
はじめに
AIによる動画生成が急速に身近になり、テキストや画像から短い映像を作れるサービスが増えています。私は生成AIを毎日のように文章作成や調査に使っていますが、動画生成の進化も無視できない速度です。なかでもGrok Imagineの動画生成機能は、プロンプトの書き方ひとつで映像の質が大きく変わるため、やり方を正しく押さえることが欠かせません。
Grokでは、テキストから動画を作る方法に加え、画像からの変換、既存動画の編集や延長まで複数のモードが用意されています。この記事では、各モードの手順からプロンプトの書き方、よくある失敗の対処法まで順を追って説明します。なお、AIツールは「何ができるか」だけでなく「どう使うと成果が出るか」が重要です。その視点で読んでいただければ、より実務に役立てられると思います。
Grok動画生成の基本と仕組み
Grok Imagineとは
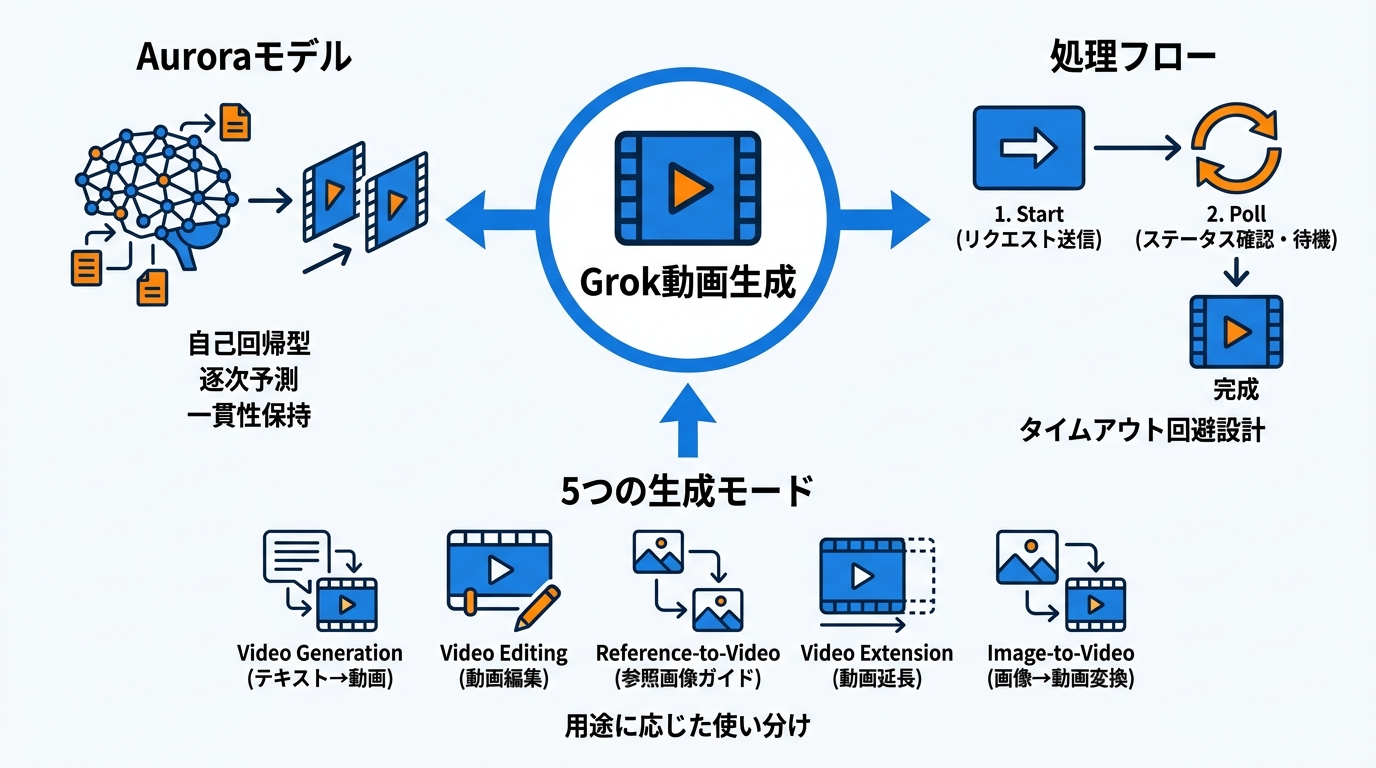
Grok Imagineは、xAIが提供する画像・動画の生成機能です。テキストプロンプトから6秒の動画を音声付きで生成したり、静止画を動画に変換したりできます。音声だけで画像を生成する機能も備えており、操作の入り口が幅広い点が特徴です(参照*1)。
動画生成の内部にはAuroraモデルが使われています。Auroraは、インターネット上の膨大なデータで訓練された自己回帰型のモデルで、画像のトークンを順番に予測する仕組みです。この逐次予測によってフレーム間の視覚的な一貫性が保たれやすくなっています(参照*2)。
動画生成の処理フロー
Grokの動画生成は、内部的に2つのステップで進みます。まず「Start」として生成リクエストを送信し、request_idを受け取ります。次に「Poll」として、そのrequest_idを使ってステータスを繰り返し確認し、動画が完成するまで待機します(参照*3)。
リクエスト送信と完了確認が分離されているため、生成に時間がかかる場合でもタイムアウトを起こしにくい設計になっています。APIを利用する場合は、このポーリングの仕組みを理解しておくと、エラー発生時の原因切り分けがしやすくなります。
対応する5つの生成モード
Grok Imagineは5つの生成モードに対応しています。1つ目は「Video Generation」で、テキストプロンプトから最大15秒の動画を生成できます。時間・アスペクト比・解像度を個別に設定できる柔軟さがあります。2つ目は「Video Editing」で、既存の動画にテキスト指示を与えて一部を修正しつつ、残りのシーンはそのまま残す機能です(参照*4)。
