
はじめに
議事録の手入力は、会議録音を聞き返す負担が大きい作業です。私自身、コンサルティング会社時代から議事録作成に膨大な時間を使ってきた経験がありますが、Geminiの文字起こし機能とプロンプトの工夫によって、この負担は大幅に変わります。
プロンプト次第で、話者の分離やタイムスタンプの付与、要約の自動抽出まで一度の指示で実現でき、議事録作成の手間を大幅に削減できます。ただし、ここで重要なのは「プロンプトさえ書けば完成する」という話ではないことです。何を出力させ、どう後工程と連携させ、どこを人間が確認するかを設計しないと、便利な実験で終わります。本記事では、Geminiの文字起こしの仕組みからプロンプトの具体的な書き方、精度を高めるチューニング手法、そしてよくある失敗への対策までを順に解説します。
Gemini文字起こしの仕組み
対応フォーマットとトークン計算
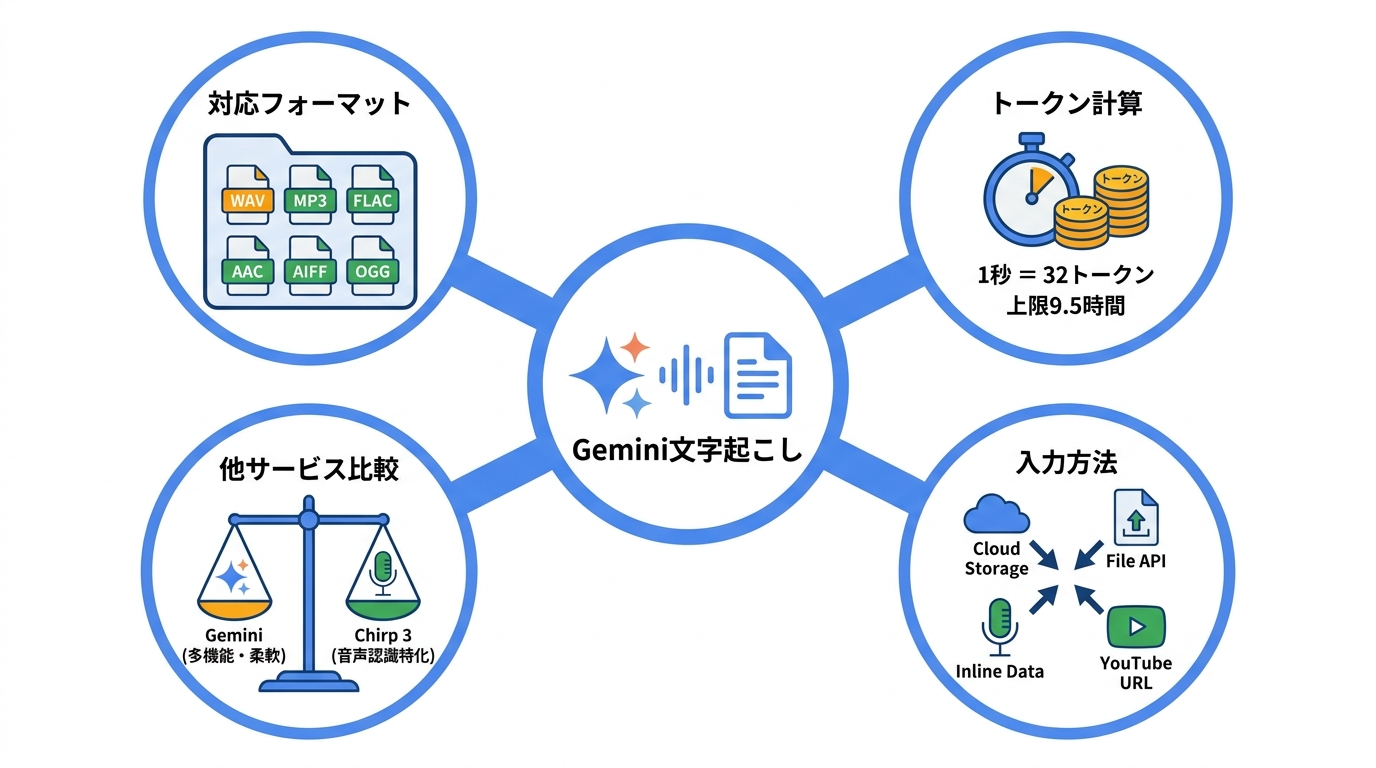
Geminiに音声を入力する際は、対応するファイル形式の確認が必要です。GeminiはWAV、MP3、AIFF、AAC、OGG Vorbis、FLACの各形式をサポートしています。一般的な会議録音で使われるMP3やWAVはもちろん、高音質録音に用いられるFLACにも対応しているため、多くの録音環境でそのまま利用できます(参照*1)。
トークン数には処理量の目安となる基準があります。Geminiは音声1秒あたり32トークンとして扱い、1分間の音声は1,920トークンに換算されます。1回のプロンプトで入力できる音声の上限は9.5時間です(参照*1)。
1時間の会議録音であればおよそ115,200トークンとなり、Geminiの100万トークンのコンテキスト枠に対して十分な余裕があります。長時間の会議でも分割せずに一括処理できる点は、議事録作成の効率を高めるうえで実用的な強みです。ただし、トークン枠が大きいことと、出力の品質が安定することは別の話です。長時間音声を一括処理するほど、後半のタイムスタンプがずれるリスクも上がります。この点は後述の「よくある失敗と対策」で触れます。
音声・動画の入力方法
Geminiへ音声や動画を渡す方法は、ファイルサイズや用途に応じて複数用意されています。File APIは有料版で最大20GB、無料版で最大2GBのファイルに対応し、100MBを超える大きなファイルや10分以上の長尺動画に適しています。Cloud Storageからの読み込みでは1ファイルあたり最大2GBで、永続的に再利用したい場合に向いています(参照*2)。
