
はじめに
音声でAIと対話する場面が広がるなか、応答の速さや会話の自然さがこれまで以上に求められています。もし音声AIの応答が遅かったり、騒がしい環境で指示を聞き取れなかったりすれば、実用的な場面では使いものになりません。Gemini 3.1 Flash Liveは、低い遅延と音声から音声へ直接やり取りする設計によって、こうした課題に対応するモデルです。
本記事では、Gemini 3.1 Flash Liveの技術的な特徴やベンチマーク上の数値、開発者向けの実装方法、料金体系、活用事例、そして導入時に把握しておくべき制約までを順を追って説明します。
Gemini 3.1 Flash Liveの概要
リアルタイム音声対話モデルの定義
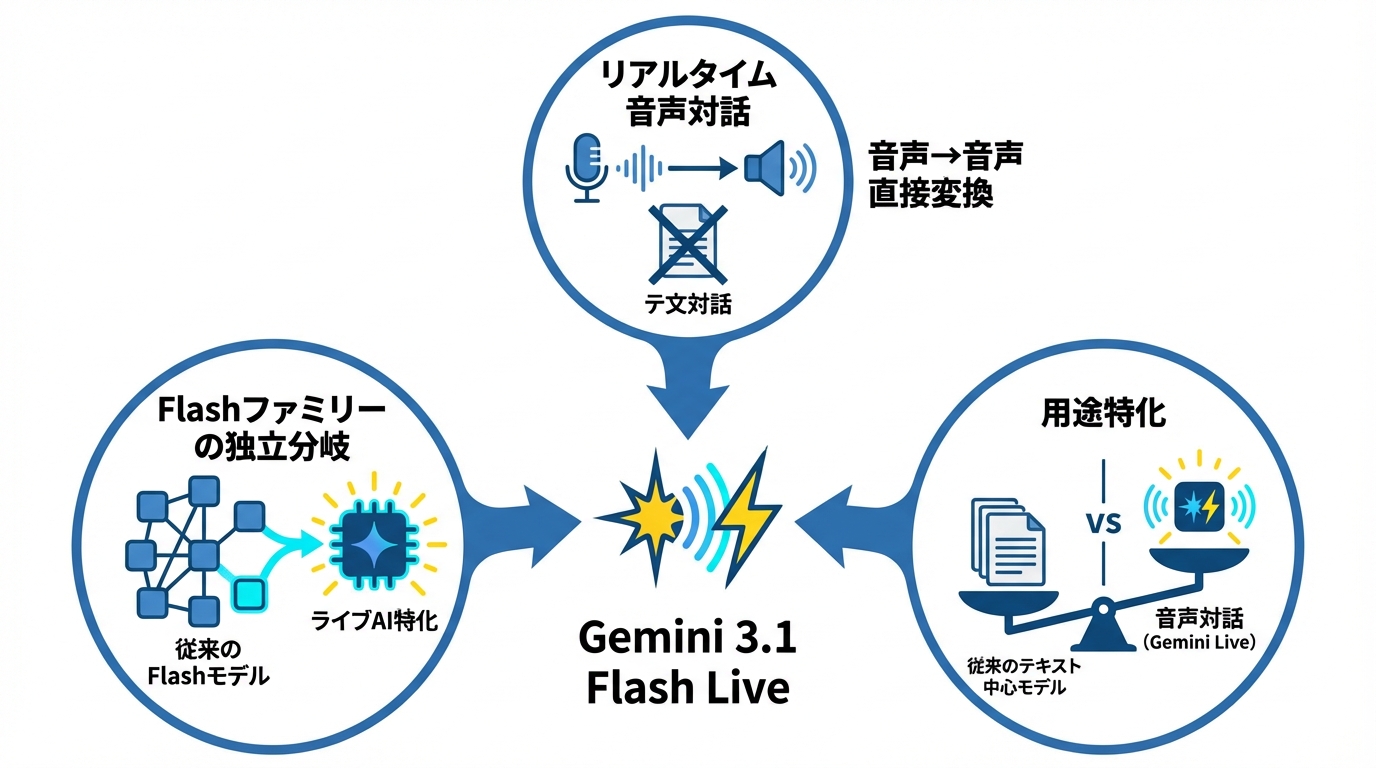
Gemini 3.1 Flash Liveは、低遅延の音声から音声へのやり取りに特化したモデルです。リアルタイムの対話や音声を軸としたAI活用に向けて最適化されており、音の微妙なニュアンスの検出、数値の正確な読み上げ、複数の入力形式への対応といった機能を備えています(参照*1)。
品質がもっとも高い音声モデルとして位置づけられており、次世代の音声ファーストAIに必要な速度と自然な会話のリズムを実現すると説明されています(参照*2)。
つまりGemini 3.1 Flash Liveは、テキストを介さずに音声だけで完結するやり取りを前提に設計されたモデルです。音声入力をそのまま音声出力へ変換する仕組みにより、従来の「音声をテキストに変換してから処理する」方式とは異なるアプローチをとっています。こうした設計を踏まえたうえで、Flash ファミリー内での位置づけを確認することがポイントです。
Flash ファミリー内での位置づけ
Gemini 3.1 Flash Liveは、Flashファミリーのなかでも独立した製品レベルの分岐として扱う必要があります。ライブ音声のやり取りやリアルタイムの会話行動をモデルファミリーの中心的な特性として位置づけた点が、従来のFlashモデルとの違いです(参照*3)。
その背景には、ライブAIの振る舞いを既存のモデル群への追加機能ではなく、製品の中核品質として扱うという方針の転換があります。つまり、音声対話の品質そのものが製品の評価軸になったということです(参照*3)。
