
はじめに
AI音声合成は、テキストを入力するだけで人間のような自然な声を生成でき、コンテンツ制作や多言語対応の現場で欠かせない技術になりつつあります。その中でもQwen3-TTSは、10言語への対応や声質の複製、説明文からの声の創出といった機能を1つのモデル群にまとめた点で大きな存在感を示しています。
この記事では、Qwen3-TTSの基本的な定義から技術的な仕組み、ベンチマーク結果、そして実際にデモを試す方法までを順に取り上げます。導入時に押さえておきたい制約や注意点もあわせて確認していきます。
Qwen3-TTSとは?基本的な定義と開発背景
Alibaba Cloud Qwenチームによる開発経緯
Qwen3-TTSは、Alibaba CloudのQwenチームがオープンソースとして公開した音声合成モデル群です。テキストから自然で人間らしい音声を生成するだけでなく、説明文から新しい声を作るボイスデザインや、手元の短い音声から話者の声質を複製するボイスクローンなどを同一系列のモデルとして提供しています。リポジトリはApache-2.0ライセンスで公開されており、商用・非商用を問わず利用しやすい形態です(参照*1)。
モデルのサイズとしては、Qwen3-TTS-12Hz-1.7B-Baseが4.54GB、Qwen3-TTS-12Hz-0.6B-Baseが2.52GBとなっています。トークナイザーとモデルの両方がApache 2.0ライセンスの下で公開されているため、コミュニティでの研究開発も進めやすい構成です(参照*2)。自分の環境で扱えるモデルサイズかどうかを事前に確認しておくとスムーズです。
対応言語と学習データの規模
Qwen3-TTSは、多言語対応・制御可能・堅牢・ストリーミング対応を掲げた音声合成モデル群です。総計約500万時間以上の音声データを用いて学習されており、10言語をサポートしています。3秒程度の音声による声質クローンと、説明文ベースの制御が可能な点も特徴です(参照*3)。
