
はじめに
音声データをテキスト化する「文字起こし」は、議事録作成やインタビュー整理など多くの場面で必要になる作業です。私自身、取材やミーティングの音声を毎回手作業で整理していた時期があり、その非効率さは身に染みています。ChatGPTを活用すれば、この作業を大幅に効率化できます。ただし、やり方を間違えると情報の欠落や内容の捏造といったリスクが生じます。
正しい手順は「音声認識ツールで音声をテキストに変換し、そのテキストをChatGPTで整形・要約する」という2段階の流れです。ChatGPTに音声ファイルをそのまま渡せば完結する、と思っている方が多いのですが、それは誤解です。本文では、この基本のやり方から精度を高めるプロンプト設計、用途別の時短活用術、そして注意すべきリスクまでを順に解説します。
ChatGPT文字起こしの仕組み
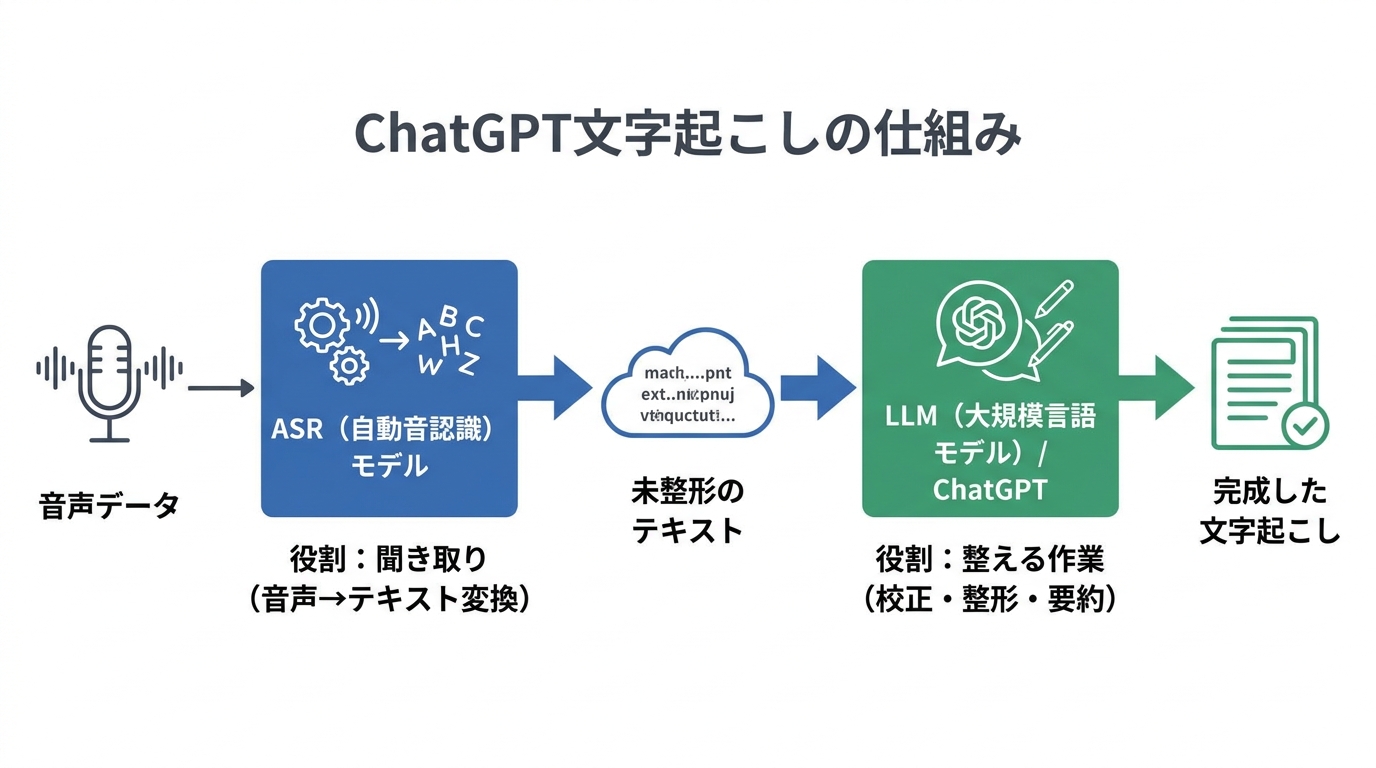
ASRとLLMの役割分担
ChatGPTを使った文字起こしは、2種類のAIモデルの連携で成り立っています。1つは自動音声認識(ASR)モデル、もう1つは大規模言語モデル(LLM)です。ASRモデルは音声データを受け取り、発話された言葉をテキストへ変換する役割を担います。一方のLLMは、変換後のテキストに対して句読点の補完や段落分け、要約などの「言語処理」を行います。
AI文字起こしツールは、この2種類の基盤モデルによって動作しており、ASRが「聞き取り」を、LLMが「整える作業」を分担する構造です(参照*1)。
つまり、文字起こしのやり方を理解するうえでは「音声をテキストに変える段階」と「テキストを整形・加工する段階」を別々の工程として捉えることが出発点になります。ChatGPTが得意なのは後者のテキスト処理であり、前者のASR処理には専用のツールが必要です。この役割の切り分けを最初に理解しておくだけで、後の設計がかなり楽になります。
ChatGPT単体でできること・できないこと
ChatGPTはテキスト処理に特化したモデルであり、動画や音声ファイルから直接発話を聞き取ることには向いていません。ChatGPTはテキストの扱いが得意であって、動画ファイルから音声を解読する機能は備えておらず、文字起こしには先に音声認識ツールが必要です(参照*2)。