Flashファミリー全体の中でGemini 3.1 Flash Liveがどの役割を担うのかを把握しておくと、用途に応じたモデル選択がしやすくなります。テキスト処理が中心であれば従来のFlashモデル、リアルタイム音声対話が中心であればGemini 3.1 Flash Liveという切り分けが基本です。
登場の背景と課題
音声AI に求められる低レイテンシ
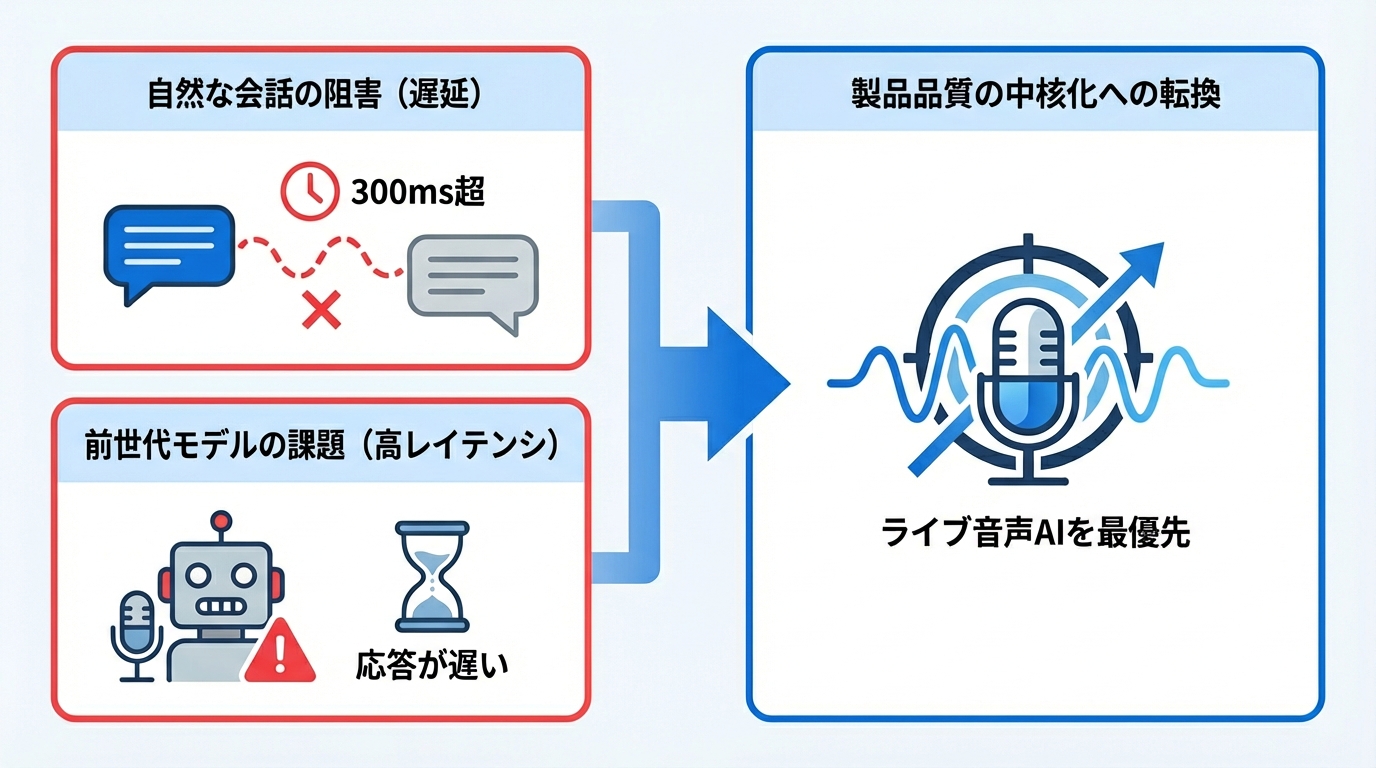
音声AIでは、遅延の長さが会話の自然さを左右します。入力から出力までのあいだに必ず遅延が発生し、この遅延が長いほど会話は不自然になり、利用者にとって追いかけにくいやり取りになります。研究者のあいだでは、音声を自然に知覚できる遅延の上限はおよそ300ミリ秒とされています(参照*4)。
ただし、Gemini 3.1 Flash Liveについて具体的な遅延時間は公表されていません(参照*4)。数値が非公開である以上、実際の利用環境で応答速度を検証することが欠かせません。音声AIの導入を検討する際は、自社のネットワーク環境や想定する利用場面に合わせて遅延を計測し、許容範囲に収まるかどうかを確かめる必要があります。
前世代モデルの限界
前世代のGemini Live APIでは、遅延に関する課題が利用者から報告されていました。音声入力の処理やモデルの応答が著しく遅くなり、リアルタイム体験が損なわれるという事例です。この問題は最新モデルだけでなく一部の旧モデルでも発生しており、以前はスムーズに動いていた環境でも起きていたとの報告があります(参照*5)。
こうした遅延の問題は、ライブ音声AIの行動品質を中核的な製品品質として扱う方針への転換を後押ししました。ライブAIの振る舞いを既存モデルへの追加機能ではなく、製品の中心に据えるという考え方です(参照*3)。前世代で発生した課題を把握しておくと、Gemini 3.1 Flash Liveへの移行時にどの点を重点的に検証すべきかが明確になります。
主要な技術的特徴
音声-音声設計と低レイテンシ対話
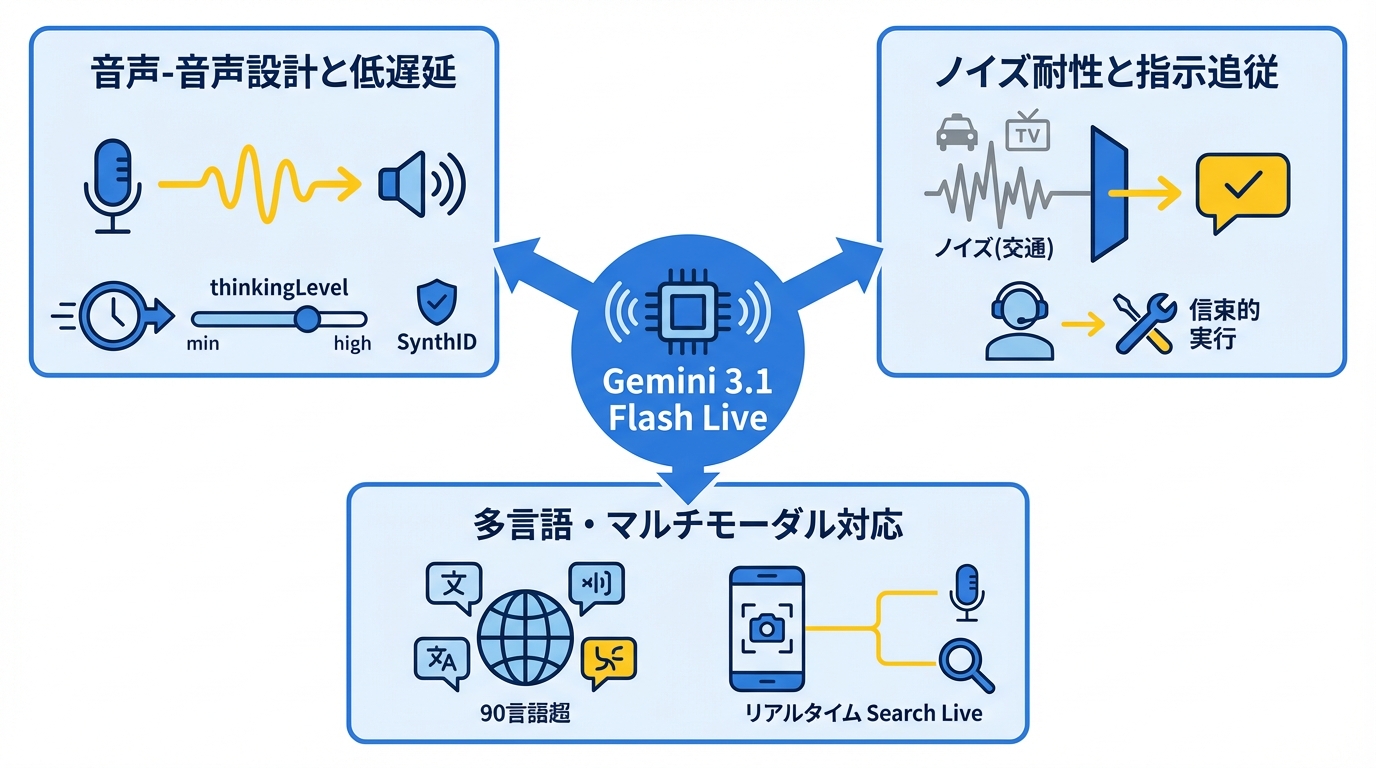
Gemini 3.1 Flash Liveの中心的な特徴は、音声を入力としてそのまま音声を出力する設計にあります。前世代と比較して、会話の継続時間が2倍に伸びています(参照*6)。
