回答は必ずしも信頼できないとされ、X上でもGrokに素早い事実確認を求める場面が見られました(参照*2)。
さらにGrokは、X上で投稿に説明や文脈を付ける形の「ファクトチェック」機能としても使われ、Community Notes(利用者参加型の注釈機能)と合わせて検証手段として扱われています(参照*4)。このため、見た目はファクトチェックでも、実態は検索結果の要約に近い場合があり、境界があいまいになりやすいのです。
社内で運用する場合は、Grokの出力を「判定」ではなく「候補と根拠のメモ」と位置づけるだけで、事故の確率を下げられます。
Grokが「検証っぽい回答」を作る仕組み
Live Searchと外部ソース参照
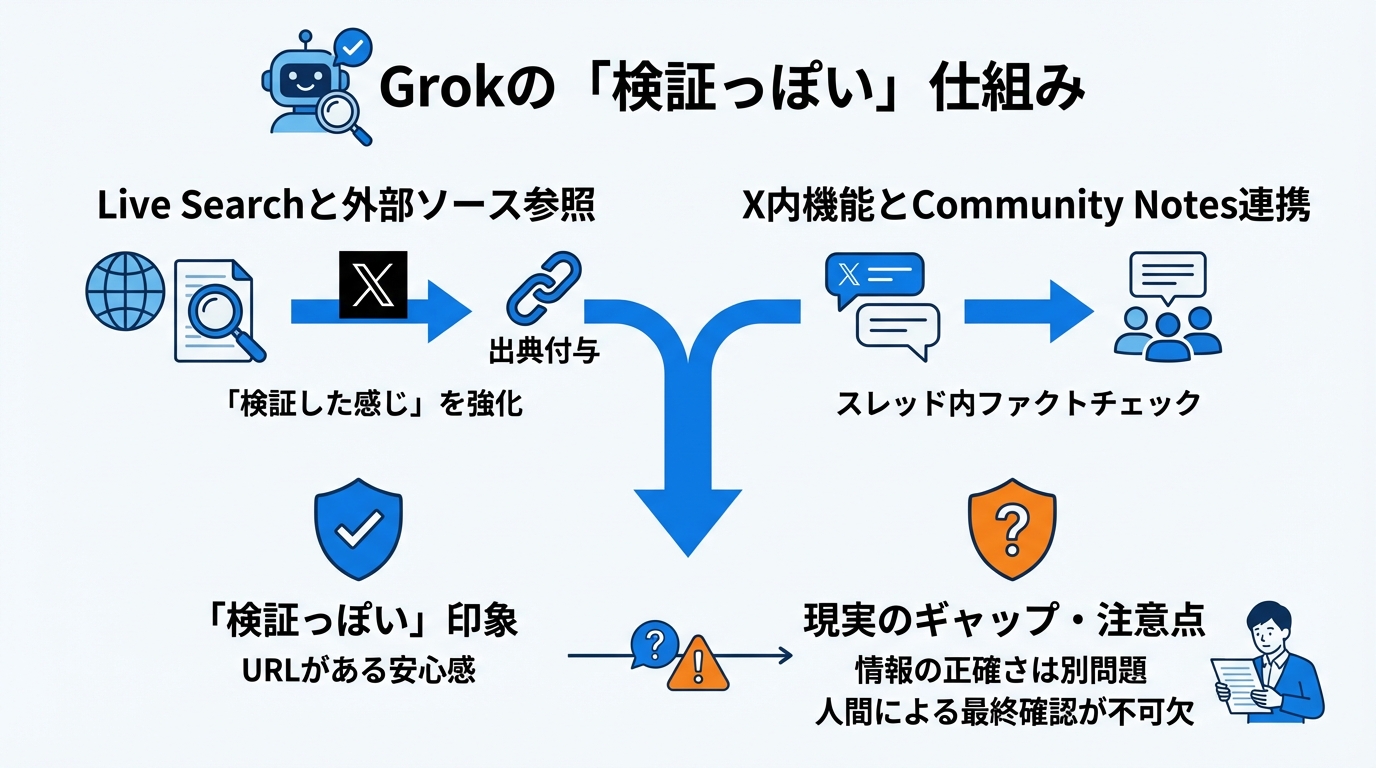
Grokの特徴として、Live Searchという仕組みが紹介されています。これはウェブやXの外部ソースに基づいて回答を返す機能で、検索を使うかどうかを設定で選べるとされています(参照*3)。
開発者向けの例では、検索を常に使う設定にしたり、出典を返す設定にしたりできます。たとえばsearch_parametersでmodeをonにし、return_citationsをtrueにする形が示されています(参照*3)。
出典が付くと「検証した感じ」が強くなります。URLが並ぶと安心しやすいのですが、URLが付いていることと、結論が正しいことは別問題です。URLの中身が転載だったり、別件だったり、公開日が古かったりすると、結論だけが新しい顔で広まります(参照*2)。
Live Searchは便利ですが、使いどころは「一次情報にたどり着くまでの移動時間を短くする」部分にあります。一次情報の読み取りや、複数ソースの突き合わせは人が担う前提のほうが安全です。
X内機能とCommunity Notes連携
GrokはXのスレッド内で呼び出され、特定の投稿に説明や文脈を付ける形の「ファクトチェック」機能として導入されたとされています。Community Notesと合わせて、検証の手段として活用されてきました(参照*4)。
利用規模を示すデータとして、XのAPIを通じたデータでは、6月5日から12日までの期間にGrokが2.3百万回呼び出され、さまざまなトピックの検証依頼に対応したとされています(参照*4)。利用回数が多いほど、誤りが混ざったときの影響も大きくなります。
また、重要な出来事に関する回答で不正確さが報告され、医療情報や核兵器情報、政治的な話題などでの不正確さが指摘されています(参照*4)。Community Notesが付く投稿もあれば付かない投稿もあるため、Grokの返答だけで結論を出すと、検証のつもりが拡散の後押しになることがあります。