ChatGPT-4はOpenAIのWhisper APIを利用して音声ファイルの文字起こしを行う形で使われることがありますが、その精度は一般的なケースで85〜92%程度にとどまるとの指摘があります(参照*3)。
したがって、ChatGPT単体で「音声を入れればそのまま完璧な文字起こしが出てくる」と考えるのは誤りです。ChatGPTが力を発揮するのは、ASRで生成されたテキストの校正・整形・要約といった工程です。逆に言えば、この役割を正確に理解して使えば、実務での時短効果は非常に大きい。文字起こしのやり方を組み立てる際には、まずこの前提から押さえてください。
文字起こしの基本手順
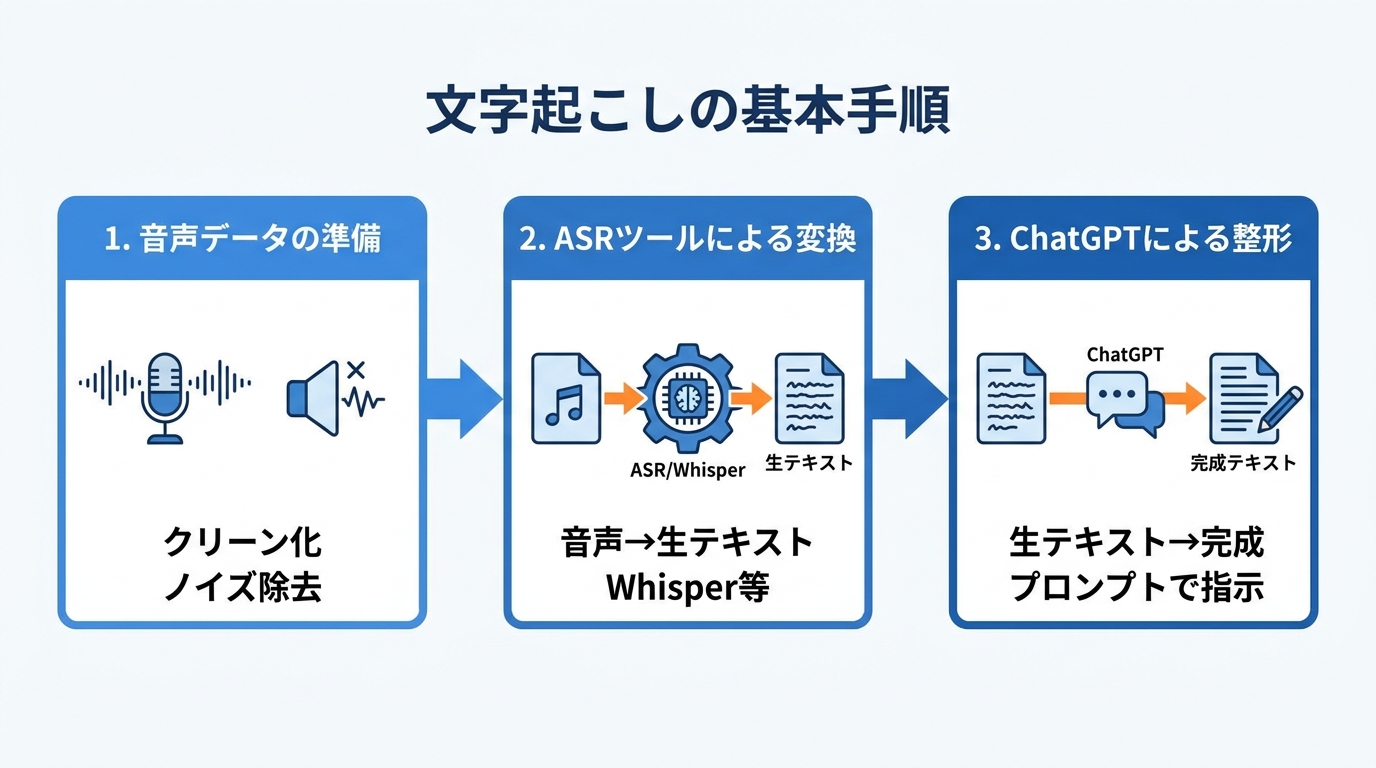
音声データの準備と抽出
文字起こしのやり方の第一歩は、できるだけクリーンな音声データを用意することです。動画から音声だけを取り出す場合はffmpegなどの変換ツールが使えます。ある実践例では、スマートフォンで録音したm4a形式のファイルをffmpegでflac形式に変換してから文字起こしに回しています(参照*4)。
音声にBGMや環境ノイズが含まれていると認識精度が落ちるため、可能であれば事前にノイズを除去しておくのが望ましいとされています。動画にBGMが入っている場合は、できる限り除去してから処理に回すことが推奨されています(参照*2)。
録音段階でマイクを話者に近づける、静かな場所で収録するといった基本的な配慮も、後工程の精度に直結します。当たり前に聞こえますが、この入力品質の差が最終的な文字起こし精度に大きく影響します。良い出力はクリーンな入力から始まる、というのは生成AI全般に共通する原則です。
Whisper等ASRツールでの変換
音声データが用意できたら、次はASRツールを使って音声をテキストに変換します。文字起こしは「自動音声認識」の工程であり、音声に特化したモデルとクリーンな入力音声が求められます(参照*2)。OpenAIが提供するWhisperは、汎用的な音声認識エンジンとして広く使われている選択肢の1つです。
ほかにもGoogle Cloudの音声認識サービスなど、複数のASRツールが利用可能です。ある事例では、Google Cloudにファイルをアップロードし文字起こしを実行する方法が紹介されています(参照*4)。