また、思考の深さを制御するための仕組みとして、thinkingLevelというパラメータが用意されています。設定はminimal、low、medium、highの4段階で、初期値はminimalです。この初期値は遅延をもっとも小さくするために最適化されています。なお、前世代のGemini 2.5モデルではthinkingBudgetという別のパラメータで思考トークン数を指定する方式でした(参照*7)。
生成された音声にはすべてSynthIDというラベルが付与されます(参照*6)。SynthIDはAIが生成した音声であることを識別するための仕組みです。遅延の制御と生成物の透明性を両立させている点が、このモデルの設計上の特徴です。
ノイズ耐性と指示追従の向上
騒がしい実環境でのタスク完了率が向上しています。ライブ会話中に外部ツールを呼び出して情報を返す能力が改善され、交通音やテレビの音といった環境音から発話を正しく区別できるようになりました。背景のノイズをより効果的にフィルタリングし、指示に対して安定して応答します(参照*8)。
前世代と比べると、複雑なシステム指示への追従精度が上がり、会話中の外部ツール呼び出しの信頼性も高くなっています(参照*6)。騒がしい環境で音声AIを利用する場面が想定される場合、ノイズ環境下での動作を事前にテストしておくことが有効です。
90言語超のマルチリンガル対応
Gemini 3.1 Flash Liveは、より自然で直感的な会話を実現するモデルとして位置づけられており、Google検索のSearch Live機能のグローバル展開を支えています(参照*9)。Search Liveは2025年7月にアメリカとインドで初めて提供が始まった機能で、スマートフォンのカメラで対象を映しながらリアルタイムで会話する仕組みです。今回、この機能が世界規模に広がりました(参照*9)。
モデルの公式ドキュメントには、低遅延の音声対話に加えてマルチモーダルな認識能力を備えることが明記されています(参照*1)。グローバル展開をすでに果たしている点から、多言語で音声対話を行いたい場面での候補として検討する価値があります。利用予定の言語で実際に動作を確認しておくことを推奨します。
ベンチマークと性能評価
ComplexFuncBench Audioのスコア
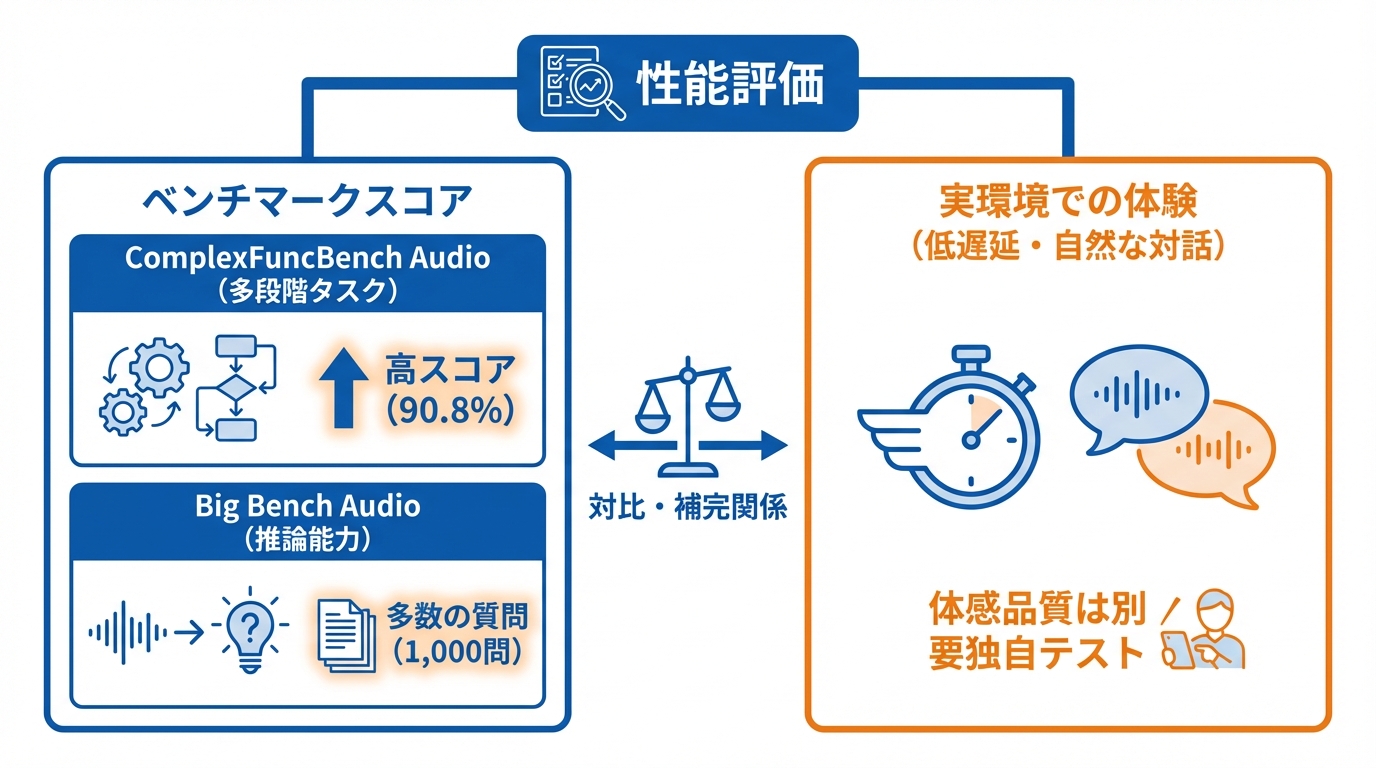