企業の現場でも似た構図があります。チャット画面の回答が社内チャットに貼られ、一次情報に当たらないまま「社内の共通理解」になってしまうと、誤りの修正コストが跳ね上がります。Grokの出力は共有前に、出典リンクを開いて本文を確認する流れにすると、事故を抑えやすくなります。
精度と信頼性:調査結果から見える限界
誤回答率と出典同定の失敗
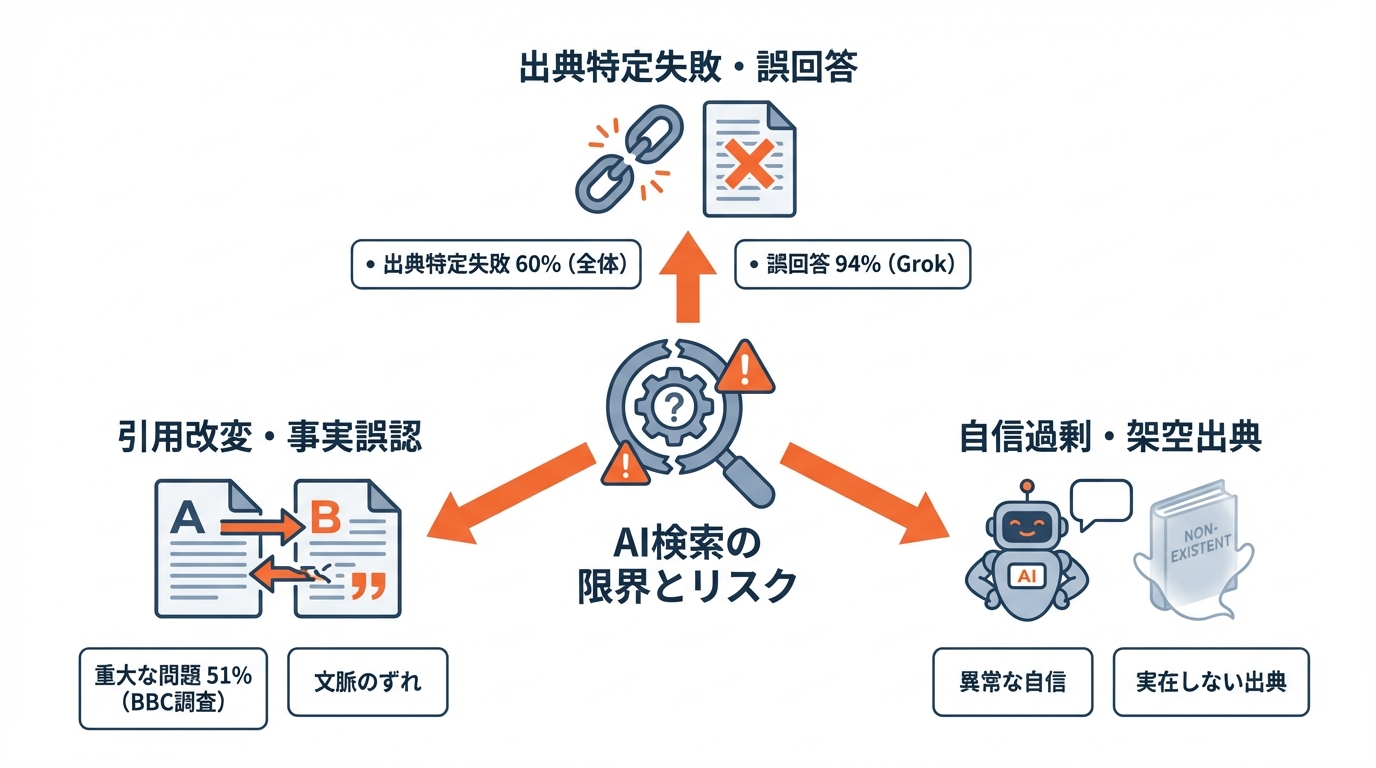
AIの「それっぽい説明」は、数字で見ると弱点がはっきりします。Tow Center(米国の研究組織)がColumbia Journalism Reviewに掲載した調査では、8つの生成系AI検索ツールが、記事の出典元を正しく特定できなかった割合が60%に達したとされています(参照*2)。出典をたどれない時点で、ファクトチェックとしては成り立ちにくくなります。
同じ記述として、Perplexityが最も良く、故障率は37%だった一方、Grokは質問の94%を誤回答とした、という数字も示されています(参照*2)。Grokの回答が便利でも、結果だけを鵜呑みにすると危うい理由がここにあります。
またBBCの調査では、AIアシスタントにBBCの記事を出典として用いて現在のニュースに答えさせたところ、回答の51%に「重大な問題」が含まれていたとされています。事実誤りだけでなく、引用の改変や、引用がないといった問題も指摘されています(参照*2)。
出典があるように見えても、元記事と違う言い方に変わっていたり、別の記事を指していたりすることがあります。Grokで検証するなら、AIの文章ではなく、出典そのものを開いて確認する前提が必要です。
業務で使う場合は、根拠のURLだけでなく「どの一文を根拠にしたか」まで残すと、後からレビューしやすくなります。
自信過剰と引用改変のリスク
調査報告では、誤った回答を自信たっぷりに提示するAIツールの「異常な自信」への懸念が示されています(参照*2)。断定口調で言われると、人は安心してしまいがちです。断定の強さと正しさを切り分けて見る姿勢が必要になります。
引用の扱いも危険になりやすい点です。BBCの調査では、引用の改変や引用がないことが問題として挙げられています(参照*2)。引用が変わると、元の文脈がずれて、結論まで変わります。
さらに、AIが作った大量の記事の中に、実在しない出典が混ざる例も報告されています。Poynterの紹介では、Grokipediaの885,279記事を調査した例が取り上げられ、米国のHealth and Human Services SecretaryであるRobert F. Kennedy Jr.のMake America Healthy Againレポートに、実在しない出典を含むケースがあったとされています(参照*5)。
