はじめに
Runwayは動画生成AIの分野で広く知られてきましたが、現在は「World Models」と呼ばれる新たな技術領域へ本格的に舵を切っています。単に映像を作るだけでなく、物理法則や空間の連続性を理解し、現実世界をシミュレーションできるAIへの転換です。私がこの動きに注目しているのは、ロボティクスやゲーム、自動運転といった産業でのAI活用を語るうえで、避けて通れない変化だからです。「動画生成AI」という文脈だけで捉えていると、World Modelsが持つ産業的なインパクトを見誤ります。
RunwayのWorld Modelsは、動画データを学習の土台としながら物理世界を仮想的に再現する技術であり、ロボットの動作検証や仮想空間の構築といった幅広い応用が進んでいます。本文では、その定義・技術的特徴・競合との違い・応用事例・課題を順に解説します。
World Modelsの定義と背景
World Modelsの基本概念
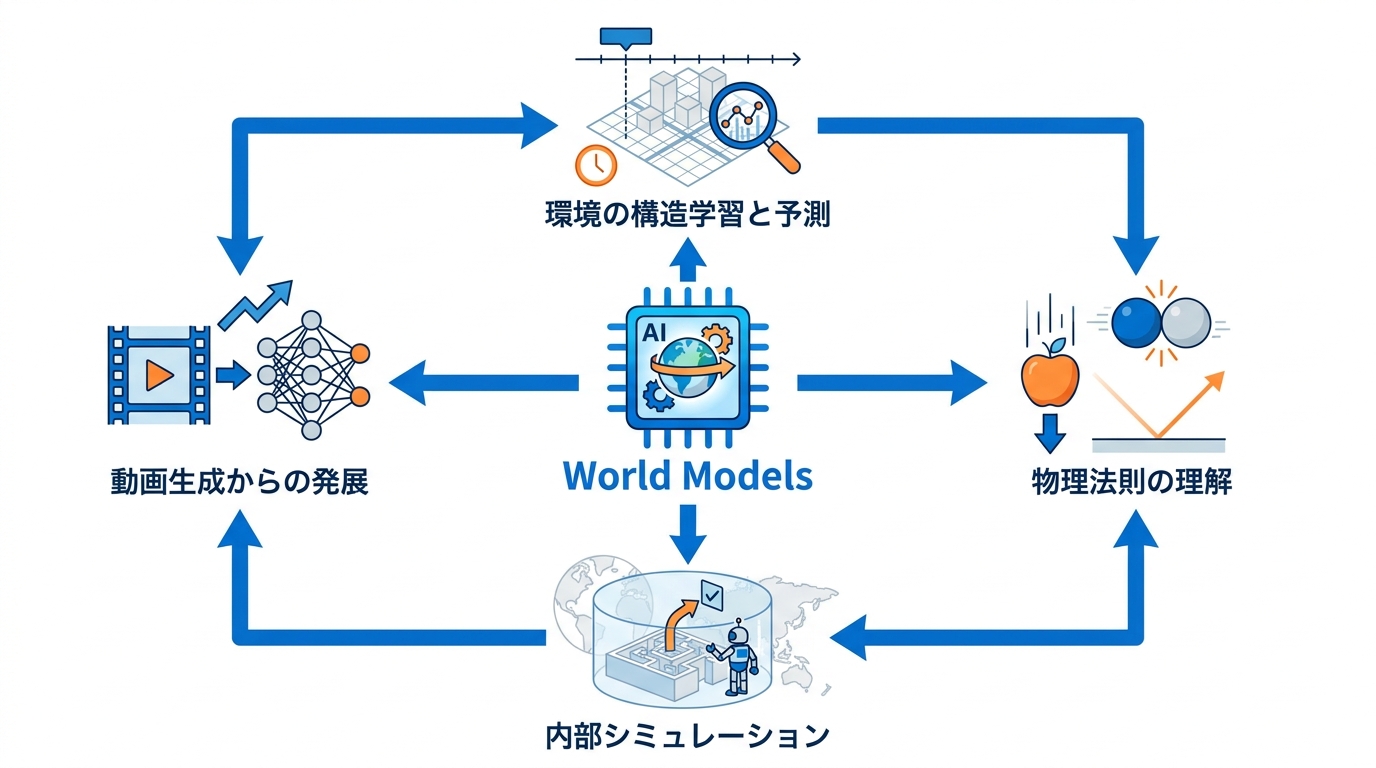
World Modelsとは、環境の空間的・時間的な構造を学習し、その環境内で何が起こるかを予測できるAIモデルの総称です。もともとは強化学習の分野で提唱された考え方で、環境の圧縮された表現を教師なし学習で獲得し、その表現をもとにエージェントが行動方針を学ぶという仕組みが示されていました(参照*1)。
この仕組みにより、エージェントは実際の環境で何度も試行錯誤しなくても、モデル内部のシミュレーションを通じて効率的にタスクを解けるようになります。World Modelsが扱う「環境」はゲーム空間に限りません。医療、自動運転、ロボティクスなど多様な産業で利用されており、物理世界を仮想環境上で再現できることが企業にとっての大きな価値となっています(参照*2)。
つまりWorld Modelsは、AIが「目の前の画像を生成する」段階から「世界の仕組みを内部に持ち、未来を予測する」段階へ進むための基盤技術にあたります。生成AIの進化を追ってきた私の感覚では、この転換は「文章を書くAI」から「推論するAI」への変化に似た構造的なシフトです。道具としての性質が根本から変わる、という点で重要だと考えています。
動画生成AIからの発展経緯