ComplexFuncBench Audioは、さまざまな制約を伴う複数ステップの関数呼び出し能力を測るベンチマークです。Gemini 3.1 Flash Liveはこのベンチマークで90.8%のスコアを記録し、前世代モデルを上回りました(参照*2)。
この結果について、複雑で多段階のタスクへの対応力が向上したことを示す大きな改善だと評価されています(参照*4)。音声エージェントに外部サービスとの連携を行わせる用途では、このスコアがひとつの判断材料になります。
Big Bench Audioほか公開指標
Big Bench Audioは、1,000問の音声質問を使って推論能力を測定するテストです。Gemini 3.1 Flash Liveはこのテストでも最高スコアを記録しています(参照*4)。
一方で、Gemini 3.1 Flash Liveの性能を語るうえではベンチマークだけでは十分でないとの指摘もあります。低遅延や音声間の直接対話、会話が遅く感じたり断片的になったりしないことが実際の評価軸であるという見方です(参照*3)。ベンチマークの数値と実環境での体験は必ずしも一致しないため、自社の利用シナリオに沿ったテストを並行して行うことが望ましいです。
開発者向け実装のポイント
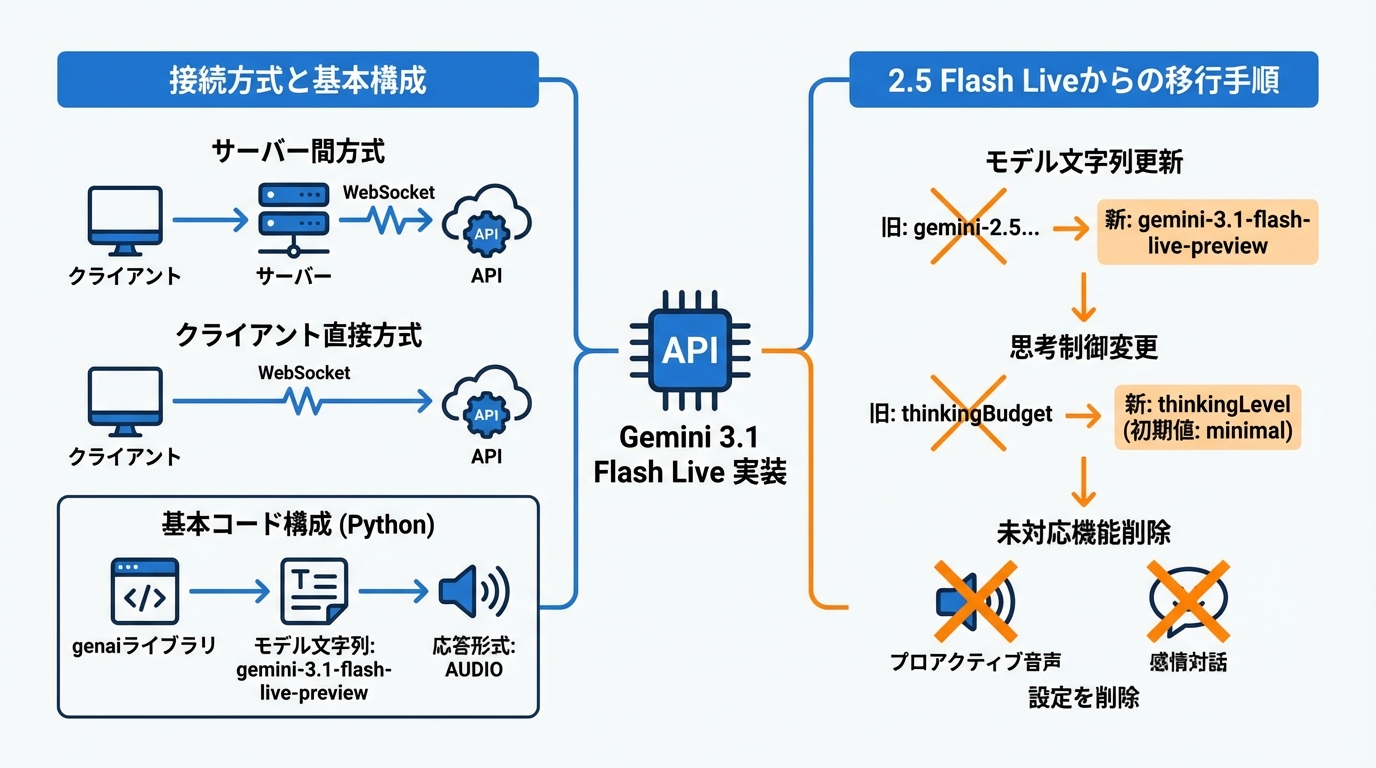
Live APIの接続とコード例
Gemini 3.1 Flash LiveにはLive APIを通じてWebSocket経由で接続します。接続の構成は2種類あります。ひとつはバックエンドがLive APIに接続するサーバー間方式で、クライアントが音声やテキストなどのデータをバックエンドに送り、バックエンドがAPIへ転送します。もうひとつはクライアントが直接Live APIへWebSocketで接続する方式で、バックエンドを経由しません(参照*10)。
接続のコード例はPythonで公開されています。genaiライブラリを使い、モデル文字列として「gemini-3.1-flash-live-preview」を指定し、応答形式を「AUDIO」に設定するのが基本的な構成です(参照*7)。自社のアーキテクチャに合わせて、サーバー間方式かクライアント直接方式かを選定し、まずは最小構成で接続を確認する手順を踏むとスムーズです。
2.5 Flash Liveからの移行手順