100MB未満の小さなファイルや1分以内の短い音声であれば、Inline Dataとしてリクエストに直接埋め込む方法が手軽です。さらに、公開されているYouTube動画のURLをそのまま入力として指定することもできます(参照*2)。
会議録音の場合、録音ファイルが数百MBに達することも珍しくありません。ファイルサイズと処理頻度を踏まえて入力方法を選ぶことで、アップロードの手間や処理の安定性を調整できます。
他サービスとの機能比較
Geminiの文字起こし性能を他のサービスと比べた検証結果があります。英語とハンガリー語の音声を対象にした比較では、Gemini 3が両言語で最も高い性能を発揮し、追加のツールなしにチャット画面上でほぼ完璧な文字起こしを生成しました(参照*3)。
Google Cloudには専用の音声認識モデルであるChirp 3も用意されています。Chirp 3はSpeech-to-Text API V2を通じて利用でき、認識リクエスト時にモデル識別子を指定することで呼び出せます(参照*4)。
Geminiはプロンプトで出力形式や要約を同時に指示できる柔軟さがあり、Chirp 3は音声認識に特化したAPIとして精度調整の機能を備えています。私が実務で使う場面では、まずGeminiで試し、固有名詞の認識精度や出力形式の安定性に問題が出たときにChirp 3との組み合わせを検討する、という順序が現実的だと考えています。議事録作成の目的や後工程の設計に合わせて、どちらを使うかを判断することが大切です。
文字起こしプロンプトの設計原則
基本プロンプトの構成要素
文字起こしの品質は、プロンプトに何をどう書くかで左右されます。ベンチマーク検証で用いられたプロンプトの例として、「Please transcribe this audio file exactly as spoken, including commas, numbers, and all punctuation.」というシンプルな指示があります。この最小限のプロンプトによって、モデル本来の文字起こし能力を引き出すことが検証の意図でした(参照*3)。
より高度な出力を求める場合は、プロンプトの要素を増やします。公式ドキュメントに掲載されたプロンプト例では、正確なタイムスタンプの付与、各セグメントの主要言語の検出、英語以外の場合の英訳の提供、話者の感情の判定、そして音声全体の要約の生成という5つの要件が1つのプロンプトに盛り込まれています(参照*1)。
基本プロンプトの構成要素を整理すると、「何を文字起こしするか」「どの形式で出力するか」「どこまで付加情報を含めるか」の3点に集約されます。私がAI活用の相談を受けるなかで気づくのは、この3点を曖昧にしたまま「議事録を作って」と投げてしまうケースが非常に多いことです。AIに何をさせるかを決めるのは人間の仕事であり、ここを手抜きすると出力も手抜きになります。議事録作成の場面では、この3点を明示することで、後から手直しする箇所を大幅に減らせます。