Runwayは2018年の創業以来、テキストから映像を生成するモデルを中心に事業を築いてきました。最新のGen-4.5を含む動画生成ツールは映画制作者や広告代理店の制作工程に組み込まれ、LionsgateやAMC Networksといった大手メディア企業との契約も結んでいます(参照*3)。
こうした動画生成の技術蓄積を踏まえ、Runwayは「AIの次の大きな進歩は、視覚世界とその力学を理解するシステムから生まれる」との考えのもと、General World Modelsと呼ぶ長期研究プログラムを開始しました(参照*4)。動画データには物体の動き・光の変化・衝突といった物理的な情報が大量に含まれます。それを学習素材として活用することで、単なるピクセルの生成ではなく、物理法則を内包したシミュレーションモデルへと進化させる道筋が開けたわけです。私がこのアプローチを面白いと感じるのは、「映像制作ツール」として蓄積したデータが、全く異なる産業領域への参入武器になっている点です。ビジネスとしての転換の巧みさと言ってもいいと思います。
この方向転換を支える資金調達も進んでおり、企業評価額は53億ドルに達しました。調達した3億1,500万ドルの資金はWorld Modelsの研究開発に充てられています(参照*2)。
RunwayのWorld Models戦略
GWM-1の技術的特徴
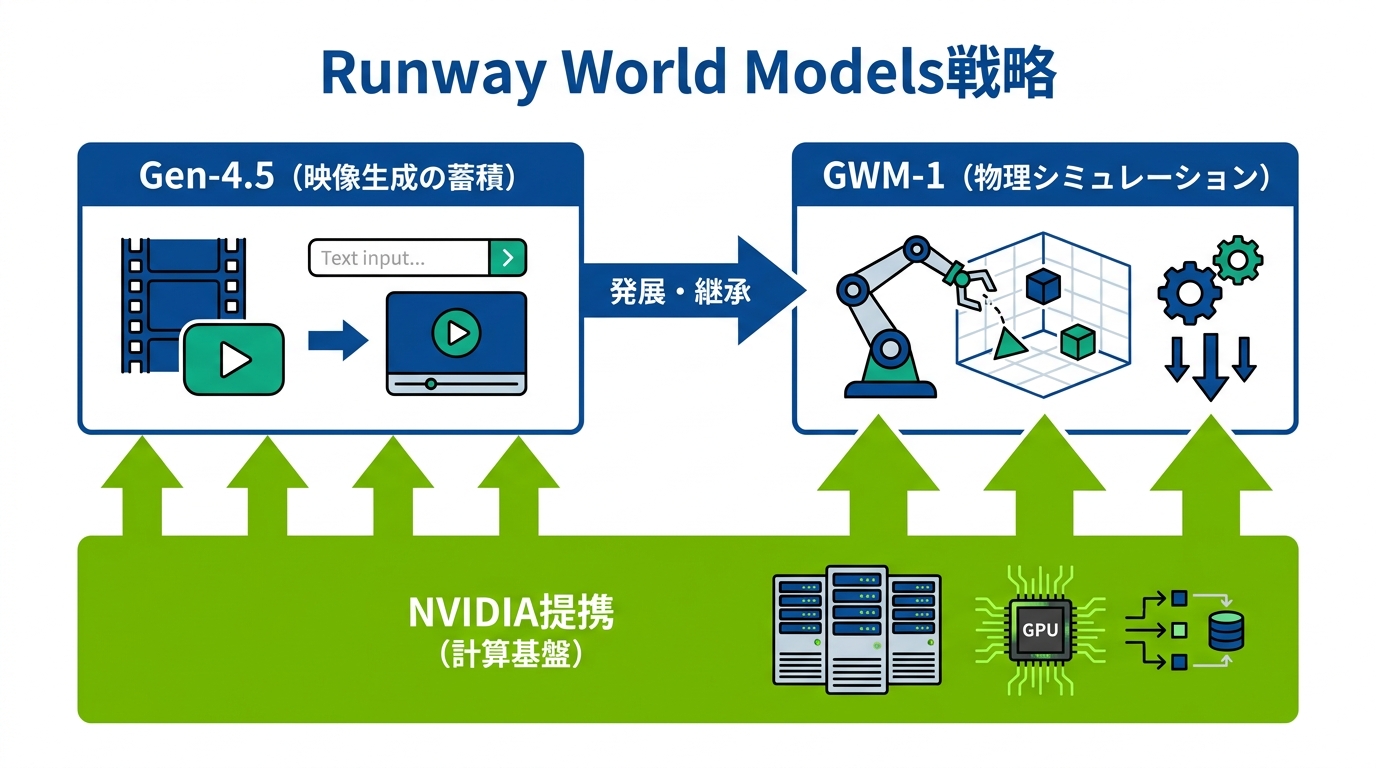
GWM-1は、RunwayがリリースしたGeneral World Modelsファミリーの第1弾です。共同創業者兼CEOのCristóbal Valenzuelaは「GWM-1は単にピクセルを生成するのではなく、その背後にある世界を理解しシミュレーションするモデルへの第一歩」と述べています。GWM-1は長いコンテキストを扱える物理法則対応のモデルであり、ロボティクスの訓練、探索可能な仮想世界、対話型のアバターといった用途に対応します(参照*5)。
従来の動画生成モデルが「与えられたプロンプトに沿った映像を出力する」ことに主眼を置いていたのに対し、GWM-1は物理的な整合性をリアルタイムで保ちながら環境をシミュレーションする点が異なります。たとえばロボットが物体をつかむ場面では、重力や接触の挙動が反映された映像が生成されるため、実機テストの前段階として利用できます。私がAIを業務で使い倒してきた経験から言えば、「それらしく見える」と「物理的に正しい」の差は、実装フェーズで大きな問題になります。GWM-1の方向性は、そこを正面から取りに行くアプローチです。