前世代のGemini 2.5 Flash Liveから移行する場合、変更すべき箇所は主に2つあります。まず、モデル文字列を「gemini-2.5-flash-native-audio-preview-12-2025」から「gemini-3.1-flash-live-preview」に更新します。次に、思考制御の設定をthinkingBudgetからthinkingLevelに変更します。thinkingLevelの初期値はminimalで、遅延を最小化するよう最適化されています(参照*1)。
移行にあたっては、前世代で使っていたプロアクティブ音声や感情対話の設定がGemini 3.1 Flash Liveでは未対応であるため、コードからこれらの設定を削除する必要があります(参照*1)。移行の際にはモデル文字列の更新、思考制御パラメータの切り替え、未対応機能の設定削除という3点を順番に確認すると、切り替え時のエラーを防ぎやすくなります。
料金体系と他モデルとの比較
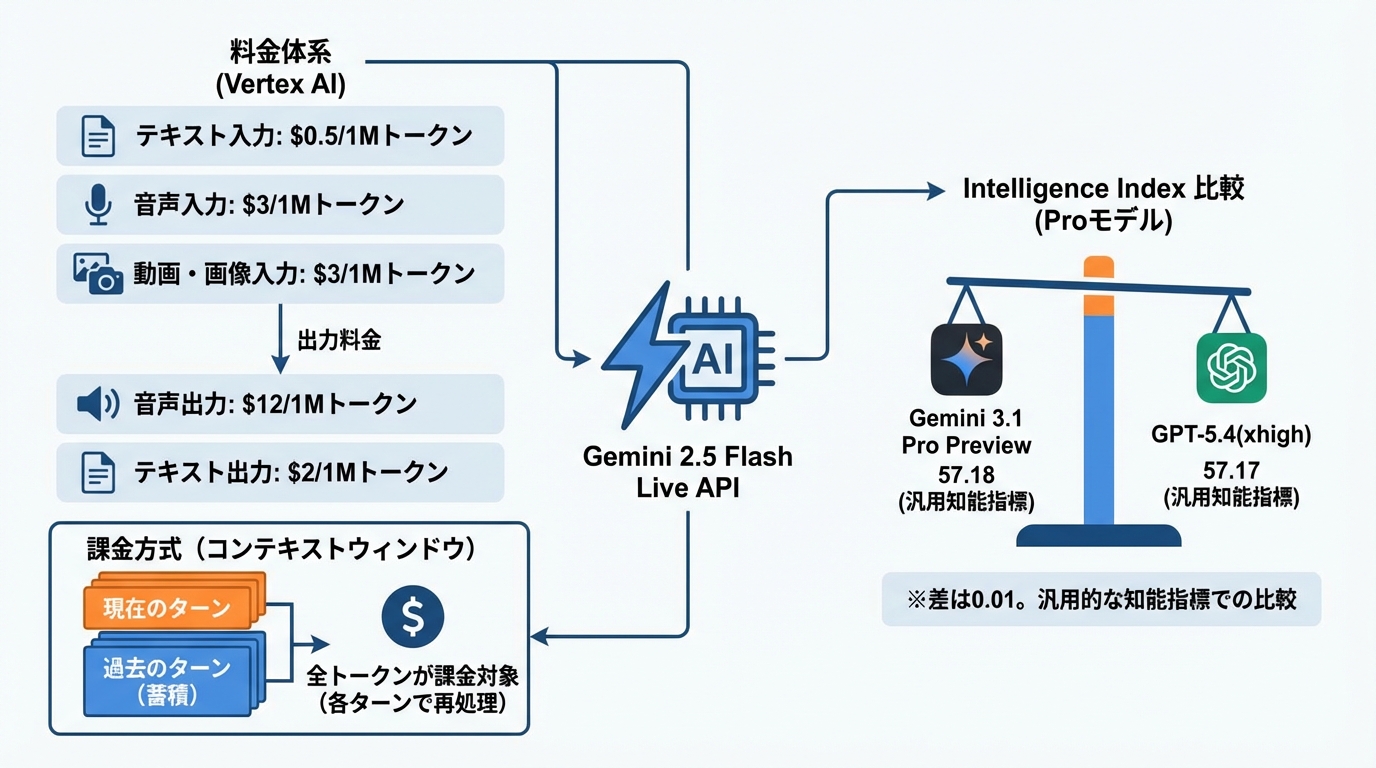
Vertex AI上の価格構造
Vertex AI上でのGemini 2.5 Flash Live APIの価格は、入力テキストトークン100万あたり0.5ドル、入力音声トークン100万あたり3ドル、入力動画および画像トークン100万あたり3ドルです。出力側はテキストトークン100万あたり2ドル、音声トークン100万あたり12ドルとなっています(参照*11)。
課金方式で押さえておくべき点は、Live APIセッションのコンテキストウィンドウに関する仕組みです。各ターンごとに、セッションのコンテキストウィンドウ内にあるすべてのトークンに対して課金されます。コンテキストウィンドウには、現在のターンの新規トークンに加え、過去のターンで蓄積されたトークンがすべて含まれます。過去のターンのトークンは、設定したコンテキストウィンドウの上限まで各ターンで再処理され、その分も課金対象です(参照*11)。会話が長くなるほど1ターンあたりの課金額が増える構造であるため、コスト試算の際にはセッション全体のトークン量を見積もることが欠かせません。
2.5 Flash Live・競合モデルとの比較
