
はじめに
会議や取材の録音を手作業で文字に起こす作業は、時間も集中力も消耗します。私自身、10年以上ライター業を続ける中で、インタビュー音声の文字起こしに費やした時間は相当なものでした。ChatGPTを使えば音声データから素早くテキストを得られますが、やり方を間違えるとファイルが読み込めなかったり、誤変換だらけの文章になったりします。
音声データの形式や録音環境の整え方、プロンプトの書き方を押さえるだけで、文字起こしの精度は大きく変わります。この記事では、ChatGPTで音声データを文字起こしする3つの方法と、精度を高めるための具体的なコツを順番に解説します。文字起こしはAIに任せる部分と、人間が確認・編集する部分を切り分けて考えることが重要です。その考え方も合わせて紹介します。
ChatGPT文字起こしの全体像
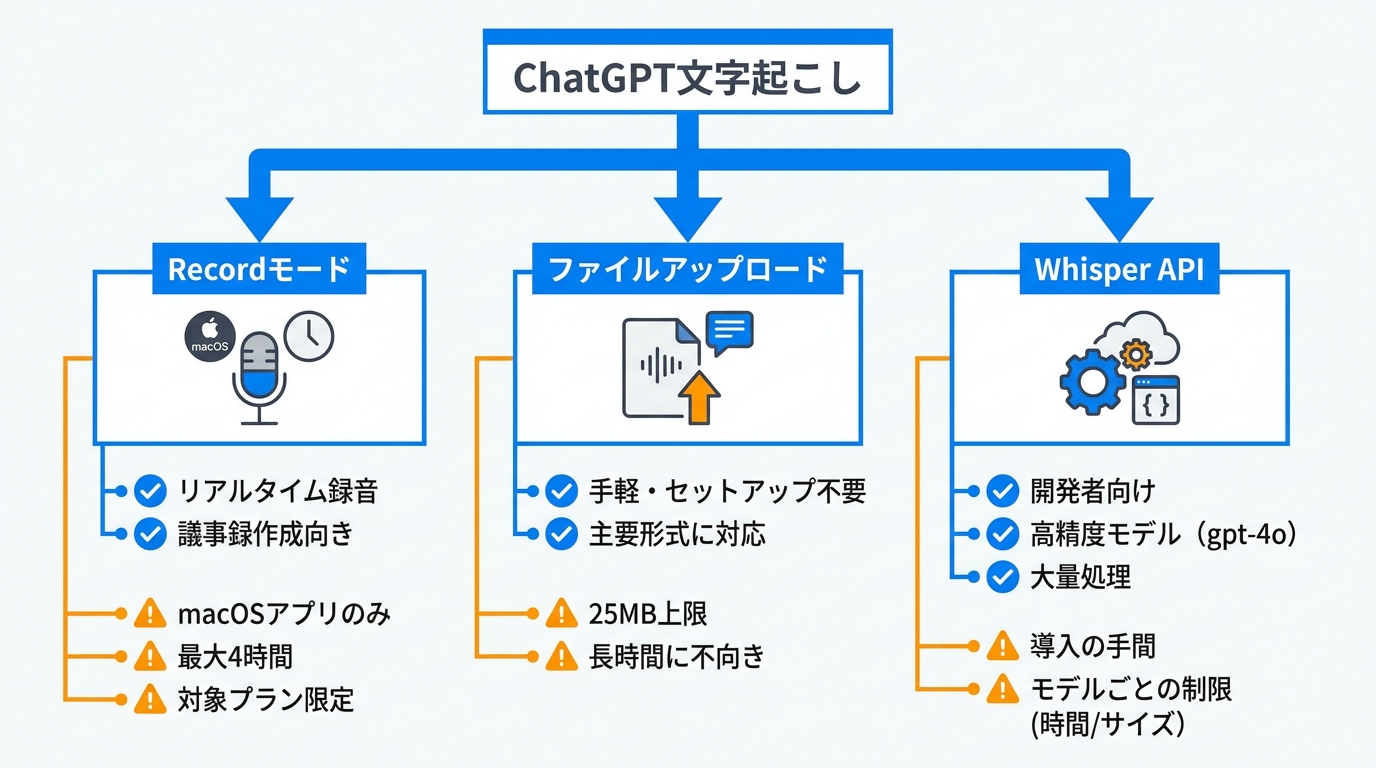
Recordモードの仕組みと制限
Recordモードは、ChatGPTのmacOS版デスクトップアプリに搭載されている録音・文字起こし機能です。アプリ上で録音を開始すると、会議やインタビューなどの音声がリアルタイムで記録され、終了後にテキストとして出力されます。録音したあとのテキストはその場で編集できるため、議事録づくりなどに向いています(参照*1)。
録音可能な時間は最大4時間(240分)です。以前は120分が上限でしたが、現在は拡張されています。ただし利用できるのはmacOSデスクトップアプリのみで、WindowsやスマートフォンのChatGPTアプリでは使えません。また、対象プランはPlus、Pro、Business、Enterprise、Eduに限られます(参照*1)。
こうした制限があるため、Recordモードは「これから行う会話をそのまま記録したい」場面に適しています。すでに手元にある音声データを文字起こしする場合は、ファイルアップロードやAPIを選ぶ必要があります。私の用途では、過去の取材音声を処理することが多いため、後述のファイルアップロードを使うことが多いです。
ファイルアップロードによる変換