Gen-4.5との関係性
Runwayの動画生成ツールとしての顔であるGen-4.5は、テキストプロンプトから編集可能な映画品質の映像を生成するモデルです。映画制作者や広告代理店が日常の制作工程で使っており、LionsgateやAMC Networksとの提携でも活用されています(参照*3)。
Gen-4.5が「映像をつくるツール」であるのに対し、GWM-1は「世界を理解しシミュレーションする基盤」という位置づけです。両者は排他的な関係ではなく、動画生成で培った大量の映像データと学習パイプラインがWorld Modelsの開発基盤を支えています。Gen-4.5で蓄積した映像理解の技術が、GWM-1の物理法則対応へと発展した流れといえます。
NVIDIAとの提携と計算基盤
RunwayはNVIDIAと提携し、NVIDIAの次世代プラットフォームであるVera Rubinを計算基盤として活用しています。CEOのValenzuelaは「長いコンテキストを扱い物理法則を考慮する負荷の高い処理は、まさにNVIDIA Rubinプラットフォームが得意とする領域」と説明し、両社の協力で探索可能な仮想世界、対話型アバター、ロボティクス訓練といった新しいWorld Modelsの開発を加速させる方針を示しました(参照*5)。
World Modelsはリアルタイムの物理シミュレーションを必要とするため、膨大な計算資源が欠かせません。NVIDIAの最新ハードウェアを活用できることは、GWM-1のようなモデルを実用的な速度で動かすうえで大きな強みとなります。スタンフォード大学の講師であるKian Katanforooshも、Runwayがこの方向性を実現するにはコンピューティング資源の確保が最も重要だと指摘しています(参照*3)。生成AIビジネスの難しさは、モデルの性能そのものより、それを支える計算基盤と組織的な意思決定にある、というのは私がコンサルティングの現場で繰り返し確認してきたことです。RunwayとNVIDIAの提携は、技術と計算資源の両面を一気に押さえようとする戦略として理解できます。
ロボティクス領域での実証
GWM-Roboticsの仕組み
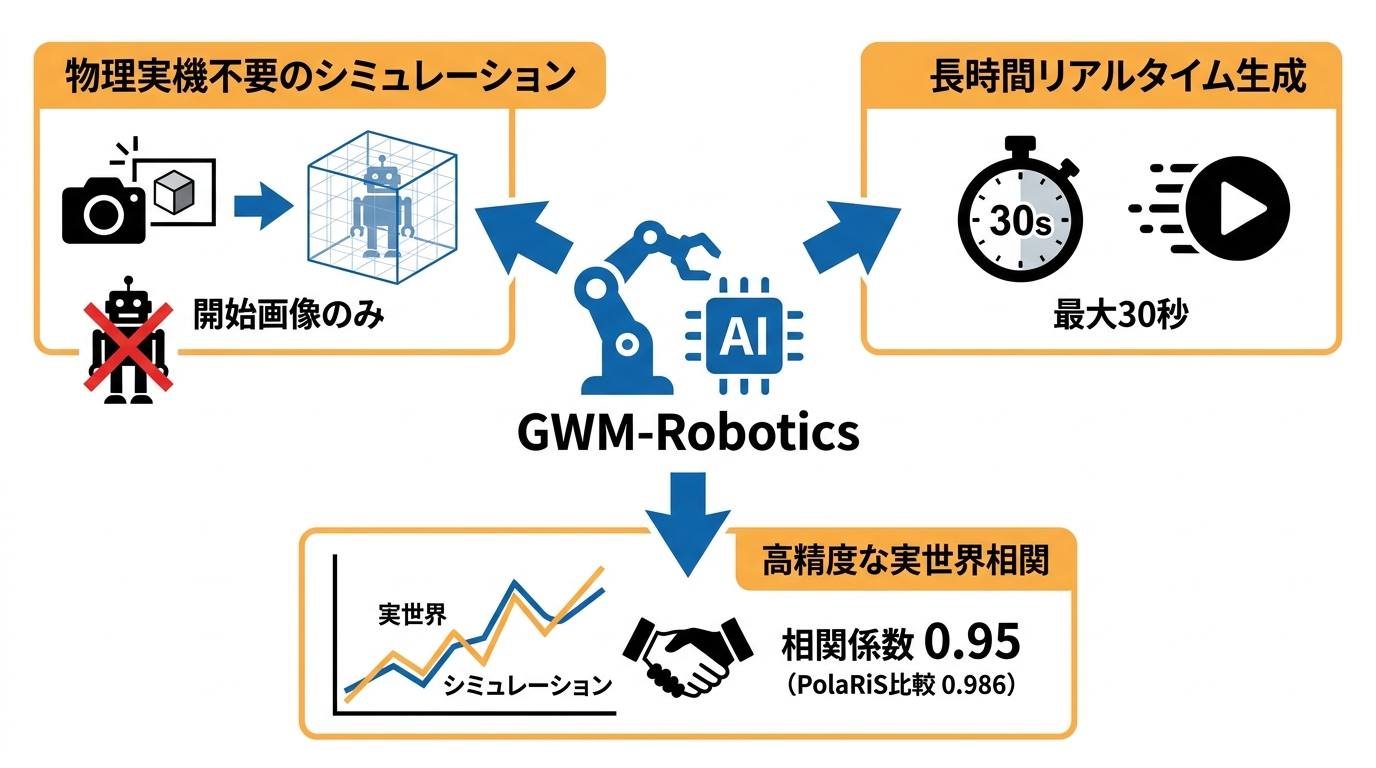