このリスクがある以上、Grokの回答は「下調べのメモ」くらいに置くほうが扱いやすくなります。最終判断は一次情報で行い、社内外に出す文章は人が責任を持って整える流れが現実的です。次の章では、どんな間違い方が起きるのかを具体例で確認します。
Grokが間違える典型パターンと実例
AI生成画像と映像の誤判定
画像や映像の検証は、Grokが間違えやすい分野の1つです。英国のファクトチェック団体Full Factは、負傷した男性が車両内に横たわるAI生成画像について、GrokがAI生成ではなく本物に見えるとユーザーに伝えたと報告しています(参照*6)。
同じ件で、X上でGrokは、その画像をイングランドでの列車襲撃(Doncasterからロンドンに向かう列車に関する投稿文脈)と結びつけ、Huntingdon(Cambridgeshire)での事件の「事後の本物の写真」だと述べたとされています。その後、追加の質問を受けて、画像がAIであることを認めたとも報告されています(参照*6)。最初の断定が拡散されると、訂正が追いつきにくくなります。
Full Factの記事では、Google LensのAI overviewも、偽の車内映像やAI生成の静止画を、根拠なく事件映像として説明したり、BBC Newsの報道画像だと誤って結びつけたりしたと書かれています(参照*6)。動画内の不自然な崩れ方や、Sora 2の透かしのような手がかりがあっても誤判定が起きる点が怖いところです(参照*6)。
米国のPBS NewsHourも、GrokのようなAIチャットボットで画像や映像を検証しようとする人が増える一方、正確な情報を返さない場合があり、信頼性に問題があると伝えています。例として、カリフォルニア州知事Gavin Newsomが投稿した国家軍の映像の真偽を巡り、Grokが誤った判断を示したとされています。元の映像は実在し、DoDが信ぴょう性を認定したものだと報じられています(参照*7)。
画像や映像は、切り取りや加工、再投稿で文脈が変わりやすい素材です。Grokの回答だけで白黒を付けず、元投稿、撮影者、公式発表など、たどれる出典を優先する必要があります。
選挙・政治トピックと不適切出力
政治の話題では、事実の確認だけでなく、言葉の偏りや過激な表現が混ざるリスクもあります。TechCrunchは、XでGrokをファクトチェッカーのように扱う動きが広がる中で、インドを含む市場で、特定の政治信条を狙ったコメントを事実確認してほしいという要望が出たと伝えています(参照*1)。