ChatGPTのチャット画面に音声データを直接アップロードする方法は、セットアップ不要でもっとも手軽です。MP3、WAV、M4A、WebMなど一般的な形式に対応しており、ファイルを添付して「この音声を文字起こししてください」のようにプロンプトを入力すると、30〜90秒ほどでテキストが返ってきます(参照*2)。
ファイルサイズの上限は25MBです。たとえば45分のWAVファイルは400MBを超えることがあるため、そのままではアップロードできません。事前にMP3へ変換するか、圧縮してサイズを小さくする作業が必要です(参照*2)。
ファイルアップロードは新しいアカウントや追加ソフトを準備しなくてよい点が強みですが、25MBの壁があるため長時間の音声データには不向きです。サイズが大きい場合はファイルを分割するか、APIの利用を検討する形になります。
Whisper APIとリアルタイムAPI
OpenAIが提供する音声から文字への変換API(Speech-to-Text API)は、開発者向けの文字起こし手段です。対応モデルにはgpt-4o-transcribe、gpt-4o-mini-transcribe、話者識別つきのgpt-4o-transcribe-diarize、そして従来のwhisper-1があります(参照*1)。
gpt-4o-transcribeモデルは、従来のWhisperモデルと比べて単語誤り率が改善され、言語認識の精度も高いとされています。一方、このモデルには音声の長さが最大1,500秒(25分)という制限があります。25分を超える音声データを扱う場合は、自分でファイルを分割するか、時間制限がないwhisper-1(ファイルサイズ上限25MB)を使う方法があります(参照*3)。
APIはプログラム経由で呼び出すため、チャット画面での手動操作と比べると導入の手間がかかります。しかし大量の音声データを一括処理したい場合や、話者識別を組み込みたい場合には、APIのほうが柔軟に対応できます。生成AI導入支援の現場でも、文字起こしをAPIで自動化したいというニーズは多いのですが、最初はチャット画面での手動操作で試し、ワークフローを固めてからAPI化する順序が現実的だと伝えています。
音声データの準備と前処理