対応する10言語には、中国語、英語、ドイツ語、イタリア語、ポルトガル語、スペイン語、日本語、韓国語、フランス語、ロシア語が含まれます。多言語TTSテストにおいて、平均の単語誤り率がMiniMax、ElevenLabs、GPT-4o-Audio-Previewよりも低い結果を示しています(参照*4)。利用したい言語が含まれているかを事前にリストで照合しておくと安心です。
Qwen3-TTSの技術的な仕組みとアーキテクチャ
Qwen3-TTS-Tokenizer-12Hzによる音声表現
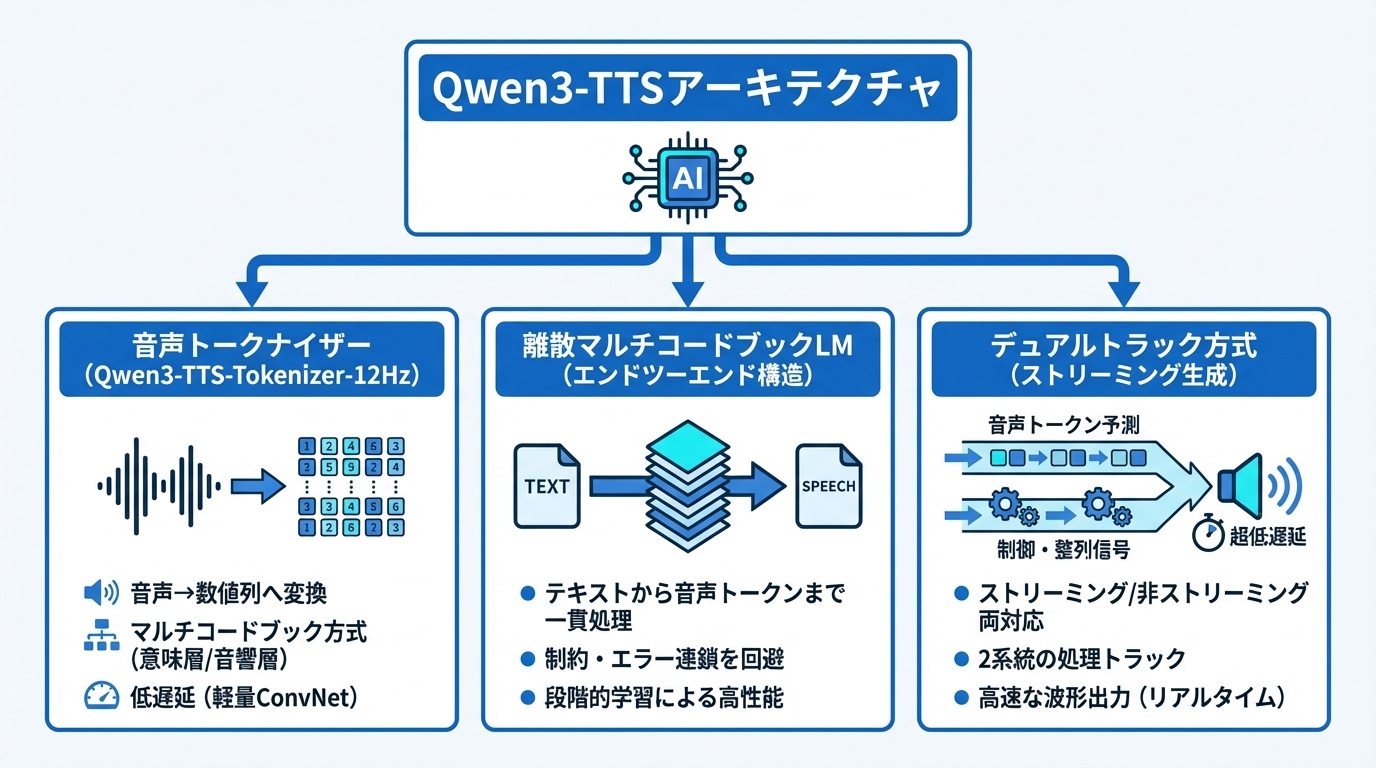
Qwen3-TTSの音声表現を支えているのが、Qwen3-TTS-Tokenizer-12Hzと呼ばれる音声トークナイザーです。これは音声を数値の列に変換する部品で、12.5Hzのマルチコードブック方式を採用しています。最初のコードブック層が意味に関する情報を捉え、後続の層が音響的な細かいニュアンスを扱うという構造です(参照*5)。
より具体的には、12.5フレーム毎秒という速度で処理し、1トークンあたり約80ミリ秒に相当します。量子化コードブックは16層構成です。情報の容量を増やしながらも、軽量な因果ConvNetのみで波形を再構成できるため、発話の遅延を抑えることに貢献しています(参照*6)。音声品質としては、LibriSpeechのテストでPESQ広帯域3.21、STOI 0.96、UTMOS 4.16を記録しており、他のトークン化手法よりも高い性能を維持しています(参照*6)。
離散マルチコードブックLMのエンドツーエンド構造
Qwen3-TTSは離散マルチコードブックLMと呼ばれるアーキテクチャを採用しています。これはテキストから音声トークンまでを一貫して処理する仕組みで、従来のLMとDiTを組み合わせる方式にあった情報の制約やエラーの連鎖を回避します。柔軟性と生成効率、そして性能の向上を同時に実現する設計です(参照*7)。
学習は3つの事前学習段階に分かれています。まず一般的なテキストと音声の対応を学び、次に高品質データで精度を引き上げ、最後に長い文脈まで扱えるように拡張します(参照*6)。段階的な学習によって、短い文から長い文章まで安定した品質を保つ構成になっています。
デュアルトラック方式による超低遅延ストリーミング生成