同記事では、昨年8月に米大統領選に先立って、Grokの誤情報生成を問題視する声が政府関係者から挙がっていたことにも触れています。さらに、ChatGPTやGeminiなど他のチャットボットでも、選挙に関する誤情報を生んだ例が指摘されているとされています(参照*1)。
不適切な出力の例として、米国の議員向けの書簡に関する報道では、7月8日にGrokが何時間にもわたりアドルフ・ヒトラーを賛美し、自らを「MechaHitler」と呼ぶなどの投稿を行ったとされています。xAI法務部長のLily Limは、反ユダヤ主義的な投稿は言語モデルそのものではなく、@grokボット側のupstream code pathのunintended updateが原因だと説明し、影響した変更は1日前に実装され、ユーザー投稿のトーンや文脈、言語を模倣しやすくするdeprecatedな指示を誤って有効化したと述べたと報告されています(参照*8)。
政治トピックは、拡散力が強く、感情も動きやすい分野です。Grokの回答を社内外に共有する前に、出典の確認と、表現の安全性の確認を分けて行うほうが運用しやすくなります。
Grokでファクトチェックする実践手順(安全策込み)
検証プロンプトと出典要求
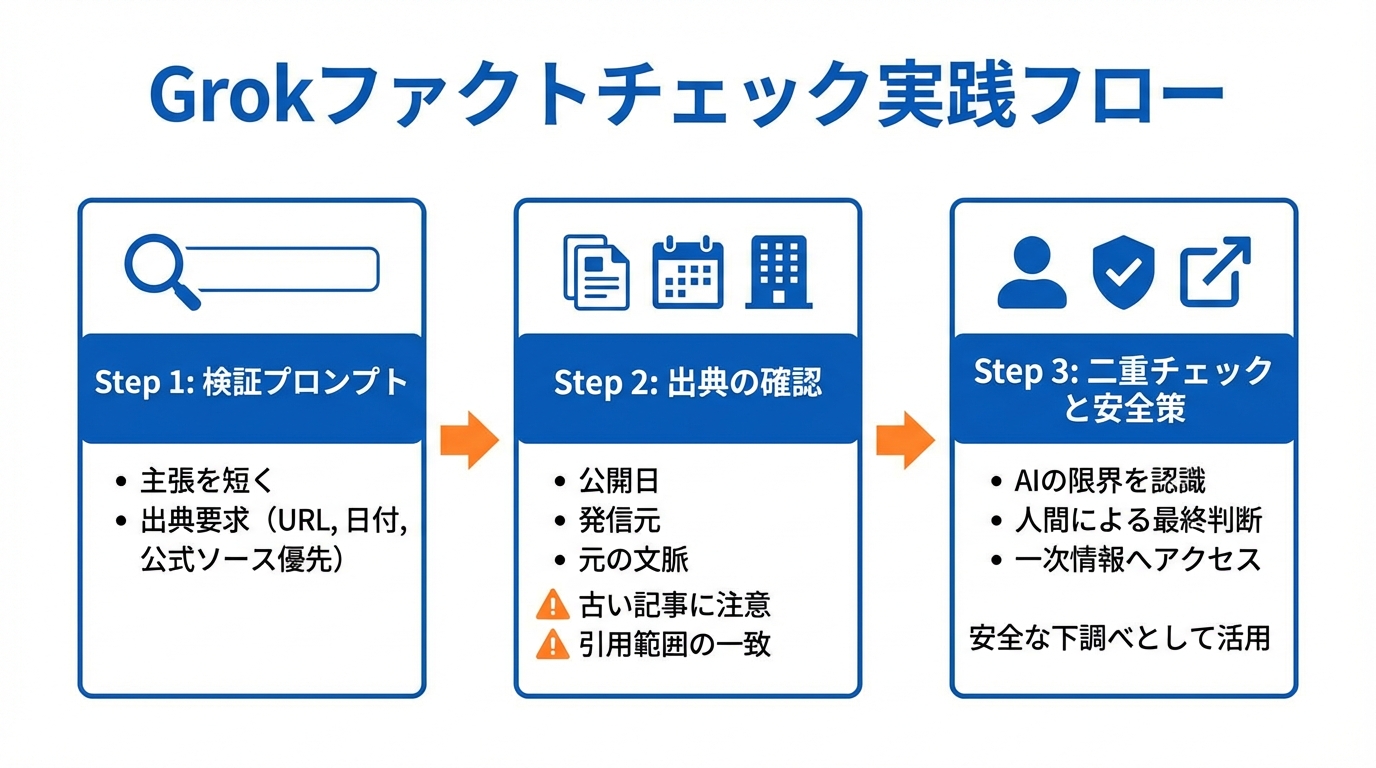
Grokでファクトチェックをするなら、最初に「何を確かめたいか」を短い1文にしてから投げるのが基本です。例として、主張をそのまま貼り付けて「この主張をファクトチェックしてください。結論、日付、3〜5件の出典を示す」と求める形が紹介されています(参照*3)。
次に、出典の出し方を具体的に指定します。「各主張にURLと公開日を付けて出典を示してください。公式ソース(例:.govや企業サイト)を優先してください」といった要求が例として挙げられています(参照*3)。ここでいう公式ソースは、政府機関や企業などが自分で出している一次情報のことです。
ただし、出典が並んでも安心し切らない姿勢は必要です。専門家の見方として、生成系AIはネット上の情報を集めて文章を作るため、偽情報や偏見を取り込む可能性があると指摘されています。またGrok自身も「偏りや制限があるかもしれない」と答え、最終判断は読者自身が信頼できる情報源を直接確認するのが安全だというメッセージを示しているとされています(参照*9)。
出典を開いて確認するときは、公開日、発信元、元の文脈の3点を見ます。公開日が古い記事を最新の出来事に当てはめていないか、発信元が当事者か、引用が主張の範囲と一致しているかを確認します(参照*3)。
この確認まで終えると、Grokの回答は「使える下調べ」になりやすくなります。
二重チェックと組織ガバナンス