Gemini 3.1 Flash Liveの前世代にあたるGemini 2.5 Flash Liveとの比較では、会話の継続時間が2倍に伸び、ノイズ耐性や指示追従、外部ツール呼び出しの信頼性がそれぞれ向上しています(参照*6)。
競合との比較として、Intelligence Indexという指標ではGemini 3.1 Pro Previewが57.18、GPT-5.4(xhigh)が57.17というスコアで、差は0.01にとどまっています(参照*12)。ただし、この比較はFlash LiveではなくProモデルに関する数値です。モデル選択の際は、音声対話の遅延と品質を重視するのか、汎用的な知能指標を重視するのかで判断の軸が異なります。
ユースケースと活用事例
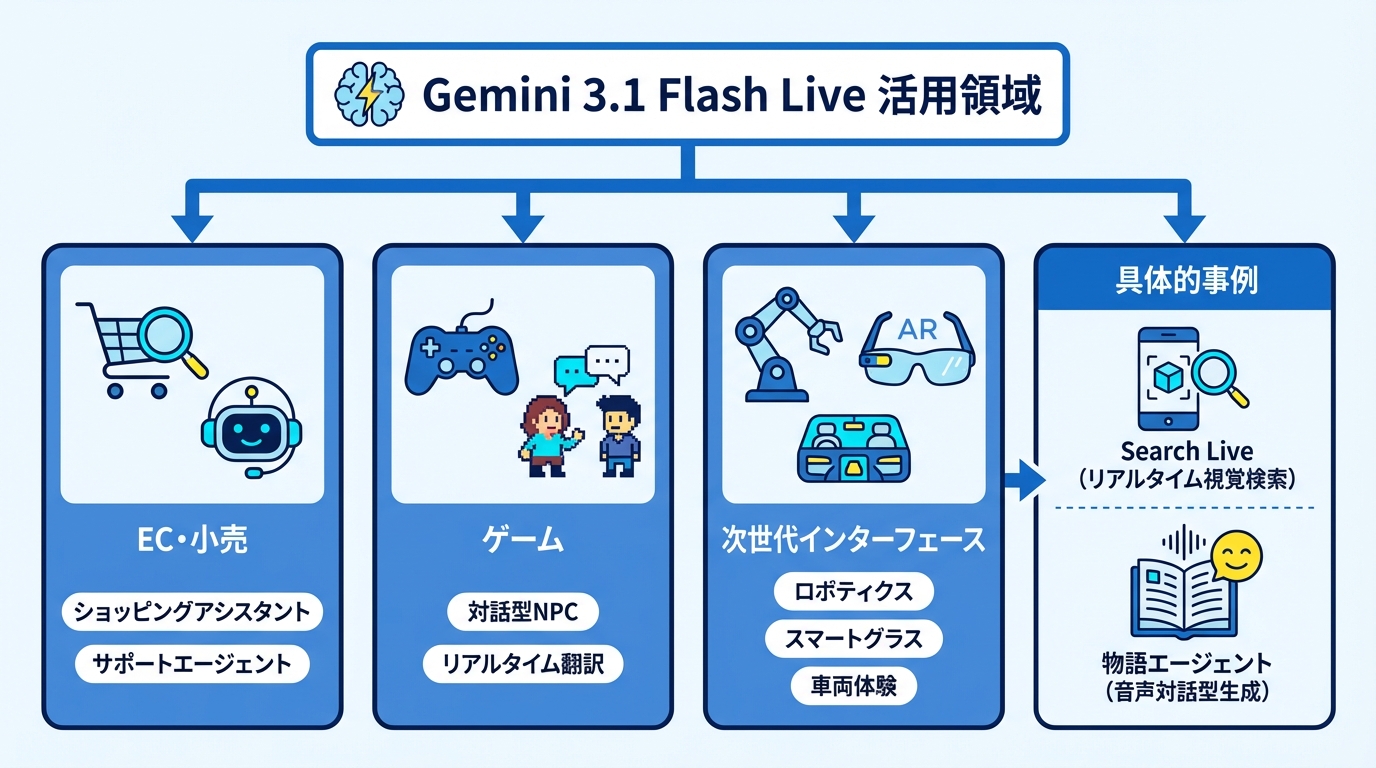
Gemini 3.1 Flash Liveの活用領域として、公式ドキュメントではいくつかの分野が例示されています。EC・小売分野では、個人に合わせた商品提案を行うショッピングアシスタントや、顧客の問題を解決するサポートエージェントが挙げられています。ゲーム分野では、対話型のノンプレイヤーキャラクター、ゲーム内ヘルプ、リアルタイムのゲーム内コンテンツ翻訳といった用途があります。さらに次世代インターフェースとして、ロボティクス、スマートグラス、車両における音声・映像対応の体験が想定されています(参照*10)。
具体的な事例としては、Search Liveがあります。スマートフォンのカメラで物体を映しながらリアルタイムで音声による対話を行い、視覚的な文脈をもとに質問に答える機能です。2025年7月にアメリカとインドで提供が始まり、Gemini 3.1 Flash Liveによってグローバルに展開されました(参照*9)。
開発者コミュニティからも活用例が生まれています。Tales of Wonderは、AIを活用した物語エージェントで、音声による自然なやり取りだけで、利用者の名前・年齢・物語のテーマを聞き取り、個人に合わせた年齢適応型の物語を生成します。入力は完全に会話ベースで、タイピングは不要です。Gemini Live APIが自然言語の理解を担っています(参照*13)。自社のサービスにどの領域が当てはまるかを照合し、まずは小規模な検証から始めると導入の判断がしやすくなります。
導入時の注意点と制約
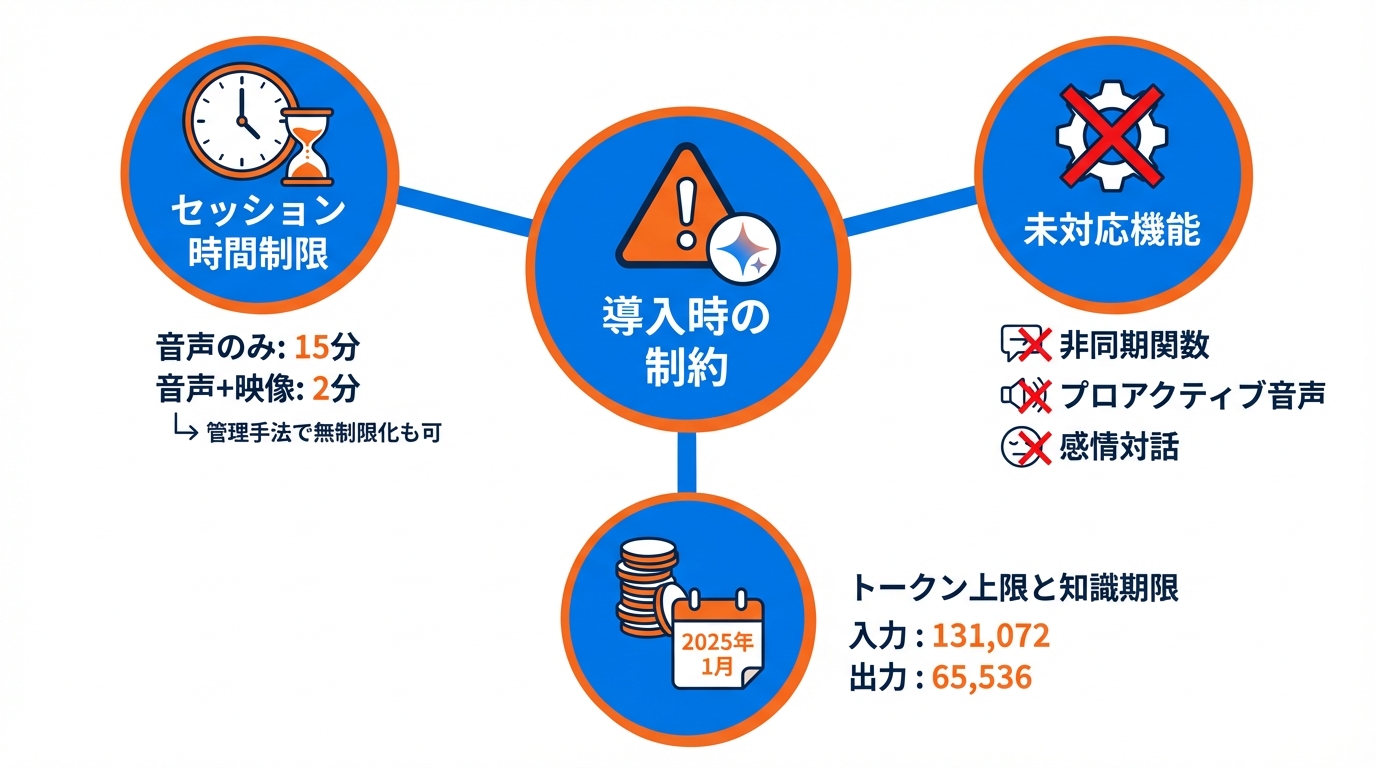