GWM-Roboticsは、ロボットの動作方針(ポリシー)をWorld Modelの内部で評価できるようにしたモデルです。物理的なロボット実機を使わずに、シミュレーション上でポリシーの成否を判定できる点が大きな特徴です。入力として必要なのは開始時点の画像のみであり、3Dスキャンやシーンの手動再構成といった前処理を必要としません(参照*6)。
さらにGWM-Roboticsは最大30秒のロールアウト(連続的な動作予測)をリアルタイムで生成できます。比較対象として挙げられているVeo Roboticsが8秒までに制限されているのに対し、より長い時間軸での動作検証が可能です。照明条件やオブジェクトの配置を変えたシナリオも物理実験室を用意せずに試せるため、テスト工程を大幅に効率化できます。
実世界との相関0.95の評価結果
GWM-Roboticsの精度を検証するため、8つのロボット操作ポリシーをシミュレーション上で実行し、その結果を実世界での実機テスト結果と比較する実験が行われました。8つのポリシー全体でシミュレーションと実世界のスコアの相関係数は0.95を記録し、World Modelが実機テストの信頼できる代替手段になり得ることが示されました(参照*6)。
PolaRiSと同条件の範囲に絞ると、GWM-Roboticsはより高い一致度を示しています。3Dガウシアンスプラッティングを用いた実世界再現フレームワークであるPolaRiSで評価されたポリシーと同じ範囲に限定して比較した場合、GWM-Roboticsのピアソン相関係数は0.986に達し、PolaRiSの0.98を上回りました。ランク順序の一致度を示すMMRVも0を達成しています。開始画像だけで動作し、スキャンや手動セットアップが不要であるにもかかわらずこの精度が出ている点は、実用面での優位性を裏づけています。私は新しいAIモデルの評価において、宣伝文句より具体的な数字を重視しますが、相関0.95という結果は単なるデモ映像とは重みが違います。ただし、この結果はあくまで特定の実験条件下のものであり、多様な環境での再現性は引き続き検証が必要です。
競合モデルとの比較
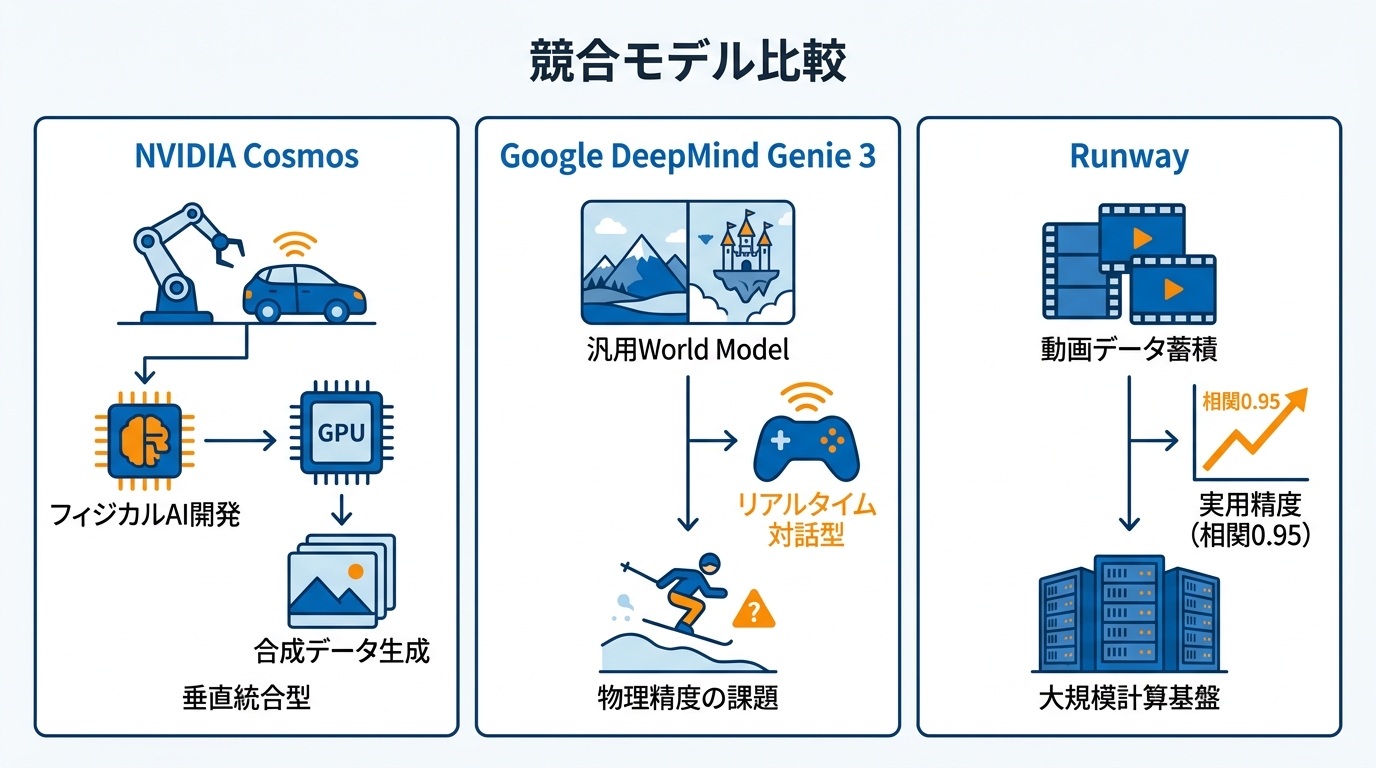
NVIDIA Cosmosの特徴と位置づけ