どのツールを選ぶかによって対応するファイル形式や精度は異なりますが、いずれの場合も「ASRが出力した生テキスト」には句読点の欠落や誤変換が含まれがちです。この生テキストを次の工程でChatGPTに渡して仕上げていきます。
ChatGPTへの投入と整形プロンプト
ASRから得られた生テキストをChatGPTに投入し、読みやすい文章へ整形する工程が、文字起こしのやり方の仕上げにあたります。ここで重要になるのがプロンプトの書き方です。「とにかくきれいにして」という曖昧な指示では、ChatGPTが勝手に言い回しを変えたり、内容を補ったりしてしまいます。
整形用のプロンプトでは「句読点と段落を追加し、新しい事実は加えず、元の言葉をそのまま保つ。明確でない箇所は[inaudible]または[unclear]としてそのまま残す」というルールを指示する方法が紹介されています(参照*2)。
「やってよいこと」と「やってはいけないこと」を明確に分けてプロンプトに記載すると、ChatGPTが勝手に内容を書き換えたり、情報を付け足したりするリスクを抑えられます。私がプロンプトを設計するときは、禁止事項を明示することを特に重視しています。成果物の形式についても、クリーンな書き起こしテキスト、SRT/VTT形式の字幕など、最終的に何が欲しいのかを先に決めてからプロンプトを設計すると、手戻りが減ります。
精度を高めるプロンプト設計
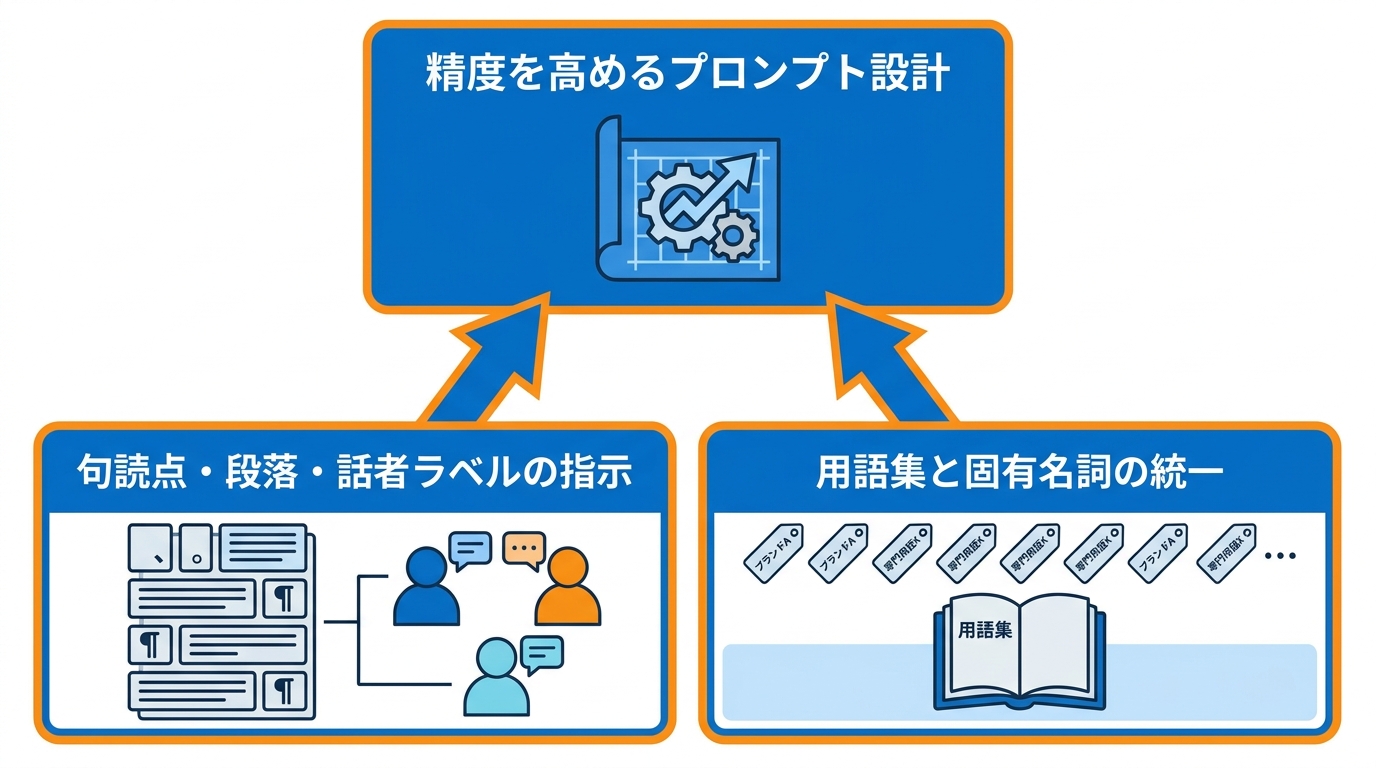
句読点・段落・話者ラベルの指示
文字起こしの精度を左右する大きな要因の1つが、整形時のプロンプト設計です。ASRの生テキストは句読点が抜けていたり、改行がなかったりするため、そのままでは読みづらい状態です。
この問題に対応するプロンプト例として「あなたは書き起こし編集者です。句読点、大文字表記、段落分けを修正してください」という役割指定に加え、「新しい事実を追加しない」「スタイルの書き換えはしない」「明らかな誤字以外は元の言葉を保つ」というルールをセットで提示する方法があります(参照*2)。
会議やインタビューなど複数の話者がいる場合は、話者ラベルの付与も指示に含めると、誰の発言かが明確になります。プロンプトに盛り込む指示が増えるほど、ChatGPTの出力は制御しやすくなりますが、矛盾する指示を入れないよう注意が必要です。
用語集と固有名詞の統一