タイムスタンプ指定の書き方
議事録で「いつ誰が何を言ったか」を追跡するには、タイムスタンプの指定が欠かせません。Geminiでは「MM:SS」の形式でタイムスタンプを指定できます。動画に対しても同様に、MM:SSの書式で特定の時点について質問を投げることが可能です(参照*2)。
公式ドキュメントのプロンプト例では、「Provide accurate timestamps for each segment (Format: MM:SS)」と明記することで、出力の各セグメントに時刻が付与される仕組みになっています(参照*1)。
プロンプト内でフォーマットを具体的に指定しないと、タイムスタンプの有無や表記がばらつくことがあります。「Format: MM:SS」のように出力形式を括弧書きで添えると、統一された書式の文字起こしが得やすくなります。
言語・フォーマット指示の与え方
Geminiの文字起こしプロンプトでは、言語と出力形式の指示を組み合わせることができます。たとえば、promptの引数でフォーマットを指定しつつ、languageの引数で特定の言語ロケールを指定する方法があります。「Respond with plain text only.」のようにプロンプトで書式を制御し、言語ヒントと組み合わせて使うことが可能です(参照*5)。
多言語が混在する音声への対処法も報告されています。ヒンディー語と英語が切り替わるコードスイッチング音声に対して、特定のスクリプトの使用を明示的に禁止し、音声の切り替わりに合わせてスクリプトを忠実に切り替えるよう指示する「リテラル文字起こし制約」を設けた事例があります(参照*6)。
日本語の議事録でもカタカナ語や英語の固有名詞が頻出する場面は多いため、出力言語の制御方法をプロンプトに組み込んでおくことは実用的です。
議事録向けプロンプト実例集
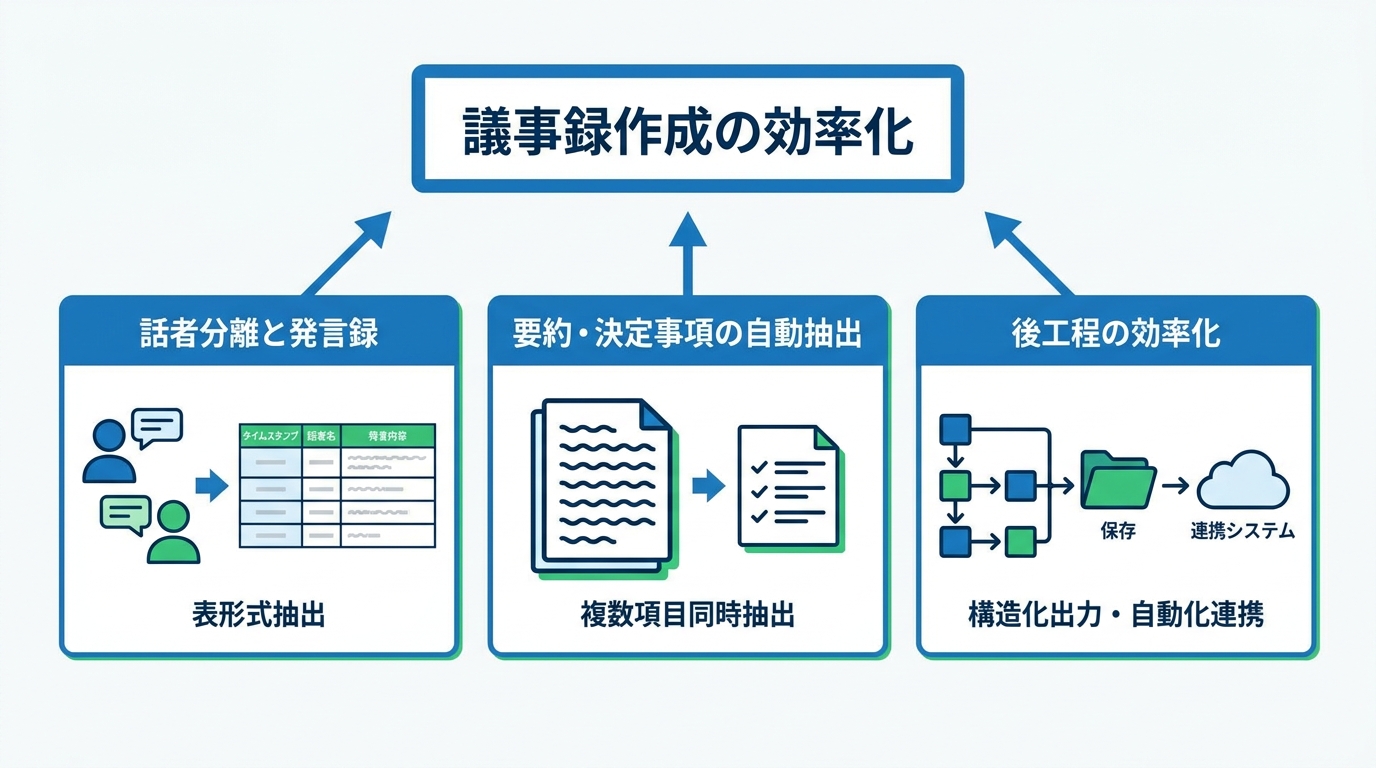
話者分離と発言録の生成
議事録の核心は「誰が何を言ったか」を正確に記録することです。Geminiのマルチモーダル動画文字起こしに関するチュートリアルでは、1つのプロンプトで「何がいつ話されたか」「話者は誰か」「誰が何を言ったか」という3つの問いに同時に答える手法が解説されています(参照*7)。
このチュートリアルでは、データの分離と注意力の保持を両立させるために、表形式での抽出というプロンプト技法が紹介されています。Geminiの100万トークンのコンテキスト枠を1回のリクエストで最大限に活用しながら、話者ごとの発言を構造的に整理する戦略です(参照*7)。