3つ目の「Reference-to-Video」は、1枚以上の参照画像を使って生成をガイドするモードで、最初のフレームを固定するのではなく、スタイルや構図の方向性として画像を活用します。4つ目は「Video Extension」で、既存動画の最終フレームから続きを生成し、元の動画と延長部分を1本のクリップにまとめます。そして5つ目として、画像から動画へ変換する「Image-to-Video」も利用でき、用途に応じてモードを使い分けることが動画生成のやり方の基本となります(参照*4)。
動画生成の手順と設定
テキストから動画を作る手順
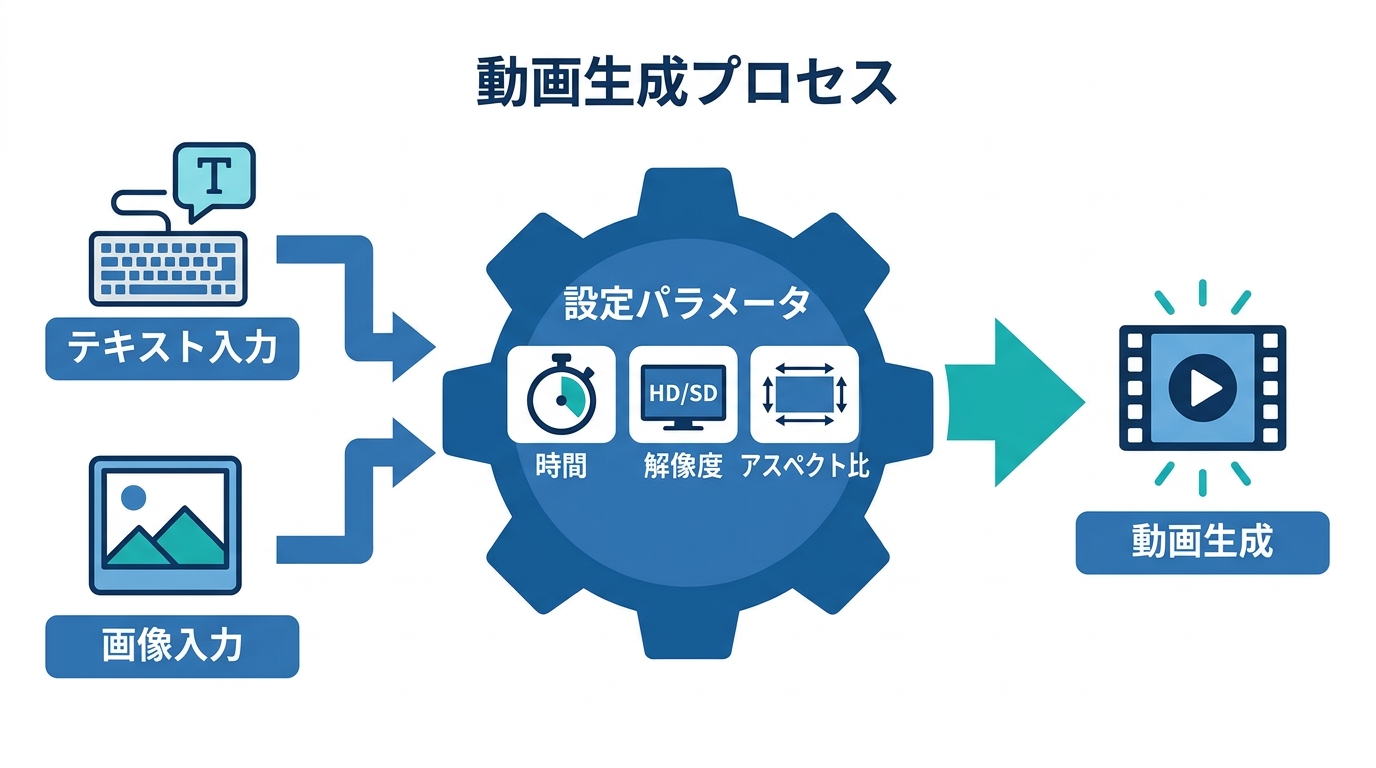
テキストから動画を作るやり方は、プラットフォーム上でモデルを選択し、プロンプトを入力するという流れが基本です。たとえばArtlist AI Toolkitでは、まずAI videoを選択し、次にモデルメニューからGrok Imagineを選びます。そこにテキストプロンプトを入力し、ムード・照明・被写体・スタイルを具体的に記述すると、数秒で映像が生成されます(参照*5)。
Python SDKを使う場合は、client.video.generate()にプロンプト・モデル名・秒数・アスペクト比・解像度を指定して実行します。たとえば「A serene lake at sunrise with mist rolling over the water」というプロンプトに、duration=5、aspect_ratio=”16:9″、resolution=”720p”を設定すると、5秒間のHD動画が生成されます(参照*6)。
画像から動画を作る手順
手元の画像を動かしたい場合は、Image-to-Videoモードを使います。SDKでは、client.video.generate()にimage_urlパラメータとして画像のURLを渡し、あわせてプロンプトで動きの指示を記述します。たとえば「The camera slowly zooms in as the scene comes to life」というプロンプトを添えることで、静止画がゆっくりとズームインしながら動き出す映像になります(参照*6)。
PixVerseを利用する場合も、出発点としてImageワークフローを選んでから、プロンプトを入力して生成する流れです。生成後は、動き・構図・被写体の一貫性・プラットフォームへの適合性を確認するとよいでしょう(参照*7)。