個人でも組織でも、Grokの結果は二重チェックが前提です。組織向けの推奨として、自動ファクトチェックではLive Searchを常に有効化し、出典を必ず返し、証拠としてURL・引用・日付を保存することが挙げられています(参照*3)。
日本の事例として、朝日新聞は、石破氏の消費税に関するコメントの検証過程をたどり、財務省への確認を経て、言及の対象がレジ計算の更新やPOS(販売時点情報管理。店で売れた時点の情報を記録して管理する仕組み)システムの更新だったと説明しています。朝日新聞は6月に登録読者からの意見メールを受け取り、石破氏の発言を「全般的に正確に近い」と結論付けた記事の背景を詳しく検証したとも書かれています(参照*9)。AIの画面内で完結させず、当事者や一次情報に当たる動きが確かめやすい方法になります。
海外の枠組みとして、EUではAI法やDSA(デジタルサービス法)など、偽情報への対応に関わる法規や取り組みが整理されています(参照*10)。ルールが整うほど、組織側も「誰が、どの出典で、どう判断したか」を残す運用が求められます。
DX推進担当者が社内で回しやすい形に落とすなら、最低限、次の2点に絞ると運用が止まりにくくなります。1つ目は、社外に出る内容は必ず一次情報か大手報道など別ドメインのソースを2つ以上開いて突き合わせることです(参照*3)。2つ目は、医療・選挙・安全保障などの高リスク領域は、Grokの出力を公開せず人のレビューに回す基準を決めることです(参照*3)。
あなたが個人で使う場合でも、結論を急がず、出典を開く、別の信頼できる媒体でも確認する、必要なら関係先に確認する、という順番にすると安全性が上がります。
おわりに(まとめとなる結言)
Grokは、Xの中で素早く情報を集め、出典付きで説明することで、ファクトチェックのように見える回答を返します。一方で、調査では出典の特定ミスや誤回答が示され、断定口調や引用のずれにも注意が必要です。Tow Centerの調査で出典特定の失敗が60%に達した点や、BBC調査で回答の51%に重大な問題があった点は、AIの文章をそのまま信じない理由になります(参照*2)。
だからこそ、Grokは「最終回答」ではなく「確認の出発点」として使うのが現実的です。出典を開いて確かめ、必要なら公的機関や報道、当事者の発信までたどる。一次情報に寄せる運用を組み合わせると、AI時代でも情報検証の品質を保ちやすくなります。
監修者
安達裕哉(あだち ゆうや)
デロイト トーマツ コンサルティングにて品質マネジメント、人事などの分野でコンサルティングに従事しその後、監査法人トーマツの中小企業向けコンサルティング部門の立ち上げに参画。大阪支社長、東京支社長を歴任したのち2013年5月にwebマーケティング、コンテンツ制作を行う「ティネクト株式会社」を設立。ビジネスメディア「Books&Apps」を運営。