NVIDIAはCosmos(コスモス)という世界基盤モデル(World Foundation Model)プラットフォームを発表しています。Cosmosは、自動運転車やロボットといった「フィジカルAI」の開発を加速させることを目的とし、最先端の生成型World Foundation Model群、トークナイザー、ガードレール、動画処理パイプラインを一体で提供します。フィジカルAIモデルの開発には膨大な実世界データとテストが必要ですが、Cosmosは写真のようにリアルで物理法則に基づく合成データを大量に生成することで、その負担を軽減する設計です(参照*7)。
Cosmosの自己回帰モデルは、画像や動画の入力から次のフレームを高速に予測・生成できる構造を備えています。プラットフォーム全体がNVIDIAのGPUエコシステムと緊密に統合されているため、すでにNVIDIA環境を使っている開発者にとっては導入しやすい選択肢です。Runwayが動画データからの学習を強みとするのに対し、Cosmosはハードウェアから合成データ生成までの垂直統合型アプローチで差別化しています(参照*8)。
Google DeepMind Genieの特徴
Google DeepMindが開発したGenie 3は、リアルタイムで対話操作が可能な汎用World Modelとして発表されました。特定の環境に限定されず、写真のようにリアルな世界から想像上の世界まで幅広く生成できる点が特徴です。DeepMindのリサーチディレクターであるShlomi Fruchterは「以前存在していた限定的なWorld Modelsを超える、初のリアルタイム対話型の汎用World Model」と説明しています(参照*9)。
ただし、Genie 3にも制約があります。デモではスキーヤーが山を滑り降りる映像が示されましたが、スキーヤーと雪との物理的な相互作用が正しく反映されていないと指摘されており、エージェントが取れる行動の範囲にも限界があります。汎用性の高さと物理的な正確さの両立は、現時点ではどのWorld Modelにとっても難しい課題です。私がDeep Researchなどの生成AI機能を検証してきた経験でも、「見た目が整っているほど、内容の誤りに気づきにくい」という問題がありました。World Modelsも同様で、映像がリアルに見えるほど物理的な矛盾を見落としやすくなるリスクがあります。
Runwayの差別化ポイント
Runwayの差別化は、動画生成で蓄積した大量の映像データと学習基盤にあります。物理法則を考慮した動画モデルをWorld Modelsへ転用するという方向性は、LumaやWorld Labsといったスタートアップ、さらにはGoogleのGenieも同様に追求しています(参照*3)。