Gemini 3.1 Flash Liveを導入する際には、セッション時間の制限に注意が必要です。音声のみのセッションは15分、音声と映像を組み合わせたセッションは2分が上限です。ただし、セッション管理の手法を設定することで、セッション時間を無制限に延長できる仕組みも用意されています(参照*7)。
機能面では、非同期の関数呼び出しがまだ対応していません。関数呼び出しは同期処理のみで、ツールの応答を送信するまでモデルは返答を開始しません。また、プロアクティブ音声と感情対話の機能もGemini 3.1 Flash Liveでは未対応のため、これらの設定をコードから削除する必要があります(参照*1)。
入出力のトークン上限も把握しておくべきです。入力トークンの上限は131,072トークン、出力トークンの上限は65,536トークンです。知識のカットオフ日は2025年1月となっています(参照*1)。これらの制約を事前に確認し、想定するユースケースの要件と照らし合わせておくことが導入前の重要な手順です。
おわりに
Gemini 3.1 Flash Liveは、音声から音声への低遅延設計、騒音下でのノイズ耐性向上、ComplexFuncBench Audioでの90.8%というスコア、そしてグローバル展開を支える多言語対応など、音声ファーストのAI活用において複数の進展をもたらしたモデルです。
一方で、非同期関数呼び出しの未対応やセッション時間の制限、ターンごとに蓄積トークンが再課金される料金構造といった制約も存在します。導入を検討する場合は、ベンチマーク数値だけでなく、自社の利用環境に合わせた実地テストを行ったうえで判断することがポイントです。
監修者
安達裕哉(あだち ゆうや)
デロイト トーマツ コンサルティングにて品質マネジメント、人事などの分野でコンサルティングに従事しその後、監査法人トーマツの中小企業向けコンサルティング部門の立ち上げに参画。大阪支社長、東京支社長を歴任したのち2013年5月にwebマーケティング、コンテンツ制作を行う「ティネクト株式会社」を設立。ビジネスメディア「Books&Apps」を運営。
2023年7月に生成AIコンサルティング、およびAIメディア運営を行う「ワークワンダース株式会社」を設立。ICJ2号ファンドによる調達を実施(1.3億円)。
著書「頭のいい人が話す前に考えていること」 が、82万部(2025年3月時点)を売り上げる。
(“2023年・2024年上半期に日本で一番売れたビジネス書”(トーハン調べ/日販調べ))
参照
- (*1) Google AI for Developers – Gemini 3.1 Flash Live Preview
- (*2) Google – Gemini 3.1 Flash Live: Making audio AI more natural and reliable
- (*3) Data Studios ‧Exafin – Gemini 3.1 Flash Live: Complete Guide to Features, Performance, Capabilities, and Google integration
- (*4) Ars Technica – The debut of Gemini 3.1 Flash Live could make it harder to know if you’re talking to a robot
- (*5) Google AI Developers Forum – Gemini Live API models high Latency
- (*6) Grok banned in the Netherlands, Gemini 3.1 Flash Live, native Codex plugins
- (*7) Google AI for Developers – Live API capabilities guide
- (*8) Google – Build real-time conversational agents with Gemini 3.1 Flash Live
- (*9) TechCrunch – Google is launching Search Live globally
- (*10) Google AI for Developers – Gemini Live API overview
- (*11) Google Cloud – Vertex AI Pricing
- (*12) What LLM – New LLMs March 2026: GPT-5.4 Tied for #1. Nobody Talked About It.
- (*13) Devpost – Tales of Wonder