ASRが出力したテキストでは、人名やブランド名、業界用語の表記にばらつきが出ることがあります。たとえば同じ固有名詞が複数の綴りで登場すると、検索性や正確性が損なわれます。
この対策として「用語集を使って名称・ブランド名・専門用語を統一してください」と指示し、ルールとして「用語集の正確な綴りに置き換える」「意味を変えない」「一致するか不確かな語には[CHECK TERM]とフラグを立てる」と明記するプロンプト設計が紹介されています(参照*2)。
用語集をプロンプトに添付する形で渡しておけば、ChatGPTは辞書代わりにそのリストを参照して表記を揃えます。特に繰り返し使う専門用語が多い分野では、一度用語集を作成しておくことで毎回の手直しの手間を減らせます。私の場合、媒体ごとの固有名詞リストをあらかじめ用意しておき、プロンプトに添付する運用にしています。この一手間が、後の確認作業を大幅に減らします。
用途別の時短活用術
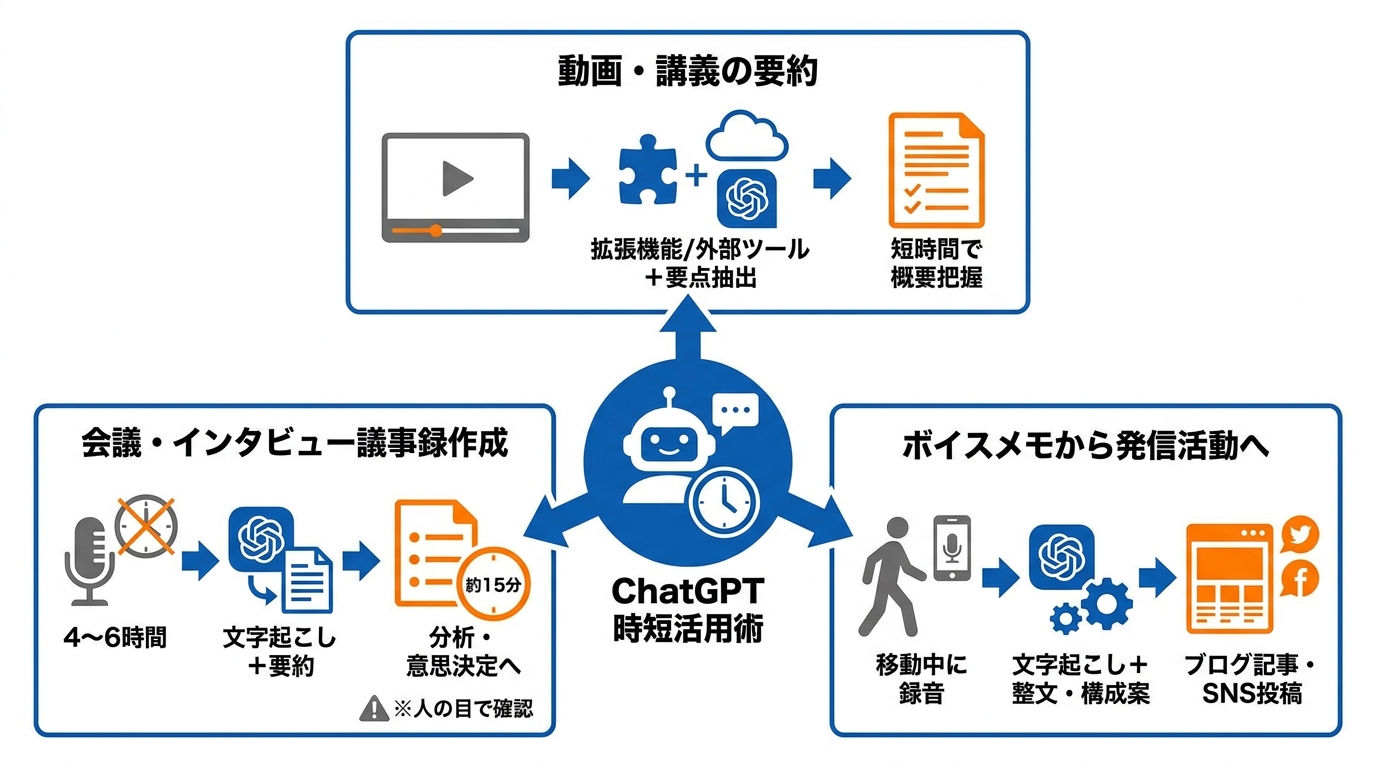
会議・インタビューの議事録作成
会議やインタビューの議事録作成は、ChatGPTによる文字起こしの時短効果が最も実感しやすい場面です。私自身、取材後の音声整理に以前は数時間を費やしていました。従来のやり方では、録音を聞き直しながらメモを整理し、テーマの抽出や要点の記述に4〜6時間かかることも珍しくありませんでした。
ある実務での事例では、話者識別付きの文字起こしを実行した後、構造化した要約プロンプトをChatGPTに渡すことで、テーマ別の要約・主要な引用・課題点・機会領域をまとめた出力を約15分で得られたと報告されています(参照*5)。
4〜6時間の作業が15分に短縮されるのであれば、浮いた時間を分析や意思決定に充てることができます。ただし、私が強調したいのは次の点です。出力された議事録は必ず人の目で内容の正確性を確認してから共有する工程を省かないこと。決定事項、未決事項、アクション、担当者、期限を分けて整理させると、実務で使える議事録になります。速さと正確さは別の話です。
YouTube動画・講義の要約
YouTube動画や講義の内容をテキスト化して要約したい場合も、ChatGPTを組み合わせたやり方が使えます。ChatGPT単体では動画URLから直接文字起こしはできませんが、専用の拡張機能を利用する方法があります。
