
はじめに
AIを活用した業務効率化やソフトウェア開発が広がるなか、どのモデルを選ぶかは成果を左右する大きな判断になります。Claude3.7 Sonnetは、即座に回答する力と深く考える力を1つのモデルで両立させた「ハイブリッド推論モデル」として登場しました。
この記事では、Claude3.7 Sonnetの基本的な仕組みからベンチマーク評価、料金体系、具体的な活用法、そして導入時に気をつけたいポイントまでを順に取り上げます。モデル選びの判断材料として、各章の情報を確認してみてください。
Claude 3.7 Sonnetの基本情報と開発背景
Anthropic社とClaudeシリーズの位置づけ
Claude3.7 Sonnetは、Anthropic社が開発した大規模言語モデルです。ChatGPTなどと同じように、人間との対話を通じて質問への回答や文章の生成ができます。特に推論、つまり筋道を立てて考える能力を強化している点が大きな特徴です(参照*1)。
安全性を重視した開発方針が特徴で、Anthropic社はClaudeを「できるだけ誠実で無害」にするよう設計しているとしています。Claudeシリーズは対話型AIとしての基本機能に加え、コーディング支援やエージェント構築といった開発者向けの用途でも活用されています(参照*1)。
自社の業務やプロジェクトでどのモデルが合うかを検討する際は、まずClaude3.7 Sonnetがどんな思想で作られているかを把握しておくと選定がスムーズになります。
ハイブリッド推論モデルの定義と仕組み
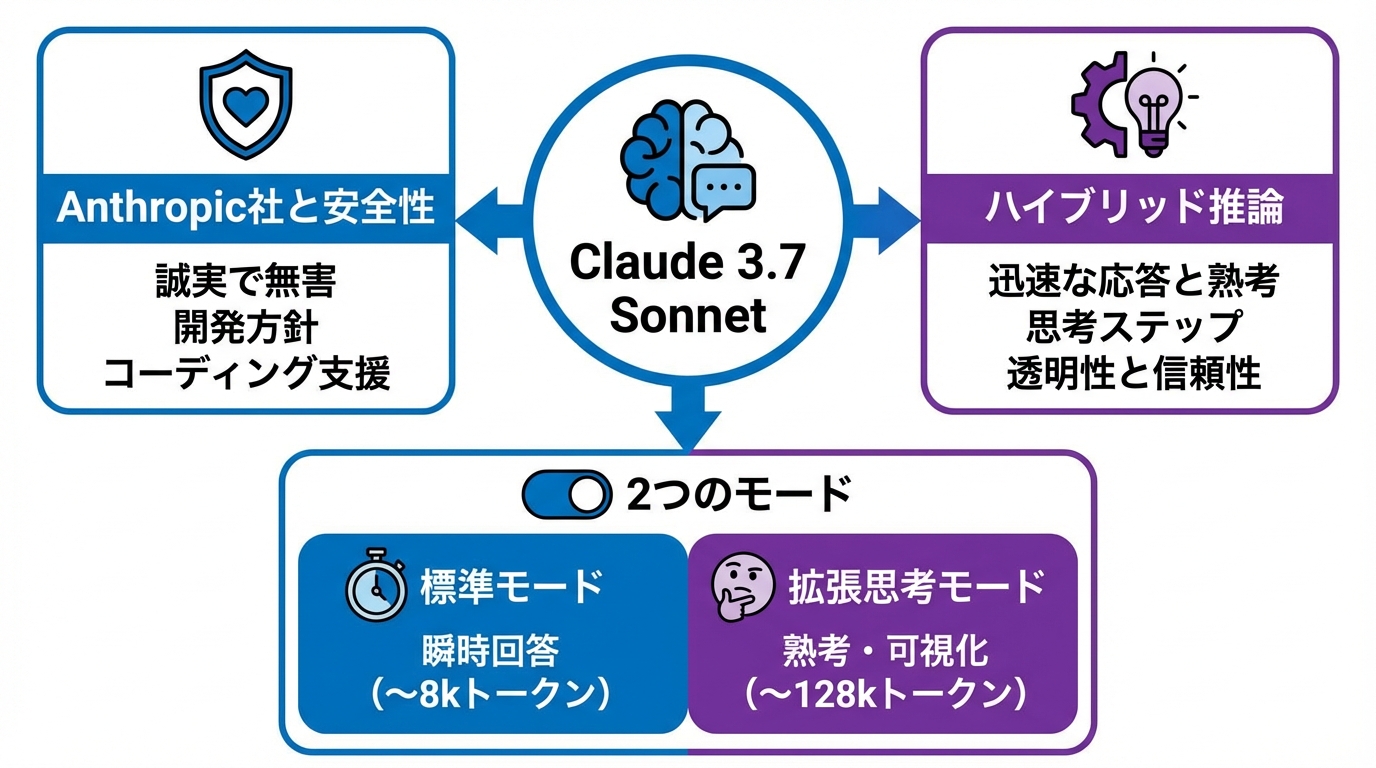
Claude3.7 Sonnetの最大の特徴は、「ハイブリッド推論」を備えた初の大規模言語モデルである点です。通常の大規模言語モデルのようにユーザーの入力に対して即座に回答を返すこともできますが、必要に応じて段階的に「考える」ステップを内部で実行し、より深い推論を行うことができます(参照*2)。
この仕組みにより、迅速な応答と綿密な熟考を単一のモデルで両立しています。透明性と信頼性の高いAIエージェントを構築できる点が、従来モデルにはない利点です(参照*2)。
単純な質問には素早く答え、複雑な課題にはじっくり考えて答えるという切り替えが1つのモデル内で起きる仕組みだと理解しておくと、後述するモード選択の話がつかみやすくなります。
標準モードとExtended Thinking(拡張思考)モードの違い
Claude3.7 Sonnetには、瞬時に回答する標準モードと、時間をかけてじっくり推論する拡張思考(Extended Thinking)モードの2つが用意されています(参照*1)。拡張思考モードでは、モデルの思考手順をユーザーに明らかにする機能が備わっており、推論過程の可視化が可能です。