しかしRunwayは、GWM-Roboticsの実験でロボット操作ポリシーの実世界との相関0.95という具体的な検証結果を公表しており、World Modelの実用精度を定量的に示している点で他社と一線を画します。また、NVIDIAのVera Rubinプラットフォームとの提携により、大規模な計算基盤を確保している点も競争上の強みです。
主要ユースケースと応用先
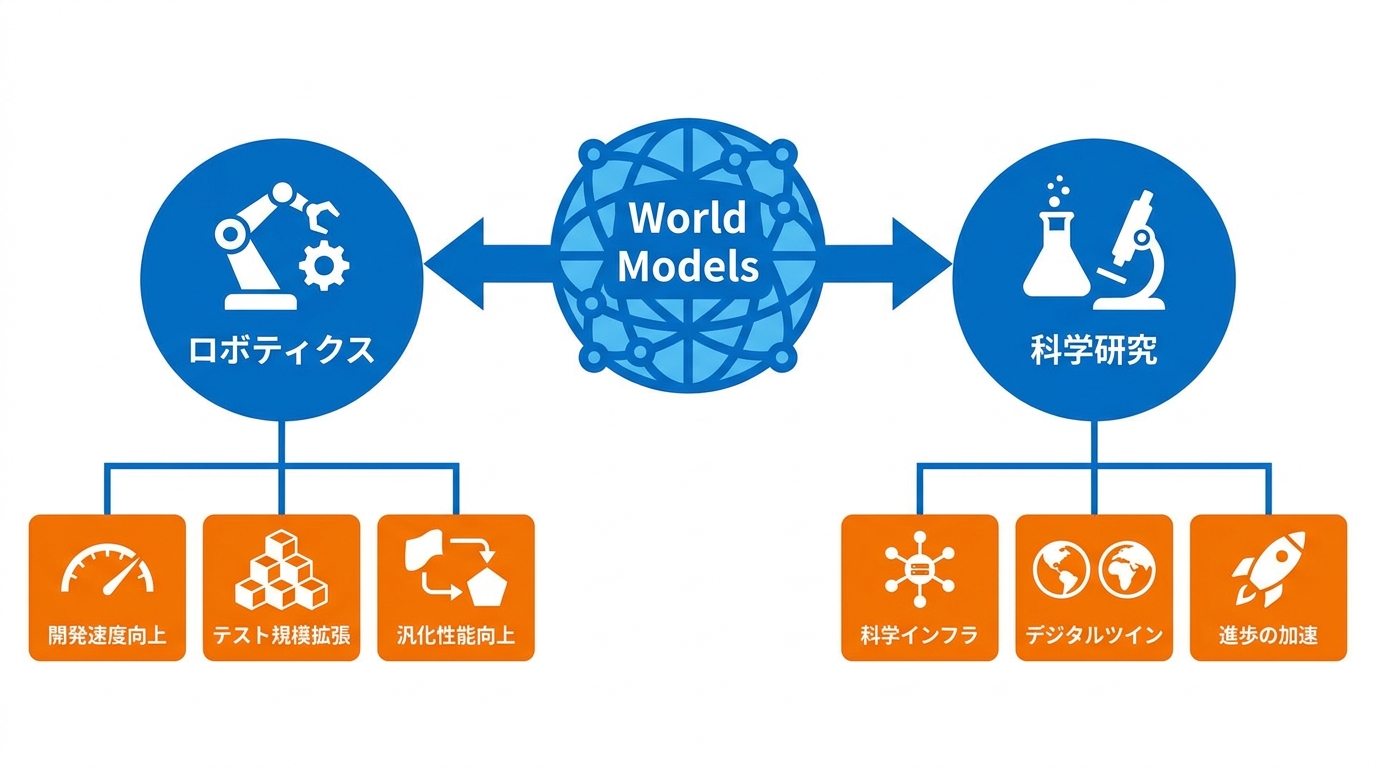
RunwayのWorld Modelsがもたらす具体的な応用は、ロボティクス、科学研究、エンターテインメントなど多岐にわたります。ロボティクスでは、候補となるポリシーをすべて実機で試すのではなく、シミュレーション上で順位付けしてから上位のものだけを物理テストにかけることで開発速度を高められます。照明やオブジェクト配置、タスク設定を変えた多様なシナリオも物理実験室を構築せずに評価できるため、テスト規模の拡張も容易です。さらに、少量の実世界データを出発点にオブジェクトや環境条件を仮想的に変化させれば、追加のデータ収集なしにモデルの汎化性能を向上させられます(参照*6)。私がコンサルティングで見てきた生成AI導入の現場では、「実験コストを下げること」と「検証サイクルを速めること」が最も効果的な入り口になります。World Modelsは、まさにその両方をロボティクス分野に提供する仕組みといえます。
科学研究への応用も視野に入っています。Runwayの共同創業者Anastasis Germanidisは、World Modelsを「科学インフラ」と位置づけ、多くの感覚データと観察結果を1つのモデルに学習させるほど、実験を実行できる宇宙のデジタルツインに近づくと述べています。科学研究の多くの時間が結果を待つことに費やされており、その待ち時間を圧縮できれば進歩そのものを加速できるという考え方です(参照*3)。
現状の課題と注意点
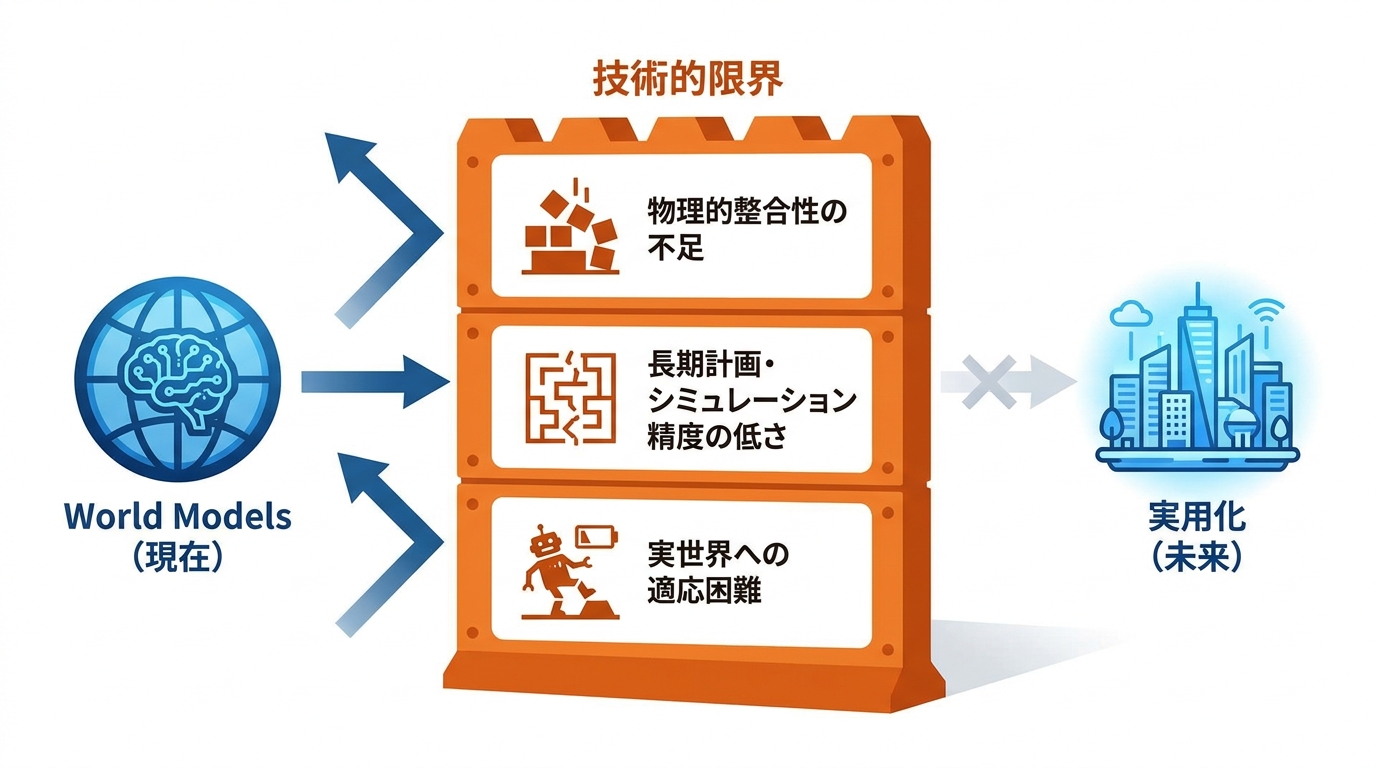