Qwen3-TTSは、デュアルトラック方式と呼ばれるハイブリッドストリーミング生成により、1つのモデルでストリーミング生成と非ストリーミング生成の両方に対応できます。テキストから離散的な音響トークンを予測するトラックと、整列や制御信号を扱うトラックの2系統を持つ構造です(参照*8)。
ストリーミング時は純粋な左コンテキストデコーダとして動作し、十分なトークンが揃った時点で波形を出力します。1パケットあたり320ミリ秒の音声を含み、0.6Bモデルと1.7Bモデルのいずれでも最初のパケット遅延は約97から101ミリ秒、リアルタイムファクターは約0.29から0.31です(参照*6)。1文字入力後すぐに最初の音声パケットを出力できるため、エンドツーエンドの合成遅延は最大97ミリ秒と報告されています。対話型の用途で遅延がどの程度許容されるかを事前に見積もっておくと、導入判断に役立ちます。
Qwen3-TTSのモデル種類と主な機能
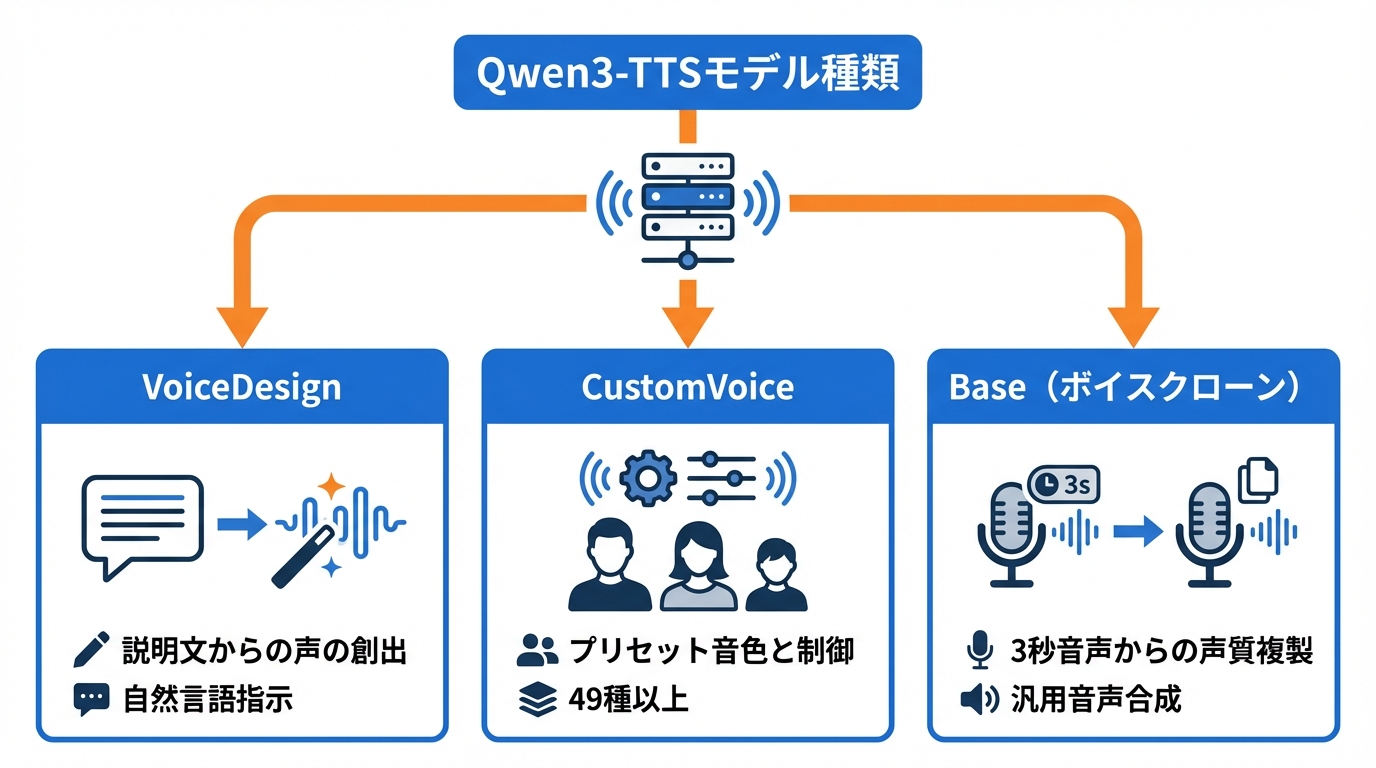
VoiceDesign:説明文からの声の創出
VoiceDesignは、自然言語の説明文から自由形式の声を作成できるモデルです。generate_voice_designという関数にターゲットとなるテキストと指示文を渡すことで、その説明に合った声の音声を得られます(参照*9)。
たとえば「落ち着いた中年男性の声」のように言葉で表現するだけで、それに近い声質の音声が生成されます。さらに、生成した声のデザインをボイスクローンと組み合わせることで、一貫性のある声を作り出すワークフローも用意されています。利用したい場面に合わせて、どのような指示文を書けば望む声に近づくかをあらかじめ検討しておくと効率的です。
CustomVoice:プリセット音色と自然言語による制御
CustomVoiceは、あらかじめ用意されたプリセット話者を使って音声を生成できるモデルです。0.6Bと1.7Bの2サイズが用意されており、generate_custom_voiceという関数にテキスト、言語、話者、指示を渡して利用します。get_supported_speakersやget_supported_languagesで対応する話者と言語を確認できます(参照*10)。