時間・解像度・アスペクト比の設定
動画の長さはdurationパラメータで制御でき、設定可能な範囲は1秒から15秒です。アスペクト比は用途に応じて選択でき、1:1はSNSやサムネイル向き、16:9と9:16はワイドスクリーンやモバイルのストーリーズ向き、4:3と3:4はプレゼンテーションやポートレート向き、3:2と2:3は写真風の仕上がりに適しています。既定値は16:9です(参照*3)。
解像度は720pと480pの2種類が用意されています。720pはHD画質で映像の精細さを重視する場合に適しており、480pは標準画質ながら処理速度が速い利点があります。既定値は480pのため、高画質を求める場合はresolutionパラメータを明示的に720pへ変更する必要があります(参照*3)。
プロンプトの書き方と実例
映画監督のように指示するコツ
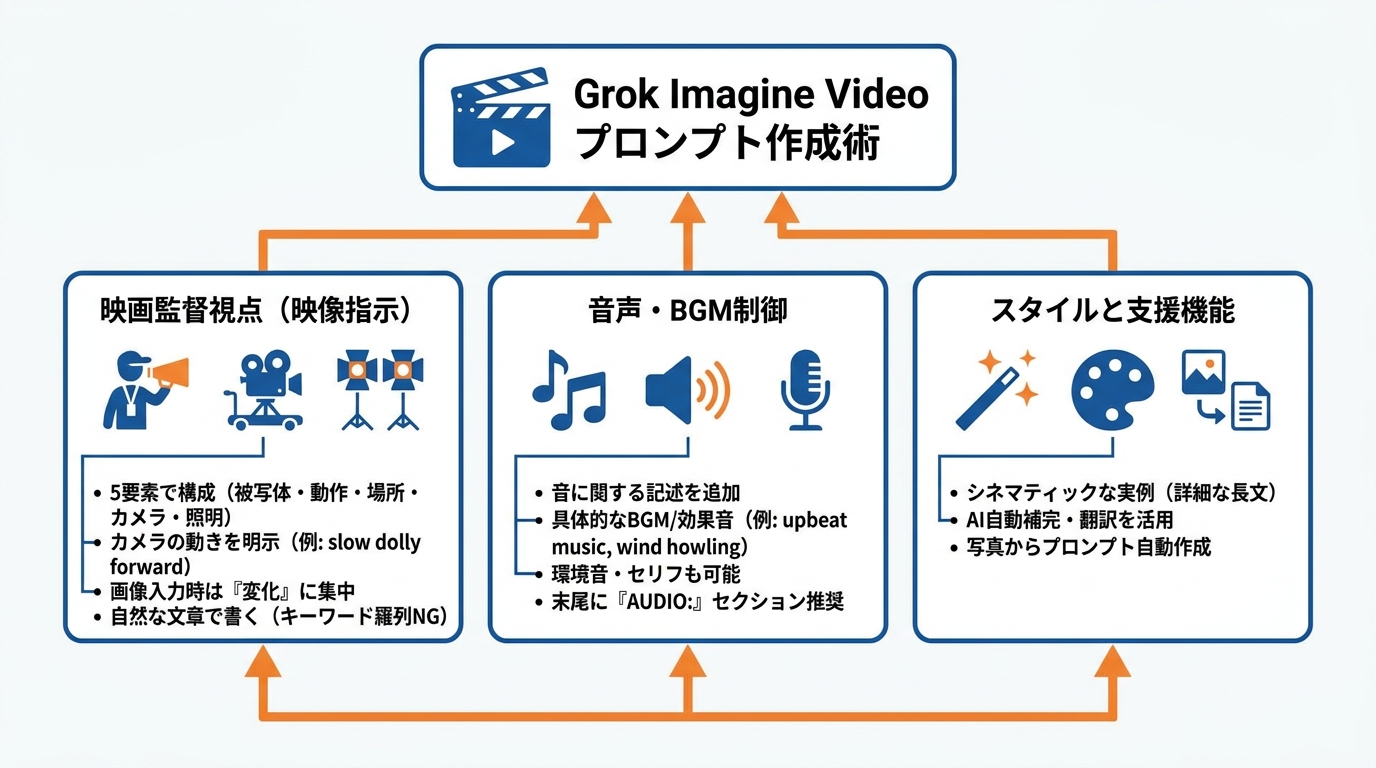
Grok Imagine Videoのプロンプトを書くうえで効果的なのは「映画監督のように考える」ことです。具体的には、被写体・動作・場所・カメラワーク・照明やムードの5要素を軸にプロンプトを構成します。たとえば「slow dolly forward」のようにカメラの動きを明示すると、意図した映像に近づきやすくなります(参照*2)。これは文章術と同じ考え方で、書き手が「何を見せたいか」を設計しないと、出力は曖昧になります。
画像から動画を作る場合は、被写体や背景を改めて説明する必要はありません。モデルはすでに画像の内容を認識しているため、プロンプトでは「何が変わるか」に集中します。動作・カメラの移動・雰囲気の変化といった動きに関する指示を中心に書くことが、意図どおりの映像を得るやり方です(参照*2)。
キーワードを羅列するのではなく、自然な文章で書くこともポイントです。意図を込めた1文のほうが、単語の列挙より正確な映像を引き出せます(参照*8)。私がテキスト生成でプロンプトを設計するときも同様で、箇条書きの羅列より、目的・制約・出力形式を自然な文脈で与えたほうが安定した出力が得られます。動画でも同じ原則が働いています。
音声・BGMをプロンプトで制御する方法
Grok Imagine Videoは映像と同時に音声もネイティブに生成します。音声をコントロールしたい場合は、プロンプト内で音に関する記述を加えるだけで反映されます。BGMであれば「with upbeat electronic music」や「dramatic orchestral score」、効果音であれば「footsteps on gravel」「wind howling」のように具体的に書きます(参照*2)。