たとえば、ChatGPT上で「YouTube Transcribe」と検索すると、動画の書き起こしに対応したGPTsが表示されます(参照*6)。また、外部ツールでは動画のURLを貼り付けるだけで数秒以内に書き起こしが生成され、.txt・.srt・.vttなど複数の形式でダウンロードできるサービスも存在します。
得られた書き起こしテキストをChatGPTに渡し、「要点を5つに絞って要約してください」などのプロンプトを使えば、長時間の講義でも短時間で概要を把握できます。
ボイスメモからブログ・SNS投稿へ
散歩中や移動中に録ったボイスメモをブログ記事やSNS投稿に変換するやり方も、ChatGPTとの相性がよい活用法です。私自身、思考が活発になりやすい移動中に音声でアイデアを記録し、後からテキストに起こして記事の下書きにするフローを取り入れています。音声入力で思いつきを記録し、後からテキストとして整える流れは、執筆のハードルを大きく下げてくれます。
ある実践例では、散歩中にボイスメモを録音するとリアルタイムで文字起こしされ、その書き起こしが自動で処理されます。件名に「Substack」と入れれば10本の投稿案が、「Newsletter」と入れればニュースレターの構成が、「Business」と入れればビジネスアイデアが生成される仕組みが紹介されています(参照*7)。
別の事例でも、旅行中に1日約15分のボイスメモを録り、文字起こし後にChatGPTで不要な言葉の除去や文法の修正を行うことでブログ記事の下書きを効率的に作成した例が報告されています(参照*4)。
精度確認とよくある失敗例
ハルシネーションと情報欠落の見分け方
ChatGPTを使った文字起こしで特に注意すべき失敗が、ハルシネーション(事実と異なる内容の生成)と情報の欠落です。AI文字起こしツールはASRとLLMの2つの基盤モデルを経由するため、それぞれの段階で偏りや捏造が発生する機会が生まれ、リスクが重なります(参照*1)。
医療分野の査読付き研究では、17の診療科にわたる33名の医師のデータを対象にAI生成の医療記録を評価した結果、1症例あたりの平均エラー数は23.6件でした。エラーの多くは重要な情報の欠落、情報の捏造、臨床用語の誤記で構成されており、文書化の正確性は72%にとどまりました(参照*3)。