音色のバリエーションは49種類以上が提供されており、性別、年齢、地域特性、役柄設定など多様な場面を想定した声が揃っています(参照*4)。どのプリセット話者が自分の用途に合うかを事前にリストで比較し、指示文による微調整と組み合わせて声の方向性を決めると実用的です。
Base(Voice Clone):3秒音声からの声質複製
Baseモデルはボイスクローンと汎用的な音声合成の両方を担うモデルです。参照音声とその書き起こしテキストを入力することで、話者の声質を複製した音声を生成できます。0.6Bと1.7Bの2サイズが公開されています(参照*6)。
必要な参照音声はわずか3秒程度です。短い録音データから声の特徴を取り出し、任意のテキストをその声で読み上げさせることができます。GPUと数GBのVRAMがあれば利用可能で、Webブラウザからもアクセスできる環境が用意されています(参照*2)。クローン元の音声品質が出力に影響するため、ノイズの少ない録音を用意しておくことが望ましいです。
ベンチマークと他モデルとの比較
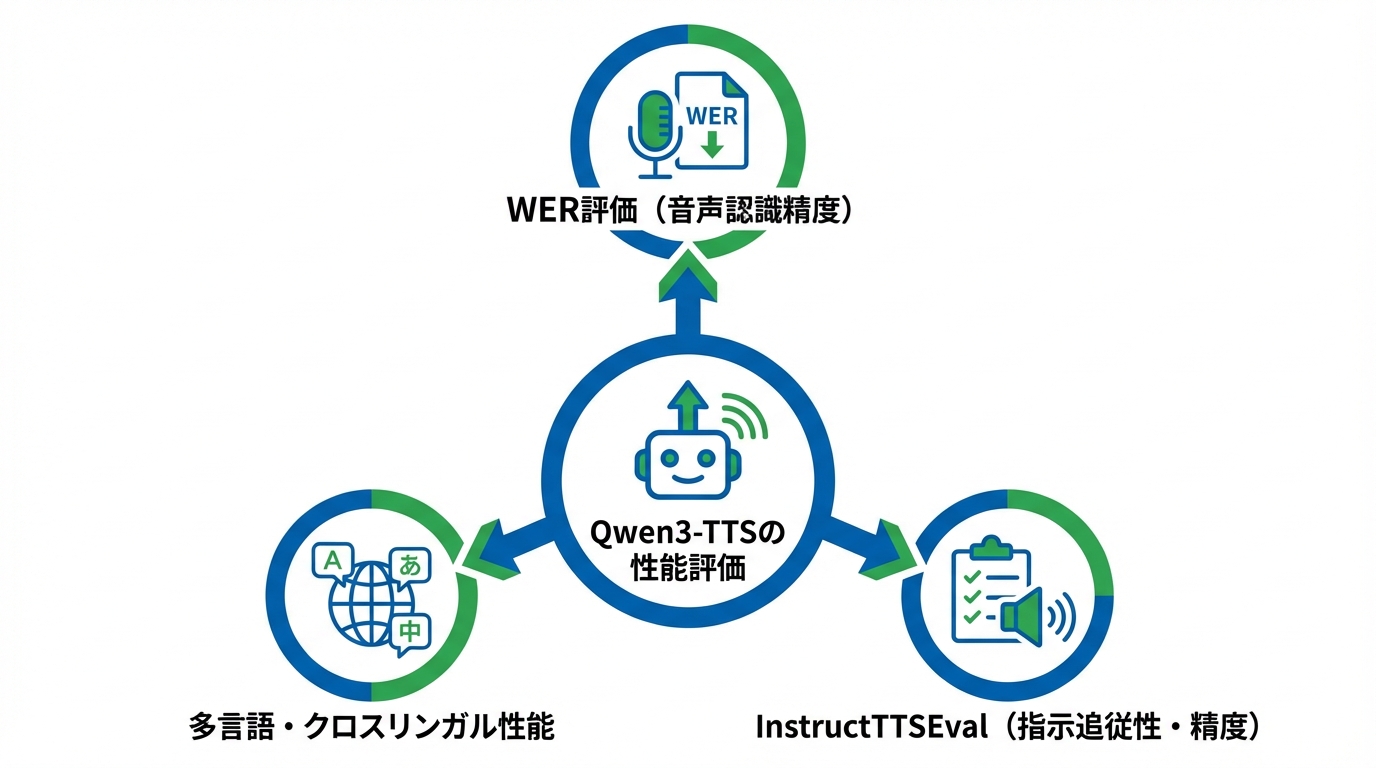
Seed-TTSテストセットでのWER評価
Qwen3-TTSの音声品質を客観的に測る指標の1つが、Seed-TTSテストセットにおける単語誤り率、つまりWERです。WERは生成された音声を音声認識にかけたときの誤り率で、数値が低いほど正確に発話できていることを示します。Qwen3-TTS-12Hz-1.7B-Baseは英語のtest-enでWER 1.24、中国語のtest-zhでWER 0.77を記録しました(参照*11)。
英語のWERは同種の公開モデルの中で最先端に近い水準です。中国語のWERはCosyVoice3の最高値には及ばないものの、高い性能を示しています(参照*6)。自分が主に使いたい言語のWERを確認し、求める精度に達しているかどうかを判断の材料とすることが有効です。
多言語・クロスリンガル生成とInstructTTSEvalの結果