環境音として「quiet café ambience」「forest sounds with birdsong」を指定したり、短いセリフを「a quiet whisper: ‘We made it.’」のように引用符で囲んで記述したりすることも可能です。音声の指定をプロンプト末尾に「AUDIO:」セクションとしてまとめると、映像指示と音声指示の区別が明確になり、意図が伝わりやすくなります(参照*2)。
スタイル別プロンプトの実例集
シネマティックな雰囲気を目指す場合の実例として、「Slow camera push through a foggy forest at dawn, sunlight breaking through the trees, cinematic and moody」というプロンプトがあります。Artlist上でAuto-prompt機能を使うと、これがさらに詳細に展開され、霧の中を進むカメラの動き、木漏れ日のハイライト、ささやくような風の音や遠くの鳥の声、静謐な音楽まで盛り込まれた長文プロンプトに仕上がります(参照*5)。
プロンプトに行き詰まった場合は、組み込みのAIツールで自動補完や翻訳を利用するやり方もあります。また、手元に写真がある場合はアップロードすると、モデルがその写真の内容を説明するプロンプトを自動で作成してくれるため、テキスト入力の手間が省けます(参照*9)。
セリフ付きの動画を作る場合は、プロンプト内にナレーションを引用符で記述します。たとえば「Narrator: \”The city never sleeps.\”」と書くことで、映像にナレーション音声が乗った動画を生成できます(参照*8)。
編集・延長・リファレンス機能
既存動画の編集とスタイル変換
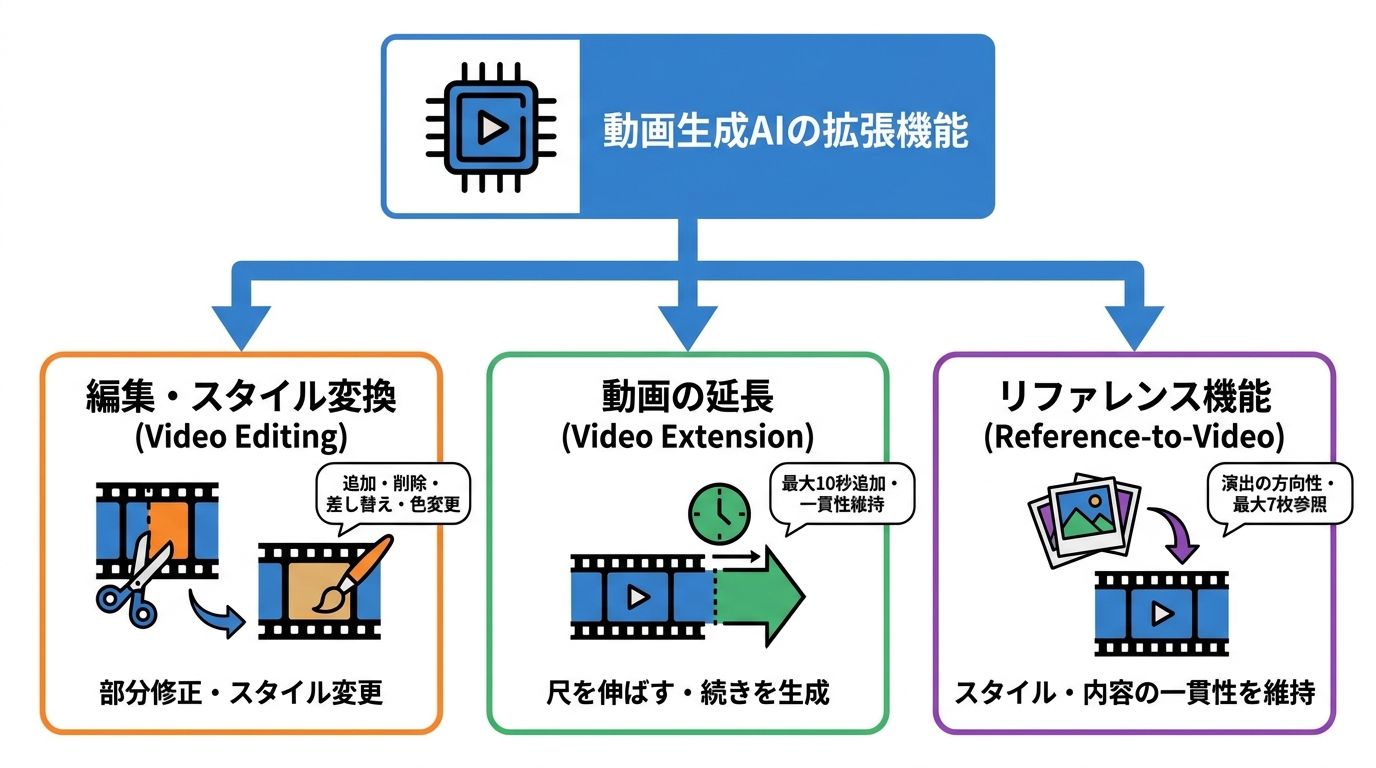
既存の動画を部分的に修正したい場合は、Video Editingモードを使います。SDKではclient.video.generate()にvideo_urlを渡し、プロンプトで変更内容を指示します。たとえば「Add a rainbow in the sky」と書けば空に虹が追加され、言及しなかった部分はそのまま保持されます(参照*6)。