こうしたリスクを見分けるには、元の音声と照合して「言っていないことが追加されていないか」「発言が抜け落ちていないか」を確認する工程が欠かせません。プロンプト設計の段階で不確かな箇所に[inaudible]や[unclear]のタグを残す指示を入れておくと、欠落箇所の特定が容易になります。AIの出力が自然に読めるほど、誤りに気づきにくくなるという逆説を意識しておくべきです。
長時間音声・専門用語での精度低下
長時間音声では、文字起こしの失敗や精度低下が起こりやすくなります。ChatGPTのアプリでは、音声入力の文字起こしが失敗して入力欄が空になる、といった不具合が報告されています(参照*8)。
専門用語が多い分野でも精度の低下が起こります。一般的な音声でのChatGPTの文字起こし精度は85〜92%程度とされており、専門的な内容になるほど誤認識が増える傾向があります。ある文書の手書き読み取りの評価では、複数のAIツールを比較した結果、ツールごとに精度差が大きく、ChatGPTは2番目に高い評価を受けた一方で、性能が低いツールでは「使い物にならない」との評価もありました(参照*9)。
長時間の音声を扱う際には、あらかじめ短い区間に分割してからASRに通し、区間ごとにChatGPTで整形するやり方が実務的な対策になります。一括処理で失敗するより、分割して確実に仕上げるほうが、結果的に時間のロスが少ないです。
プライバシーと注意点
個人情報・機密データの取り扱い
ChatGPTで文字起こしを行う際には、音声に含まれる個人情報の取り扱いに十分な注意が必要です。会議やインタビューを録音・文字起こしする場合は、事前に対象者へ録音と文字起こしの実施を伝え、データの用途・閲覧者・保存期間を明示することが求められます。EUの一般データ保護規則(GDPR)では、データの管理者はデータ主体に対して「個人データの受領者またはその分類」を提供しなければならないと定めています(参照*2)。
また、無料で利用できるGPTプラットフォームにアップロードされたデータはすべて公開領域に置かれるという指摘もあります(参照*10)。社外秘の会議録や顧客の個人情報を含む音声をそのままChatGPTに投入するやり方は避けるべきです。機密部分をマスキングしてから処理する、あるいはエンタープライズプランなどデータが学習に使われない環境を使う、といった対策が必要です。生成AI導入時の課題は、プロンプトよりもこうしたルール整備にあると私は考えています。
医療・法律など高リスク領域の限界