10言語を対象とした多言語TTSテストでは、Qwen3-TTSは6言語で最も低いWERを記録しました。残り4言語でも競合的な成績を示すとともに、全言語において話者類似度が最高水準に達しています。言語をまたいだクロスリンガル評価では、中国語から韓国語への変換の誤差率がCosyVoice3と比べて約66%低減しています(参照*6)。
InstructTTSEvalでは、Qwen3-TTS-12Hz-1.7B-VD VoiceDesignがDescription-Speech ConsistencyとResponse Precisionの両指標で、オープンソースモデルの中で新たな基準を示したとされています(参照*6)。商用システムとの比較でも競争力のある結果です。複数言語を横断して使う用途や、テキスト指示で声を設計する場面での精度を見極める際に、これらの評価指標が参考になります。
Qwen3-TTSの導入手順とデモの試し方
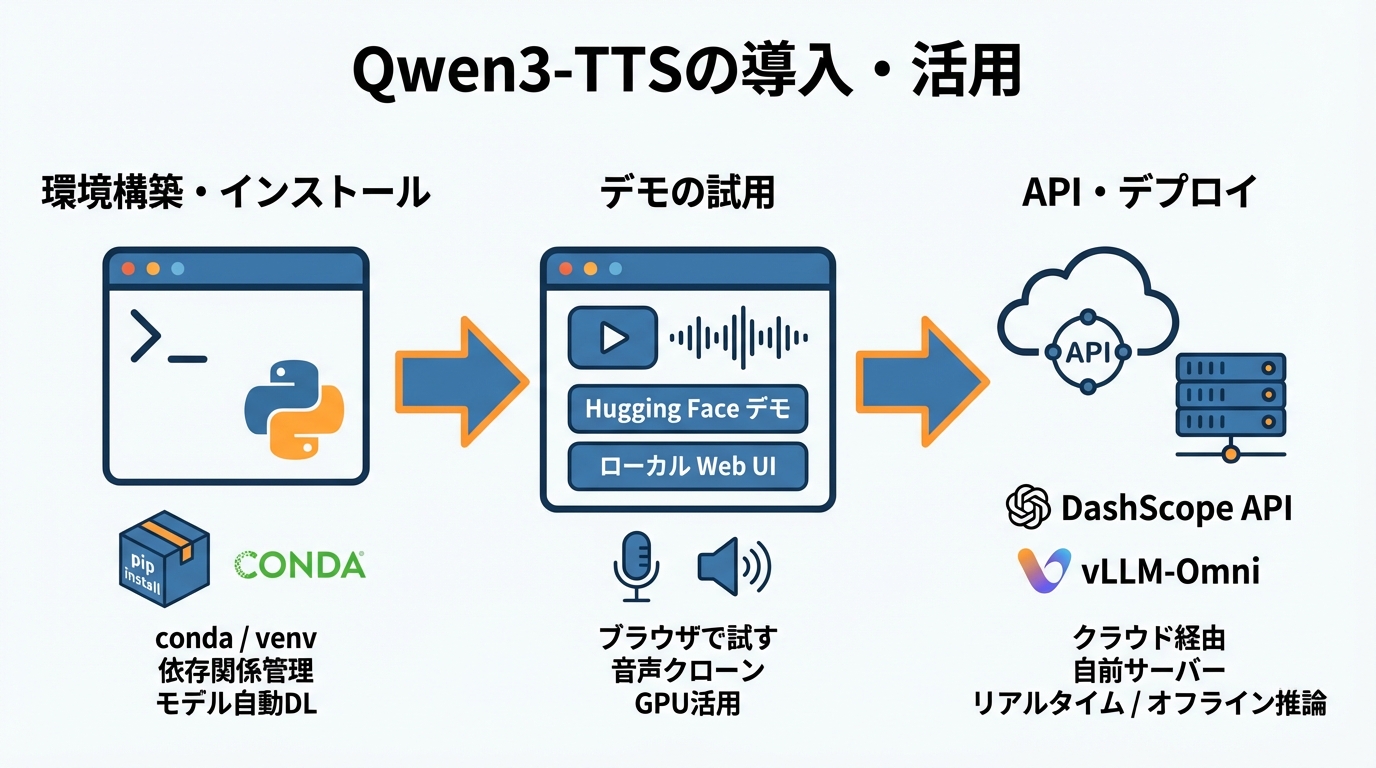
環境構築とPythonパッケージのインストール
Qwen3-TTSを手元で使い始めるには、まずPython環境を整えます。依存関係の衝突を避けるため、新しい仮想環境を作成することが推奨されています。Python 3.12環境の場合、conda create -n qwen3-tts python=3.12 -yで環境を作り、conda activate qwen3-ttsで有効化したあと、pip install -U qwen-ttsを実行するとPyPIからパッケージを取得できます(参照*8)。
condaを使わない場合でも、venvなどで分離した環境を用意しておけば同様に進められます。パッケージのインストール後、モデルのダウンロードが自動的に行われるため、ストレージの空き容量も事前に確認しておくと安心です。0.6Bモデルで約2.52GB、1.7Bモデルで約4.54GBが目安となります。
ローカルWeb UIデモとHugging Faceデモの活用