編集の指示は、追加・削除・差し替え・スタイル変換・場面変更・色変更など多岐にわたります。「Remove the bee from the scene」で蜂を除去したり、「Restyle this as cyberpunk anime with neon-charged lines」でサイバーパンクアニメ調に変換したりできます。入力動画は最大8.7秒まで対応しており、出力は入力と同じ尺・アスペクト比になり、解像度は入力に合わせつつ上限は720pです(参照*2)。
動画の延長で尺を伸ばす方法
生成した動画の尺が足りない場合は、Video Extensionモードで続きを生成できます。SDKではclient.video.extend()にvideo_urlとプロンプト、延長したい秒数を指定して実行します。たとえば「The camera slowly zooms out to reveal the city skyline」と書いてduration=6を設定すると、元動画の最終フレームから6秒間の続きが生成され、1本のクリップにまとまります(参照*6)。
入力動画は最大15秒まで受け付けることができ、延長は最大10秒まで追加できます。10秒の延長にかかる生成時間は約60秒です。動きと音声の一貫性が自動的に維持されるため、つなぎ目が不自然になりにくい設計です(参照*10)。
リファレンス画像で一貫性を保つ手法
Reference-to-Video(R2V)モードは、1枚以上の画像をスタイルや内容の参考として動画生成に反映させる機能です。Image-to-Videoのように画像が最初のフレームになるのではなく、画像の視覚的なスタイル・被写体・構図を「演出の方向性」としてモデルに渡します。テキストプロンプトとあわせて最大7枚の参照画像を指定できます(参照*11)。
ComfyUIのGrok Reference-to-Videoノードでも同様に最大7枚の参照画像に対応しており、720pで10秒の動画を生成する場合の所要時間は約100秒です。シリーズものの動画で世界観を統一したい場合や、ブランドカラーを一貫させたい場合に、このモードを活用することで視覚的なまとまりを確保しやすくなります(参照*10)。
外部ツールでの活用と比較
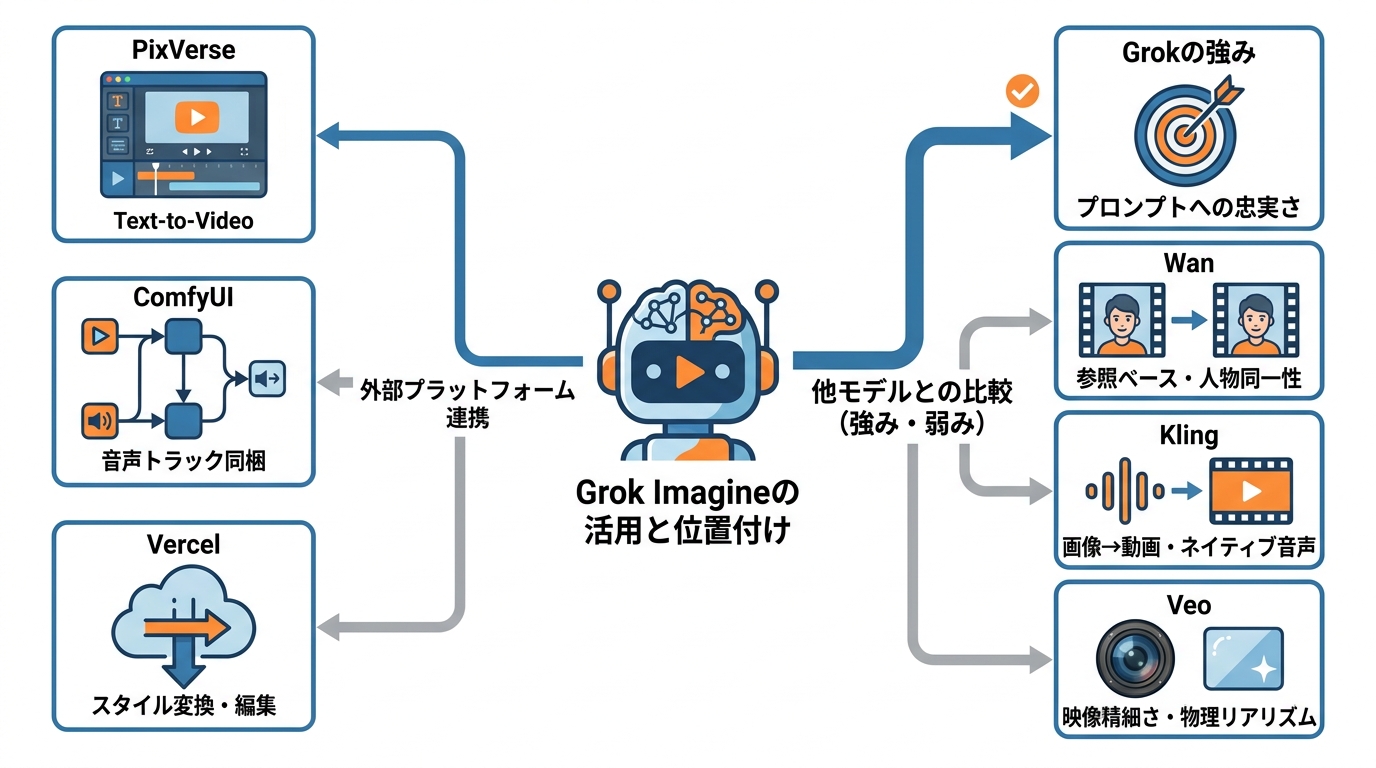
主要プラットフォームでの使い方
Grok Imagineは、xAI公式のAPIやアプリ以外にも複数のプラットフォームから利用できます。PixVerseではモデル選択画面からGrok Imagineを選び、Text-to-Video、Image-to-Video、Reference、Extendの4つのワークフローを使い分けることができます。プロンプト入力後に尺・アスペクト比・解像度を設定し、生成された映像の動き・構図・一貫性を確認する流れです(参照*7)。