プロンプトで「表形式で出力せよ」と指示するだけで、タイムスタンプ・話者名・発言内容が列ごとに整理されるため、後から特定の発言を検索したり、発言者別に並べ替えたりする作業が格段に楽になります。
要約・決定事項の自動抽出
議事録では、全文の書き起こしに加えて要約や決定事項の整理が求められることが多いです。実際の会議でも、参加者が本当に必要としているのは録音の全文ではなく、「何が決まったか」「誰が何をやるか」「次回までに何を準備するか」の3点であることがほとんどです。Geminiでは、文字起こしと要約の指示を1つのプロンプトにまとめることができます。
Google Cloudの事例では、決算説明会の文字起こし全文を入力として与え、「全体の業績と経営陣のトーンを要約した概要」「主要な財務指標の箇条書き」「次の四半期や通年の見通し」「質疑応答の主要テーマ」の4項目を同時に抽出するプロンプトが示されています(参照*8)。
この構成は会議の議事録にも応用できます。プロンプト内で抽出したい項目を番号付きで列挙し、それぞれに期待する出力形式を添えることで、会議の結論や次のアクションを漏れなく拾い上げるプロンプトを設計できます。私が実務で使うときは、「決定事項」「未決事項」「アクション・担当者・期限」「次回確認すべき論点」の4項目を固定して出力させるようにしています。文字起こしをそのまま要約させるだけでは足りず、何を分けて整理させるかを事前に決めることが品質の鍵です。
構造化出力で後工程を効率化
文字起こしの結果は、別のシステムに連携する後工程を見据えて構造化出力にできます。Google Driveの動画を自動処理するワークフローの例では、指定フォルダ内の動画を取得し、Geminiで文字起こしを行い、結果をテキストファイルとして別フォルダに保存し、元の動画を処理済みフォルダへ移動するという一連の流れが自動化されています(参照*9)。
このようにプロンプトで出力形式を指定したうえで、保存先やファイル名のルールを自動化ツールと連携させると、議事録の作成から共有までの工程を一気に短縮できます。プロンプトの設計段階で後工程のデータ形式を意識することが、全体の効率化につながります。
精度を上げるチューニング手法
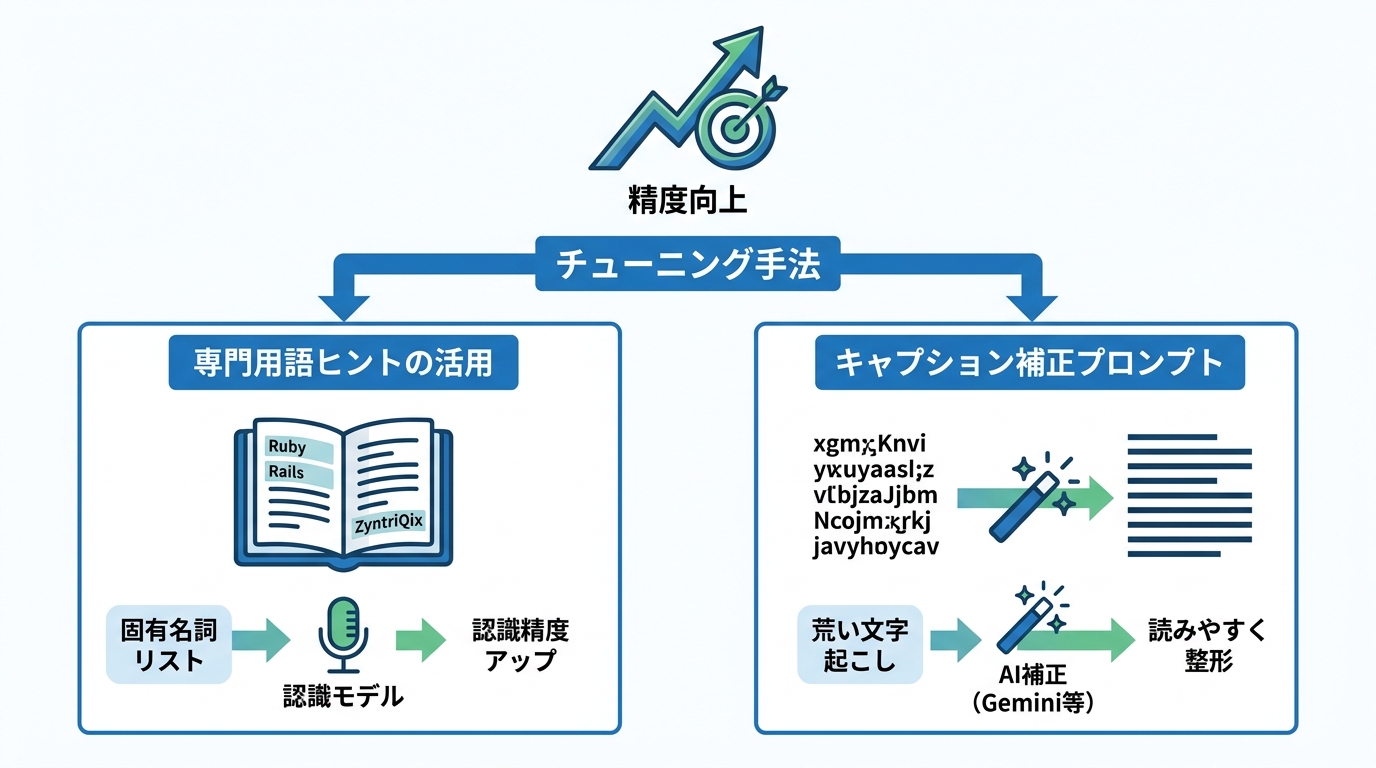
専門用語ヒントの活用
専門用語や製品名の認識精度は、議事録の品質に直結します。この問題に対処するため、プロンプトに専門用語のヒントを含める手法が有効です。