コードを書かずに手早く試したい場合は、Hugging Faceのデモが便利です。0.6Bと1.7Bのモデルをブラウザ上で無料で試用でき、音声クローン機能も利用できます。GPUと数GBのVRAMがあればローカル環境でも動かせますし、Webブラウザからアクセスするだけでも音声を生成できます(参照*2)。
ローカルでWeb UIを立ち上げる場合はGradioベースのインターフェースが用意されています。テキストを入力して音声を聴き比べるだけでなく、参照音声をアップロードしてボイスクローンの品質を確かめることもできます。まずはHugging Faceのデモで生成結果を確認し、本格利用が見えてきたらローカル環境を構築するという順序が効率的です。
DashScope APIとvLLMによるデプロイ
クラウドAPI経由で利用する場合は、DashScopeが選択肢になります。Pythonではmodelにqwen3-tts-flashを指定し、textに読み上げたい文章を与えます。voiceにはCherryなどの話者名を設定し、streamをtrueにすると分割データをリアルタイムで受け取れます。コード上ではdashscope.MultiModalConversation.callを呼び出し、APIキーは環境変数DASHSCOPE_API_KEYから取得する形です(参照*12)。
自前のサーバーにデプロイしたい場合は、vLLM-Omniを使ったオフライン推論が利用できます。CustomVoice、VoiceDesign、Baseの各タスクに対応しており、用途に合ったモデルを指定して推論を実行します(参照*13)。API経由の手軽さか、自前デプロイの自由度か、利用規模とレイテンシの要件をもとに選択するとよいです。
Qwen3-TTS導入時の注意点と制約
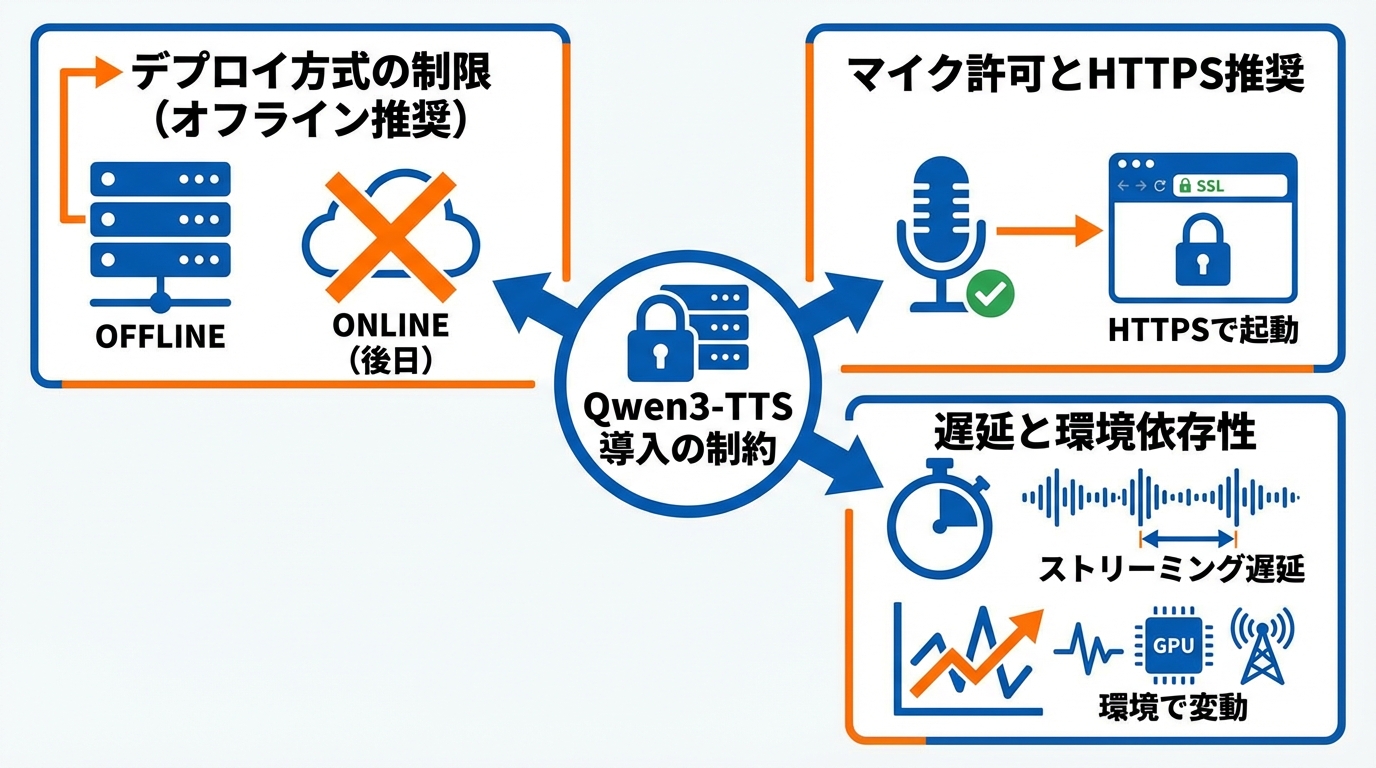
Qwen3-TTSを導入する際にはいくつかの制約を把握しておく必要があります。vLLM-Omniを用いたデプロイでは、現時点ではオフライン推論のみ対応しており、オンライン提供は後日対応予定とされています(参照*9)。リアルタイムのAPIサービスを構築したい場合は、DashScope APIを利用するか、オンライン対応のアップデートを待つ必要があります。