出力トークンの上限もモードによって異なります。Thinkingなしの場合は約8,192トークン、Thinkingありの場合は64,000トークン、さらにベータ版機能を有効にすると128,000トークンまで拡張できます(参照*3)。
どちらのモードを使うかで得られる回答の深さや出力量が大きく変わるため、タスクの複雑さに応じてモードを選ぶことが実務上のポイントになります。
Claude 3.7 Sonnetの性能とベンチマーク評価
コーディング領域での実力(SWE-bench・Aider polyglot)
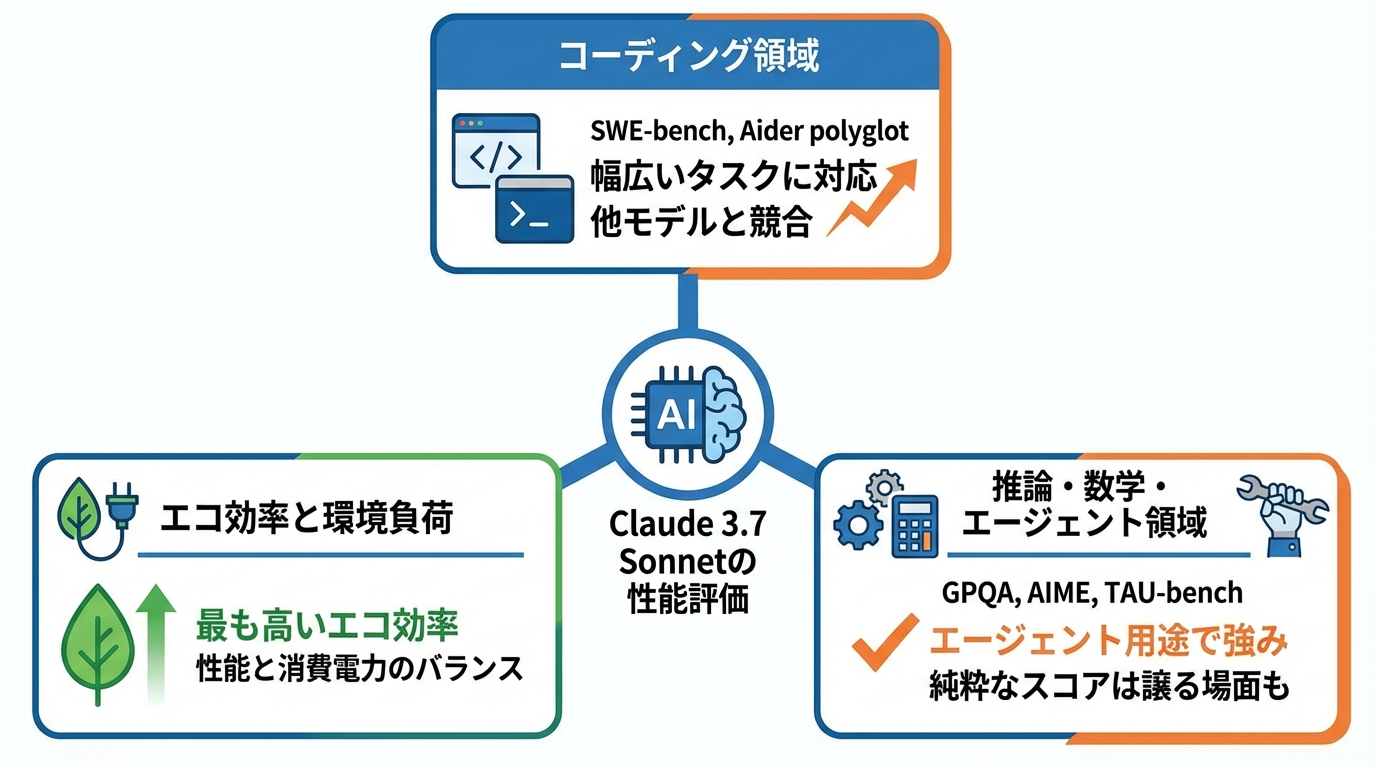
Claude3.7 Sonnetはコーディング分野で高い評価を得ています。SWE-bench Verifiedではスコアが報告されており、実際のコーディング課題を解決する力を示しました。デバッグやコード補完、自動化といった幅広い開発タスクに対応できる点も特徴です(参照*4)。
他モデルとの比較では、SWE-bench Verified(スキャフォールドなし)でo3が69.1%、Gemini 2.5 Proが63.8%、Claude3.7 Sonnetが62.3%という結果になっています。Aider polyglotではo3が81.3%、Gemini 2.5 Proが74.0%、Claude3.7 Sonnetが64.9%です(参照*5)。
コーディングタスクの種類によって各モデルのスコアに差が出るため、自分が取り組む開発内容と近いベンチマーク結果を優先して確認することが有効です。
推論・数学・エージェント領域でのスコア(GPQA・AIME・TAU-bench)
論理的な推論能力を測るベンチマークでは、GPQA diamondでo3が83.3%、Gemini 2.5 Proが84.0%、Claude3.7 Sonnetが78.2%でした。数学分野のAIME 2024ではo3が91.6%、Gemini 2.5 Proが92.0%に対し、Claude3.7 Sonnetは61.3%にとどまっています(参照*5)。
一方で、エージェント的なツール利用能力を測るTAU-benchでは異なる傾向が見られます。TAU-bench(Retail)ではClaude3.7 Sonnetが81.2%、o3が70.4%でした。TAU-bench(Airline)でもClaude3.7 Sonnetが58.4%に対しo3は52.0%と、Claude3.7 Sonnetが上回る結果になっています(参照*5)。