ComfyUIでは、GrokVideoNodeにテキストプロンプトを入力するか、LoadImageノードから開始フレームを渡すことで動画を生成できます。生成結果はモデルが作成した音声トラックとセットで返されるため、映像と音声を別々に用意する手間がかかりません(参照*12)。
VercelのAI Gatewayを経由してGrok Imagineを呼び出す方法もあり、スタイル変換を含む動画の生成と編集を数秒で実行できる環境が整っています(参照*13)。
他モデルとの強み・弱みの比較
Grok Imagineの最大の強みは、プロンプトへの忠実さです。動き・ペース・場面転換をプロンプトで指定した際に、意図どおりの映像が返されやすいと評価されています。品質と生成速度、コストの総合指標でも上位に位置しており、プロンプトの調整と再生成を繰り返しやすい点が実用上のメリットです(参照*8)。私がモデルを比較するときに重視するのは、宣伝文句ではなく実際の業務課題に対してどれだけ使えるかです。プロンプトに正直に反応するかどうかは、反復して使う実務ではとくに重要な指標です。
一方で、他のモデルにはそれぞれ異なる得意領域があります。AlibabaのWanは参照ベースの生成やマルチショットの物語表現に強く、シーン間で人物の同一性を保つ機能を持っています。Klingは画像から動画への変換とネイティブ音声に優れ、3.0モデルでは自動的なシーン遷移にも対応しています。GoogleのVeoは映像の精細さや物理的なリアリズムが高く、映画的な照明や物理表現に強みがあります(参照*13)。どのモデルが優れているかは用途次第です。まず手元のタスクで試し、目的に合うかどうかを自分で確かめることが先決です。
よくある失敗と注意点
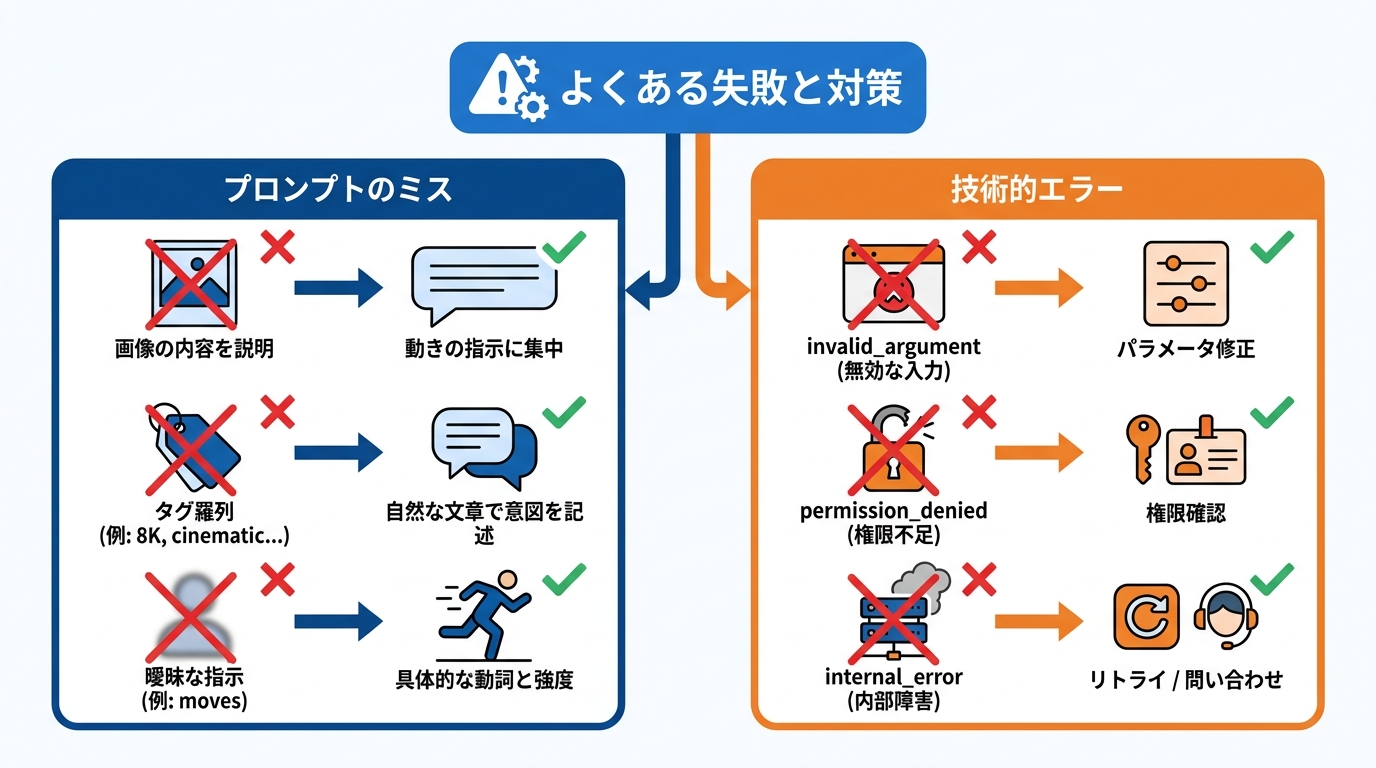
初心者が陥りやすいプロンプトミス
Image-to-Videoモードで最も多い失敗は、画像の内容を改めてプロンプトで説明してしまうことです。モデルはすでに画像を認識しているため、動きの指示に集中する必要があります。また、元画像と矛盾する指示を出すと、意図しない映像になりやすいため、画像の内容に沿ったプロンプトを書くことが大切です(参照*2)。