医療や法律といった高リスク領域では、文字起こしの誤りが深刻な結果につながる可能性があります。AIの精度は83〜90%程度であるのに対し、人間の専門家による文字起こしは99%以上の正確性を達成するとされ、その差は無視できません。さらにAIシステムは臨床上の詳細を捏造・改変するおそれがあり、HIPAA(米国の医療情報保護法)への準拠についても潜在的なリスクが残ると指摘されています(参照*3)。
コーチングの対話分析においても、手作業で7時間20分かかった内容分析をChatGPTとDeepSeekでは平均2分で処理できた一方で、無料GPTツールを対話分析に使う際のリスクと落とし穴を認識することが不可欠であると研究者は指摘しています(参照*10)。
高リスク領域でChatGPTの文字起こしを利用する場合は、必ず専門家による最終確認を組み込み、AIの出力をそのまま正式な記録として扱わない運用設計が不可欠です。AIは「候補を生成する道具」であって、「正確な記録を保証する道具」ではありません。この区別を組織内で共有しておくことが、トラブルを防ぐ最初の一歩です。
おわりに
ChatGPTを使った文字起こしのやり方は、ASRツールで音声をテキストに変換し、ChatGPTのプロンプトで整形・要約するという2段階の手順が基本です。用語集の活用や整形ルールの明示といったプロンプト設計の工夫が、精度と効率の両方を左右します。「AIに任せる部分」と「人間が確認する部分」を最初に切り分けることが、運用を安定させる鍵です。
ハルシネーションや個人情報の扱いといったリスクは常に存在するため、人による確認を最終工程に組み込むことは省けません。まずは短い音声から試し、入力品質・プロンプト設計・確認フローの3点を自分の用途に合わせて調整していくのが堅実な進め方です。速く動かすことよりも、小さく回して改善する姿勢のほうが、結果的に早く実務に定着します。
監修者
安達裕哉(あだち ゆうや)
デロイト トーマツ コンサルティングにて品質マネジメント、人事などの分野でコンサルティングに従事しその後、監査法人トーマツの中小企業向けコンサルティング部門の立ち上げに参画。大阪支社長、東京支社長を歴任したのち2013年5月にwebマーケティング、コンテンツ制作を行う「ティネクト株式会社」を設立。ビジネスメディア「Books&Apps」を運営。