推論や数学の純粋なスコアでは他モデルに譲る場面があるものの、ツールを使って複数の手順をこなすエージェント用途ではClaude3.7 Sonnetが強みを発揮しています。利用目的に応じてどの指標を重視するかを整理してみてください。
エコ効率と環境負荷の観点での評価
AI活用が広がるにつれて、モデルの消費電力や環境負荷にも関心が集まっています。あるエネルギー効率の調査によると、o3やDeepSeek-R1は最もエネルギー消費が大きいモデルとして報告されており、長いプロンプト1回あたり33Wh以上を消費します。これはGPT-4.1 nanoの70倍以上にあたります(参照*6)。
同じ調査において、Claude3.7 Sonnetはエコ効率が最も高いモデルとして評価されました。性能と消費電力のバランスに優れている点は、大量のクエリを処理する業務環境で見逃せない要素です(参照*6)。
コストだけでなくエネルギー効率の観点からもモデルを比較することで、持続的な運用計画を立てやすくなります。
ChatGPT・Geminiとの比較と選び方
機能・コンテキスト長・マルチモーダル対応の比較
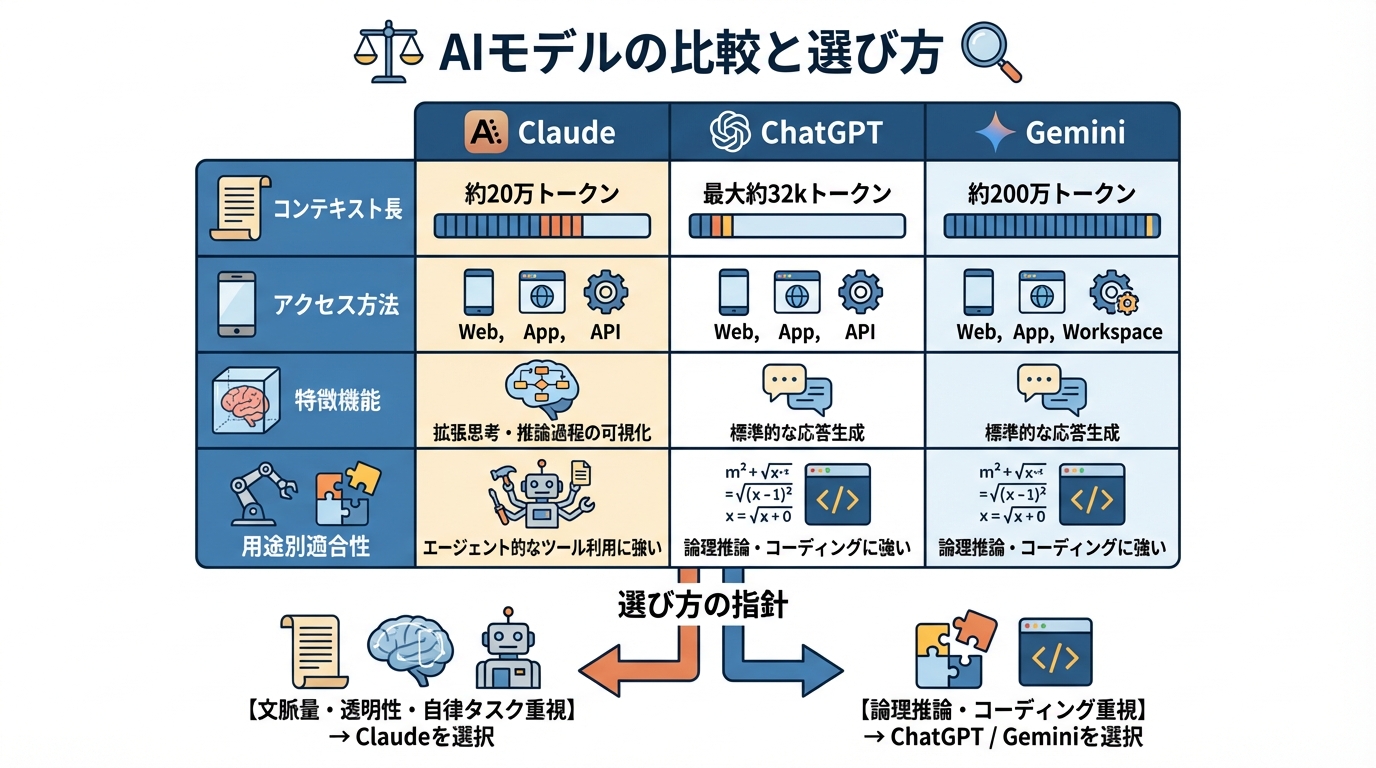
モデルを選ぶうえで、一度に扱える文脈の長さは大きな判断材料です。Claude3.7 Sonnetは約20万トークンのコンテキスト長を保持できます。一方、ChatGPT(GPT-4)は最大で約32kトークン(約3万語)とされており、Google Geminiは約200万トークンの文脈長があると報じられています(参照*1)。
アクセス方法も異なります。Geminiはgemini.google.comやモバイルアプリ、Workspace経由で利用できます。ChatGPTはchatgpt.comやモバイルアプリ、APIで利用可能です。Claudeはclaude.aiやモバイルアプリ、APIからアクセスできます。いずれも制限つきの無料枠が用意されています(参照*7)。
Claude3.7 Sonnetには拡張思考(Extended Thinking)モードによって思考手順をユーザーに開示する機能があり、推論過程の可視化という点で他のモデルとの違いが明確です(参照*1)。利用したいタスクの文脈量や、推論の透明性がどれほど求められるかで比較するのが実用的です。
用途別のモデル選定基準
ベンチマーク結果からは、用途によって適したモデルが変わることが読み取れます。論理的な推論能力は、各種ベンチマークの結果からo3やGemini 2.5 ProがClaude3.7 Sonnetを上回る傾向にあります。コーディングタスクに範囲を広げても、SWE-bench VerifiedとAider polyglotの数値ではo3、Gemini 2.5 Pro、Claude3.7 Sonnetの順です(参照*5)。