「knight, castle, epic, 8K, cinematic」のようにタグを羅列する書き方も避けるべきやり方です。自然な文章で意図を込めた1文にまとめるほうが、モデルは適切に反応します。さらに、カメラの方向やショットタイプを省略すると映像が単調になりやすく、動きの表現も「the thing moves」のように曖昧にせず、具体的な動詞と強度を示す修飾語を使う必要があります。なお、ネガティブプロンプトは無視されるため、「不要なもの」ではなく「欲しいもの」を記述する方針で書きます(参照*2)。
技術的エラーと対処法
APIを利用する際に返されるエラーにはいくつかの種類があります。invalid_argumentは、未対応の秒数や無効な入力メディア、長すぎるプロンプト、モードの競合、モデレーションによるブロックなどが原因で、リクエストのパラメータや入力メディアを修正して再送信する必要があります。permission_deniedはAPIキーやチームの権限不足で発生するため、キーの所属チームと権限を確認します(参照*3)。
failed_preconditionは、選択したモデルや設定では対応できない操作を指定した場合に返されるため、モデル・モード・解像度などの設定を変更します。internal_errorはサービス内部の障害に起因するため、リトライで解消する場合が多いですが、繰り返し発生する場合はrequest_idを添えてxAIサポートに問い合わせます。またR2Vモードでは、Image-to-VideoやVideo Editingとの併用ができず、最大尺も10秒とText-to-Videoの15秒より短い点に注意が必要です。参照画像が大きすぎるとペイロード上限に達するため、長辺を約4000px以下にリサイズしてからアップロードします(参照*11)。
おわりに
Grokの動画生成は、テキスト入力からImage-to-Video、編集、延長、Reference-to-Videoまで5つのモードを備えており、やり方を理解すれば用途に応じた映像を柔軟に作れます。プロンプトは映画監督のように被写体・動作・カメラワーク・音声を具体的に書くことが成果につながります。これはテキスト生成でも動画生成でも変わらない原則で、AIへの指示は抽象的な依頼より、目的と制約を具体的に与えるほうが安定します。
エラーが出た際はエラーコードの意味を確認してパラメータを修正し、各モードの制約条件を押さえたうえで再挑戦することで、スムーズに動画制作を進められます。AIツールは一発で完璧な出力を求めるより、調整と再生成を繰り返す前提で使うほうが、結果的に早く目的に到達します。