2023年7月に生成AIコンサルティング、およびAIメディア運営を行う「ワークワンダース株式会社」を設立。ICJ2号ファンドによる調達を実施(1.3億円)。
著書「頭のいい人が話す前に考えていること」 が、82万部(2025年3月時点)を売り上げる。
(“2023年・2024年上半期に日本で一番売れたビジネス書”(トーハン調べ/日販調べ))
参照
- (*1) What is an AI transcription tool?
- (*2) TicNote Cloud – [Tested] Can ChatGPT Transcribe Videos? The GPT Workflow for Clean Transcripts (Alternatives Included)
- (*3) Tech Synergy – Can ChatGPT Transcribe Audio? AI Medical Dictation vs Medical Transcription Outsourcing (2026 Guide)
- (*4) Automating Travel Blogging: Voice, AI, and Hugo in One Hour
- (*5) Method Garage – Blog – Method Garage
- (*6) Mapify – 7 Ways to Transcribe YouTube Videos Free Online
- (*7) Building AI Second Brain: How I Turn Voice Memos Into Substack Notes and Business Ideas
- (*8) OpenAI Developer Community – Transcription bug in the app is still a thing
- (*9) Gamechanger: Can AI accurately transcribe primary source documents?
- (*10) Frontiers – Assessing the practicality of using freely available AI-based GPT tools for coach learning and athlete development