たとえば、「Discussion about Ruby, Rails, PostgreSQL, and Redis.」や「Product demo for ZyntriQix, Digique Plus, and CynapseFive.」のように、会議で登場する技術名や製品名をプロンプトの引数として渡すことで、認識精度を高められます(参照*5)。
Google CloudのChirp 3でも同様の仕組みが用意されており、モデル適応のために最大1,000フレーズの辞書を登録できます。特定の単語やフレーズのリストを提供することで、モデルがそれらを認識する可能性を高める設計です(参照*4)。
議事録を作成する前に、会議のアジェンダや資料から固有名詞を拾い出し、プロンプトに含めておくだけで、後から手動で修正する手間を大幅に減らせます。私自身がこれを試したとき、プロダクト名や人名の誤認識がほぼゼロになりました。手間は5分もかかりません。
キャプション補正プロンプトの技法
既存のキャプションをGeminiで補正し、読みやすく整えるアプローチがあります。自動生成された字幕や文字起こしには、誤字や不自然な区切りが含まれることがありますが、Gemini 3 Proの「Thinking」モードを使い、自動生成された字幕をプロフェッショナルで読みやすい形に整えるプロンプトが報告されています(参照*10)。
コードスイッチングを含む音声に対しては、2段階の戦略を採用した研究事例もあります。第1段階で専門的な文字起こしプロンプトを設計し、特定のスクリプトの混入を厳密に禁止しました。第2段階では、音声の切り替わりに合わせて忠実に文字を切り替える制約を課すことで、スクリプトの混在を防いでいます(参照*6)。
議事録の文字起こしでも、まず粗い文字起こしを生成し、次に補正用のプロンプトで整える2段階方式を取ることで、最終的な出力の品質を引き上げることができます。
よくある失敗と対策
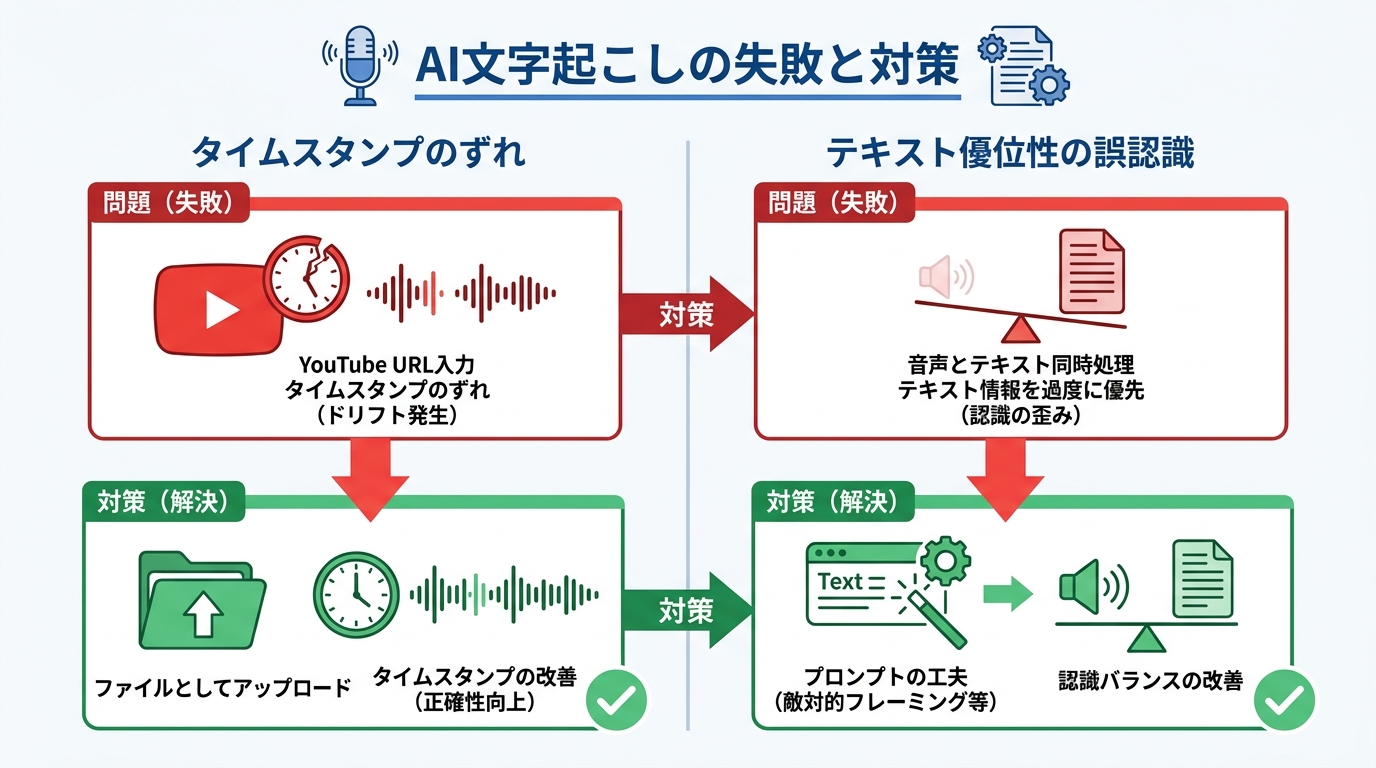
タイムスタンプのずれ問題
YouTube URLを入力として文字起こしを依頼すると、タイムスタンプがずれることがあります。YouTube URLを入力としてGemini Pro 2.5やFlash 2.5に文字起こしを依頼した場合、30分の動画であるにもかかわらず出力のタイムスタンプが17分付近で終わってしまうといった「ドリフト」が発生しました(参照*11)。
回避策として、同じ動画をYouTubeからダウンロードしてファイルとしてアップロードし、同一のプロンプトで文字起こしを依頼すると、タイムスタンプのずれは大幅に改善されました。YouTubeからの動画取得方法に起因する問題である可能性が指摘されています(参照*11)。
議事録の作成でタイムスタンプの正確さが求められる場合は、YouTube URLを直接渡すのではなく、録音や録画ファイルをダウンロードしてからアップロードする方法を選ぶと安全です。