監修者
安達裕哉(あだち ゆうや)
デロイト トーマツ コンサルティングにて品質マネジメント、人事などの分野でコンサルティングに従事しその後、監査法人トーマツの中小企業向けコンサルティング部門の立ち上げに参画。大阪支社長、東京支社長を歴任したのち2013年5月にwebマーケティング、コンテンツ制作を行う「ティネクト株式会社」を設立。ビジネスメディア「Books&Apps」を運営。
2023年7月に生成AIコンサルティング、およびAIメディア運営を行う「ワークワンダース株式会社」を設立。ICJ2号ファンドによる調達を実施(1.3億円)。
著書「頭のいい人が話す前に考えていること」 が、82万部(2025年3月時点)を売り上げる。
(“2023年・2024年上半期に日本で一番売れたビジネス書”(トーハン調べ/日販調べ))
参照
- (*1) App Store – Grok – AI Assistant
- (*2) Grok Imagine Video
- (*3) Video Generation
- (*4) Imagine Overview
- (*5) Artlist Blog – Grok Imagine AI: Generate Images & Videos on Artlist
- (*6) GitHub – xai-org/xai-sdk-python: The official Python SDK for the xAI API · GitHub
- (*7) PixVerse | Create Amazing AI Videos from Text & Photos with AI Video Generator – Grok Imagine on PixVerse: Create AI Videos in 2026
- (*8) getimg.ai – Grok Imagine by xAI: How It Stacks Up in AI Video Generation
- (*9) Grok Imagine Video: A Guide to AI Motion Creation
- (*10) Grok Imagine Model Feature Updates
- (*11) Grok Imagine R2V
- (*12) ComfyUI Workflows – Grok: Video generation
- (*13) Vercel – Video Generation with AI Gateway