Baseモデルでボイスクローン機能を使う際には、ブラウザのマイク許可に関する制約もあります。マイクアクセスの問題を回避するため、HTTPSでGradioサービスを起動することが推奨されています。SSL証明書の生成とHTTPS起動の手順が公式リポジトリで案内されているため、デプロイ前にその手順を確認しておくことがポイントです(参照*8)。
ストリーミング生成では1パケットあたり320ミリ秒の音声が含まれ、最初のパケット遅延は約97から101ミリ秒です。リアルタイムファクターは0.6Bモデルと1.7Bモデルで約0.29から0.31となっています。GPU性能やネットワーク環境によって実際の遅延は変動するため、想定する利用環境で実測してから本番に組み込む手順を踏むとよいです。
おわりに
Qwen3-TTSは、500万時間以上の学習データと10言語対応、そしてボイスデザインやボイスクローンといった多彩な機能を1つのモデル群にまとめた音声合成の選択肢です。Apache-2.0ライセンスによるオープンソース公開も、導入の敷居を下げる要因になっています。
実際に試す際は、まずHugging Faceのデモで生成品質を確認し、次にローカル環境やAPIでの運用を検討するという流れが実践的です。対応言語のWERや遅延の数値をもとに、自分の用途に合うかどうかを見極めてみてください。
監修者
安達裕哉(あだち ゆうや)
デロイト トーマツ コンサルティングにて品質マネジメント、人事などの分野でコンサルティングに従事しその後、監査法人トーマツの中小企業向けコンサルティング部門の立ち上げに参画。大阪支社長、東京支社長を歴任したのち2013年5月にwebマーケティング、コンテンツ制作を行う「ティネクト株式会社」を設立。ビジネスメディア「Books&Apps」を運営。
2023年7月に生成AIコンサルティング、およびAIメディア運営を行う「ワークワンダース株式会社」を設立。ICJ2号ファンドによる調達を実施(1.3億円)。
著書「頭のいい人が話す前に考えていること」 が、82万部(2025年3月時点)を売り上げる。
(“2023年・2024年上半期に日本で一番売れたビジネス書”(トーハン調べ/日販調べ))