テキスト優位性による誤認識
音声とテキストを同時に処理する際、テキスト情報を過度に優先してしまう傾向があります。Geminiのようなマルチモーダルモデルには、音声とテキストを同時に処理する際にテキスト情報を過度に優先してしまう「テキスト優位性」と呼ばれる傾向があります。研究によると、Gemini 2.0 Flashでは、音声をそのテキスト文字起こしに置き換えた場合と比較して、テキスト優位率(TDR)が10〜26倍高いことが確認されました。具体的には、音声入力時のTDRが16.6%であるのに対し、テキスト置換時は1.6%でした(参照*12)。
対策として、プロンプトに「意図的に破損した」という敵対的なフレーミングを加える手法が効果的であることも報告されています。この手法により、TDRが19%から3.8%へと80%の相対的低下を示し、モデル自体を変更することなく改善が得られました(参照*12)。
議事録作成の場面では、会議資料のテキストと音声を同時に入力する際に、テキスト情報が音声の認識結果を歪めてしまう可能性があります。これはAI固有の問題というより、「複数のモダリティが競合するとどちらを優先するか」というモデル設計の問題です。プロンプトの工夫だけで大幅に緩和できるため、音声とテキストを併用する場合はこの点を意識してプロンプトを設計する価値があります。まずは音声単体で文字起こしを試し、精度に問題があるときだけ資料テキストを追加する、という順序が安全です。
おわりに
Geminiの文字起こしは、プロンプト設計次第で議事録の自動生成まで活用範囲が広がります。タイムスタンプの書式指定、専門用語ヒントの追加、構造化出力の指示といったプロンプトの各要素を組み合わせることで、後工程の手間を含めた全体の効率化が期待できます。ただし、繰り返しになりますが、プロンプトを書くことよりも「何を出力させたいか」「どこを人間が確認するか」を決めることのほうが難しく、ここに時間をかけるべきです。
タイムスタンプのずれやテキスト優位性といった注意点も存在するため、入力方法やプロンプトの書き方で回避策を講じることが大切です。AIは候補を生成する道具であって、正確性を保証する道具ではありません。最終的な事実確認と承認は人間が引き受ける、という前提で運用設計をすることが、実務に定着させるうえでの出発点だと私は考えています。本記事で紹介した設計原則とチューニング手法を参考に、自社の会議運営に合ったプロンプトを組み立ててみてください。
監修者
安達裕哉(あだち ゆうや)