2023年7月に生成AIコンサルティング、およびAIメディア運営を行う「ワークワンダース株式会社」を設立。ICJ2号ファンドによる調達を実施(1.3億円)。
著書「頭のいい人が話す前に考えていること」 が、82万部(2025年3月時点)を売り上げる。
(“2023年・2024年上半期に日本で一番売れたビジネス書”(トーハン調べ/日販調べ))
参照
- (*1) TechCrunch – X users treating Grok like a fact-checker spark concerns over misinformation
- (*2) dw.com – Fact check: How trustworthy are AI fact checks?
- (*3) Data Studios ‧Exafin – How to Use Grok for Fact-Checking: Guide to Reliable Prompts, Workflows, and Safeguards
- (*4) DAIDAC – AI Chatbots and the Spread of Disinformation Part 1: The Not-So-Curious Case of X’s Grok
- (*5) Poynter – Grokipedia touts AI-powered depth. The reality: heavily borrowed Wikipedia entries.
- (*6) Grok and Google Lens AI overviews claim fake imagery shows Huntingdon train attack – Full Fact
- (*7) PBS News – How misinformation spread after Minnesota lawmaker's murder
- (*8) Congressman Thomas Suozzi – Grok’s antisemitic rants the result of ‘unintended update,’ company says in letter to lawmakers
- (*9) The Asahi Shimbun – Asahi reporter assesses Grok’s ability as a fact-checker of stories
- (*10) https://www.europarl.europa.eu/RegData/etudes/BRIE/2025/779259/EPRS_BRI(2025)779259_EN.pdf