しかし、エージェント的なツール利用という観点ではTAU-benchの結果からClaude3.7 Sonnetがo3を上回っています(参照*5)。つまり、複数の手順を組み合わせて自律的にタスクを遂行させたい場面ではClaude3.7 Sonnetが有力な選択肢になります。
数学や論理問題を中心に扱うのか、エージェントとして業務を自動化したいのかによって、重視すべきベンチマーク指標を切り分けて検討してみてください。
料金体系と各プラットフォームでのコスト比較
無料プラン・Pro・Team・Enterpriseプランの概要
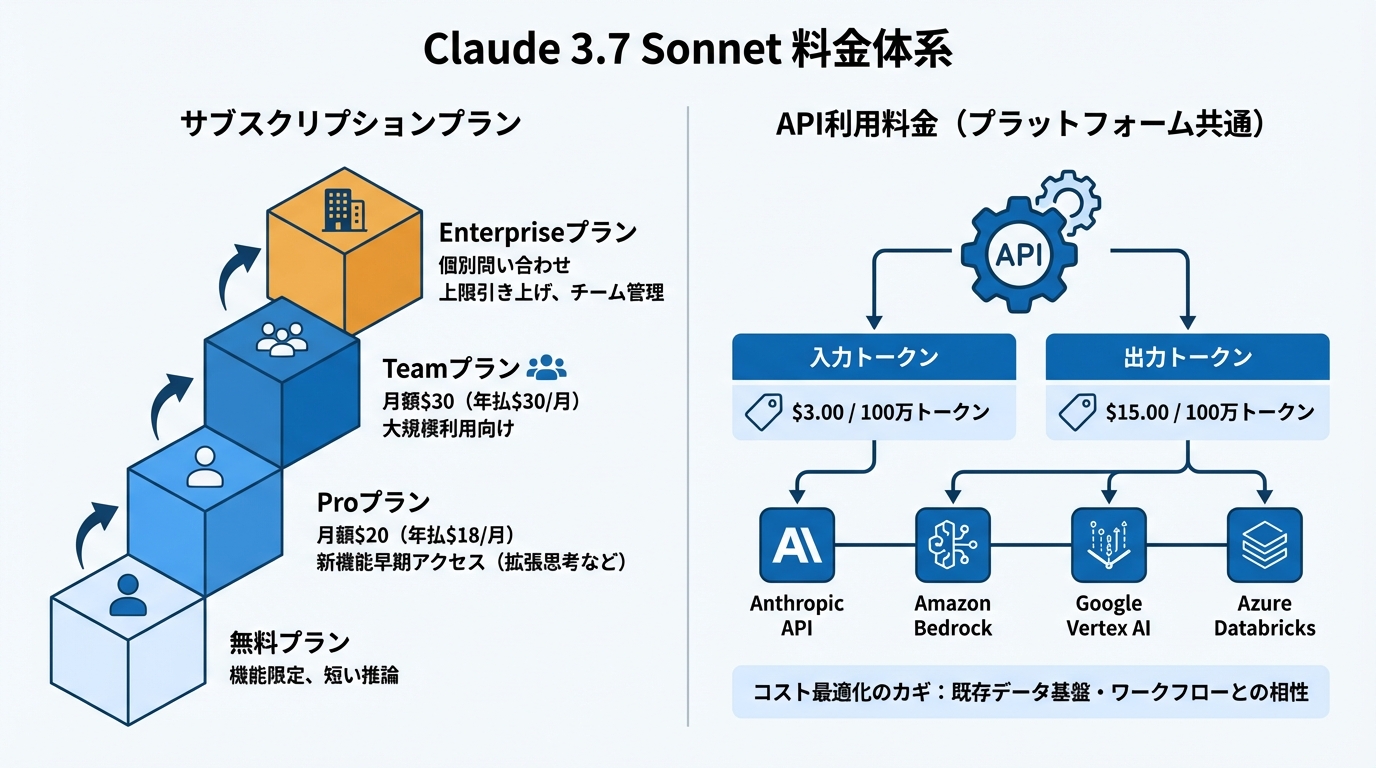
Claude3.7 Sonnetは複数の料金プランで提供されています。無料プランは機能が限定されており、長い推論は利用できません。Pro(有料)プランは月額20ドルで、年払いの場合は月あたり18ドルになります。拡張思考(Extended Thinking)モードなどの新機能に早期アクセスできる点がProプランの利点です(参照*1)。
大規模利用が必要な場合は、Teamプランが月額30ドル(年払いでも月あたり30ドル)で用意されています。Enterpriseプランは個別の問い合わせが必要で、上限の引き上げやチーム管理機能が含まれます(参照*1)。
個人利用であれば無料プランかProプランの範囲で試し、チームでの導入を検討する段階でTeamプラン以上の機能差を確認するという進め方が合理的です。
API利用料金とプラットフォーム別の料金比較
API経由でClaude3.7 Sonnetを利用する場合の料金は、主要なプラットフォーム間で統一されています。入力トークンの単価は100万トークンあたり3.00ドル、出力トークンの単価は100万トークンあたり15.00ドルです。この価格はAnthropic API、Amazon Bedrock、Google Vertex AI、Databricksのいずれでも同じです(参照*2)。
プラットフォームごとの特徴として、Microsoft Azure環境でClaude3.7 Sonnetを利用する場合はAzure Databricksが唯一の選択肢となっています(参照*2)。
トークン単価が同一であるため、料金だけでなく、既存のデータ基盤やワークフローとの相性でプラットフォームを選ぶことがコスト最適化のカギになります。
活用法と関連ツールとの連携
コーディング支援(Cursor・Cline・GitHub Copilot)