デロイト トーマツ コンサルティングにて品質マネジメント、人事などの分野でコンサルティングに従事しその後、監査法人トーマツの中小企業向けコンサルティング部門の立ち上げに参画。大阪支社長、東京支社長を歴任したのち2013年5月にwebマーケティング、コンテンツ制作を行う「ティネクト株式会社」を設立。ビジネスメディア「Books&Apps」を運営。
2023年7月に生成AIコンサルティング、およびAIメディア運営を行う「ワークワンダース株式会社」を設立。ICJ2号ファンドによる調達を実施(1.3億円)。
著書「頭のいい人が話す前に考えていること」 が、82万部(2025年3月時点)を売り上げる。
(“2023年・2024年上半期に日本で一番売れたビジネス書”(トーハン調べ/日販調べ))
参照
- (*1) Google AI for Developers – Google AI for Developers
- (*2) Google AI for Developers – Google AI for Developers
- (*3) PROMPTREVOLUTION – PROMPT REVOLUTION
- (*4) Google Cloud Documentation – Chirp 3 Transcription: Enhanced multilingual accuracy
- (*5) RubyLLM – Audio Transcription
- (*6) UrduSpeech: A 156-Hour Urdu Speech Corpus with 12-Dimension Paralinguistic Annotations
- (*7) Google Codelabs – Multimodal Video Transcription with Gemini
- (*8) Google Cloud Documentation – Use case: Summarize an earnings call transcript
- (*9) Batch transcribe Google Drive videos to text files with Gemini
- (*10) Fixing YouTube’s automatic captioning with AI
- (*11) GitHub – Timestamps not accurate when doing Youtube URL transcription · Issue #1359 · googleapis/python-genai · GitHub
- (*12) When Audio-LLMs Don’t Listen: A Cross-Linguistic Study of Modality Arbitration