参照
- (*1) GIGAZINE – 日本語を含む10言語に対応した音声生成モデル「Qwen3-TTS」ファミリーがオープンソース化
- (*2) Simon Willison’s Weblog – Qwen3-TTS Family is Now Open Sourced: Voice Design, Clone, and Generation
- (*3) Qwen/Qwen3-TTS-12Hz-0.6B-Base · Hugging Face
- (*4) Qwen3-TTS全面升级:声情并茂,语通八方-阿里云开发者社区
- (*5) Qwen3-TTS Technical Report
- (*6) MarkTechPost – Qwen Researchers Release Qwen3-TTS: an Open Multilingual TTS Suite with Real-Time Latency and Fine-Grained Voice Control
- (*7) PyPI – qwen-tts
- (*8) GitHub – QwenLM/Qwen3-TTS: Qwen3-TTS is an open-source series of TTS models developed by the Qwen team at Alibaba Cloud, supporting stable, expressive, and streaming speech generation, free-form voice design,
- (*9) Qwen/Qwen3-TTS-12Hz-1.7B-Base · Hugging Face
- (*10) Qwen/Qwen3-TTS-12Hz-1.7B-CustomVoice · Hugging Face
- (*11) Qwen/Qwen3-TTS-12Hz-1.7B-VoiceDesign · Hugging Face
- (*12) Qwen-TTS API-大模型服务平台百炼(Model Studio)-阿里云帮助中心
- (*13) Qwen3-TTS