Claude3.7 Sonnetは複数のコーディング支援ツールと連携して利用されています。Cursorはソフトウェア開発者向けのAIコーディング支援ツール(コードエディタ環境)で、実際の開発タスクにClaudeを用いたところ「Claudeが再びトップ性能を示した」という評価がされています(参照*1)。
Clineはオープンソースのコーディングエージェントで、Visual Studio Codeなどの統合開発環境上で動作します。Claude3.7 Sonnetをエージェントとして活用し、コマンドライン操作やブラウザ操作の自動化など、多段階のタスクを自律的にこなせる点が特徴です(参照*1)。
普段使っている開発環境に合わせてツールを選び、Claude3.7 Sonnetの推論能力をコーディング作業に組み込むことで、デバッグやコード生成の効率を高められます。
クラウド・エンタープライズ連携(AWS Bedrock・Databricks)
Claude3.7 SonnetはAmazon Bedrockを通じて利用でき、東京・大阪リージョンを含むAPACの推論プロファイルでも提供されています。推論プロファイルIDはapac.anthropic.claude-3-7-sonnet-20250219-v1:0です(参照*8)。
Amazon Bedrockではプロンプトキャッシュ機能も一般提供されています。Claude3.7 Sonnetを含む対応モデルで、頻繁に使われるプロンプトをキャッシュすることで応答時間を最大85%短縮し、コストを最大90%削減できます(参照*9)。
Databricksでも、Claudeの高度な推論やエージェント機能に直接アクセスできるようになっています。Databricks Data Intelligence Platformと組み合わせることで、自社固有のデータ上にドメイン特化型AIエージェントを構築し、データとAIのライフサイクル全体を通じたガバナンスを実現できます(参照*10)。
業務活用の具体例(議事録・チャットボット・文書要約)
Claude3.7 Sonnetの活用は開発領域にとどまりません。AI議事録サービスでは、Claude Sonnet 4.6への対応により長時間かつ複雑な議題の会議でも、より精度の高い要約や議事録生成が可能になっています(参照*11)。
Claude3.7 Sonnetの拡張思考(Extended Thinking)モードを用いれば、思考手順が開示されるため、チャットボットの回答根拠を利用者が確認する場面にも適しています(参照*1)。約20万トークンのコンテキスト長を活かすことで、長い文書の要約や複数資料の横断的な読み込みにも対応しやすくなります。