World Modelsの可能性は大きい一方で、技術的な限界も明らかになっています。World Modelsの評価用ベンチマークでは、長期的な計画立案のスコアが17.27にとどまり、物理的な整合性も最高で68.02にとどまっています。実世界での動作精度を測るテストでも多くのモデルの成功率がおよそ0%に落ち込む中、一部のモデルのみが40.74%の成功率を維持したという結果が報告されています(参照*10)。私がAIの業務導入で常に強調していることですが、技術的性能と実用上の信頼性は別の問題です。「できる」と「使える」の間には、検証設計と品質管理のコストが横たわっています。
Google DeepMindのGenie 3も、物理的な相互作用の再現が不完全であることやエージェントの行動範囲が限られていることが指摘されています(参照*9)。Runwayに対しても、映像理解からWorld Modelsを通じた汎用的な推論へ到達できるかはまだ証明されておらず、実現には膨大な計算資源の継続的な確保が不可欠であるとの指摘があります(参照*3)。物理的整合性と長期シミュレーションの精度をどこまで引き上げられるかが、今後の実用化を左右する焦点となります。新技術を評価するとき、私は宣伝文句より「何が測られ、何が測られていないか」を確認するようにしています。現時点のWorld Modelsは、その問いに正直に向き合う必要があるフェーズにあると見ています。
おわりに
Runwayは動画生成AIで培った映像データと技術基盤を武器に、World Modelsという新しい領域へ踏み出しました。GWM-1やGWM-Roboticsの発表、NVIDIAとの提携、そしてロボティクス分野での実世界相関0.95という検証結果は、この転換が単なるビジョンではなく具体的な成果を伴い始めていることを示しています。私が注目しているのは、映像制作ツールとして積み上げたデータ資産を、産業用シミュレーションという全く異なる領域の競争優位に転換しようとしているビジネスの構造です。
物理的整合性や長期計画の精度にはまだ課題が残ります。ただ、NVIDIAのCosmosやGoogle DeepMindのGenieを含めた競争の中で、Runwayが動画データ活用という独自の強みをどこまで伸ばせるかは、World Models領域全体の発展にも影響を与えていくはずです。「便利そうに見える」だけでなく、「実際に何が検証されたか」を見る姿勢を持ちながら、この領域の進化を追い続けることをお勧めします。
監修者
安達裕哉(あだち ゆうや)
デロイト トーマツ コンサルティングにて品質マネジメント、人事などの分野でコンサルティングに従事しその後、監査法人トーマツの中小企業向けコンサルティング部門の立ち上げに参画。大阪支社長、東京支社長を歴任したのち2013年5月にwebマーケティング、コンテンツ制作を行う「ティネクト株式会社」を設立。ビジネスメディア「Books&Apps」を運営。