議事録作成、問い合わせ対応、社内文書の要約など、自社の業務フローのどこにClaude3.7 Sonnetを組み込めるかを洗い出してみてください。
導入時の注意点と制限事項
ハルシネーションと安全性への配慮
Claude3.7 Sonnetは高性能ですが、他のAIモデルと同様に完璧ではありません。いわゆるハルシネーション(事実と異なる情報の生成)を起こす可能性があり、学習データに由来するバイアスも完全には排除できていません(参照*1)。
著作権に関連する調査では、Claude3.7 Sonnetが対象となった書籍の94%以上の内容を再現したケースが4件確認されています。そのうち2冊は著作権保護の対象で、残り2冊はパブリックドメインでした(参照*12)。
業務で利用する際は、AIの出力を最終成果物としてそのまま使うのではなく、必ず人間が内容を確認する運用フローを設けることが欠かせません。
無料版・有料版の機能制限とトークン上限
無料プランでは機能が限定されており、拡張思考(Extended Thinking)モードによる長い推論は利用できません(参照*4)。出力トークンの上限も、Thinkingなしで約8,192トークン、Thinkingありで64,000トークン、ベータ版機能を有効にした場合は128,000トークンと段階的に異なります(参照*3)。
Thinkingの予算(budget_tokens)を32,000トークン以上に設定する場合は、ネットワークの問題を避けるためにバッチ処理による非同期呼び出しが推奨されています(参照*3)。
自分が必要とする出力量や推論の深さに合わせて、プランとモードの組み合わせを事前に確認しておくと、利用中に想定外の制限にぶつかるリスクを減らせます。
おわりに
Claude3.7 Sonnetは、標準モードと拡張思考(Extended Thinking)モードを切り替えられるハイブリッド推論モデルとして、コーディング支援からエージェント構築、議事録作成まで幅広い業務に対応できるモデルです。エコ効率の高さやTAU-benchでの強みなど、他モデルとは異なる特性を持っています。
料金プランやプラットフォームの選択肢、トークン上限といった制約条件を整理したうえで、自社の業務フローに合った使い方を検討してみてください。
監修者
安達裕哉(あだち ゆうや)
デロイト トーマツ コンサルティングにて品質マネジメント、人事などの分野でコンサルティングに従事しその後、監査法人トーマツの中小企業向けコンサルティング部門の立ち上げに参画。大阪支社長、東京支社長を歴任したのち2013年5月にwebマーケティング、コンテンツ制作を行う「ティネクト株式会社」を設立。ビジネスメディア「Books&Apps」を運営。