2023年7月に生成AIコンサルティング、およびAIメディア運営を行う「ワークワンダース株式会社」を設立。ICJ2号ファンドによる調達を実施(1.3億円)。
著書「頭のいい人が話す前に考えていること」 が、82万部(2025年3月時点)を売り上げる。
(“2023年・2024年上半期に日本で一番売れたビジネス書”(トーハン調べ/日販調べ))
参照
- (*1) arXiv.org – [1803.10122] World Models
- (*2) AI Business – AI Startup Runway Raises $315M, Pivots to World Models
- (*3) Yahoo Finance – Runway started by helping filmmakers – now it wants to beat Google at AI
- (*4) General World Models: The Next Frontier in AI Research
- (*5) Runway Advances Video Generation and World Models With NVIDIA Rubin Platform
- (*6) Accelerating Robot Policy Evaluation with General World Models
- (*7) NVIDIA Launches Cosmos World Foundation Model Platform to Accelerate Physical AI Development
- (*8) NVIDIA NGC Catalog – Cosmos World Foundation Models
- (*9) https://techcrunch.com/2025/08/05/deepmind-thinks-genie-3-world-model-presents-stepping-stone-towards-agi
- (*10) Wow, wo, val! A Comprehensive Embodied World Model Evaluation Turing Test