2023年7月に生成AIコンサルティング、およびAIメディア運営を行う「ワークワンダース株式会社」を設立。ICJ2号ファンドによる調達を実施(1.3億円)。
著書「頭のいい人が話す前に考えていること」 が、82万部(2025年3月時点)を売り上げる。
(“2023年・2024年上半期に日本で一番売れたビジネス書”(トーハン調べ/日販調べ))
参照
- (*1) ビッグデータラボ – Claude 3.7 sonnet とは?無料でできること、料金、制限、作れるアプリなどを解説!
- (*2) Qiita – Databricks環境でのClaude 3.7 Sonnet実践ガイド #claude3.7sonnet
- (*3) Zenn – Cline × Claude3.7のBudgetの上限が”6553”な理由
- (*4) Blockchain Council – How to Use Claude AI for Coding? | Blockchain Council
- (*5) Algomatic Tech Blog – OpenAI o3, Claude 3.7 Sonnet , Gemini 2.5 Proの評価と解釈[2025年4月版]
- (*6) How Hungry is AI? Benchmarking Energy, Water, and Carbon Footprint of LLM Inference
- (*7) Google Gemini & NotebookLM
- (*8) クラスメソッド発「やってみた」系技術メディア | DevelopersIO – [アップデート] Anthropic Claude 3.7 Sonnet が東京、大阪リージョンを含む、 APAC の推論プロファイルで利用可能になりました
- (*9) Amazon Web Services – Amazon Bedrock でプロンプトキャッシュを効果的に活用する方法 | Amazon Web Services
- (*10) Databricks – Announcing Anthropic Claude 3.7 Sonnet is natively available in Databricks
- (*11) プレスリリース・ニュースリリース配信シェアNo.1|PR TIMES – AI議事録サービス「Rimo Voice」、本日リリースの最新モデル「Claude Sonnet 4.6」に対応
- (*12) Extracting books from production language models