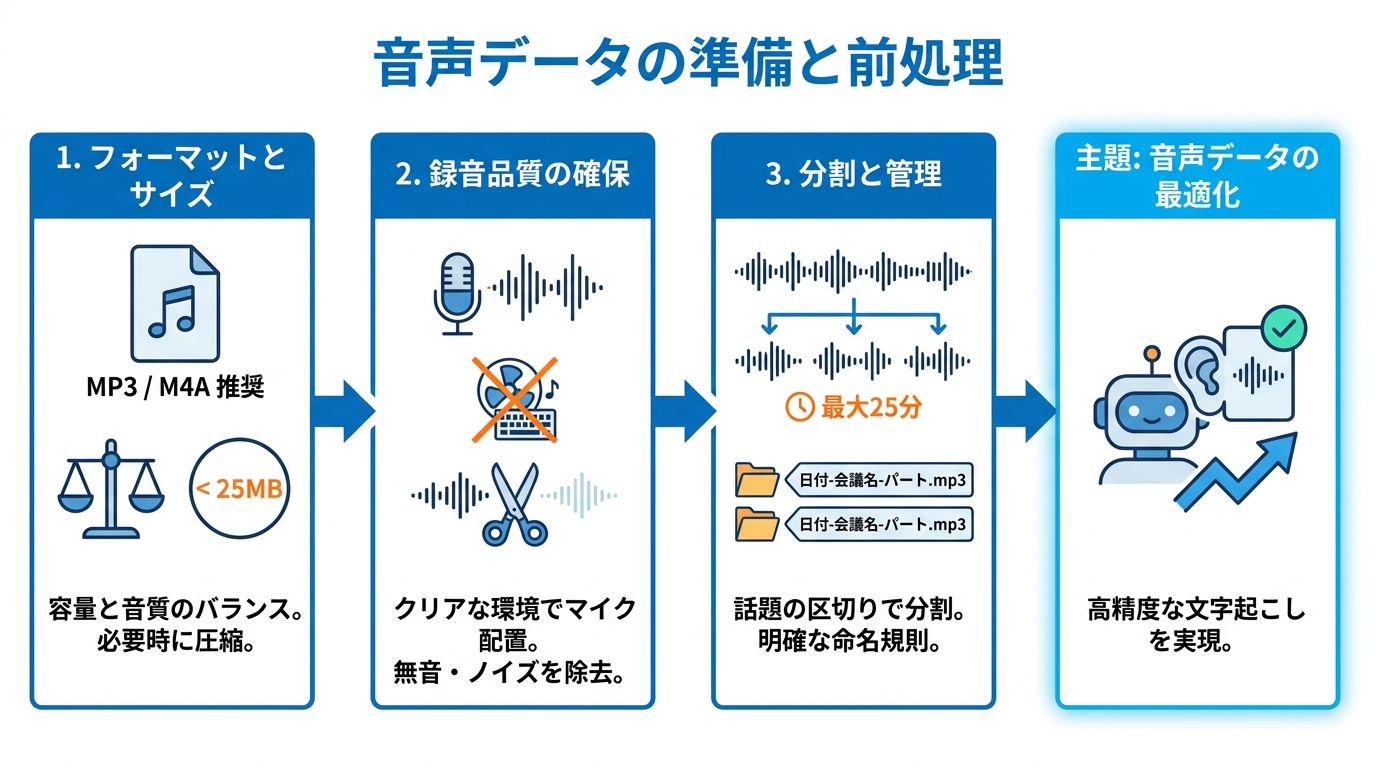
対応フォーマットとサイズ上限
ChatGPTで文字起こしに使える音声データの形式は、MP3、M4A(ボイスメモで一般的な形式)、WAVなどです。これらの一般的な形式であれば、アップロード時にエラーが出る心配はほとんどありません(参照*4)。
サイズ上限は25MBで、これはファイルアップロードとSpeech-to-Text APIの両方に共通します。WAV形式は非圧縮のため容量が大きくなりやすく、45分程度の録音で400MBを超えることもあります。こうした場合はMP3などの圧縮形式に変換してからアップロードする手順が必要です(参照*2)。
形式の選択で迷ったときは、MP3が容量と音質のバランスに優れた選択肢です。特別な理由がなければ、録音後にMP3へ変換しておくとアップロード時のトラブルを減らせます。
録音環境とマイク配置の基本
文字起こし精度に直結するのが、音声データそのものの品質です。録音段階でクリアな音声を確保できれば、後工程での修正量が大幅に減ります。英語で明瞭に録音された音声データの場合、ChatGPTは専用の文字起こしツールに匹敵する精度の書き起こしを生成でき、アクセントやフィラー(「えーと」のようなつなぎ言葉)、発話の重なりにも対応できるとの報告があります(参照*2)。日本語でも、静かな環境で録音した音声であれば精度は十分に実用範囲に入ります。逆に、カフェや屋外での録音、複数人が同時に話している場面は、どのツールを使っても精度が落ちる点は覚悟が必要です。
録音の冒頭に無音区間や環境ノイズが長く入っていると、文字起こしの処理に悪影響を与える場合があります。冒頭や途中の長い沈黙、不要な空白時間はあらかじめトリミングしておくことが推奨されています(参照*4)。
マイクは発話者にできるだけ近い位置に配置し、エアコンの送風音やキーボードの打鍵音など定常的なノイズ源を遠ざけることが基本です。複数人の会議では、卓上に1台のマイクを置くよりも、発話者ごとにマイクを分ける方が話者の分離がしやすくなります。
長時間音声の分割とファイル命名
25MBや25分の上限を超える音声データは、事前に分割してからアップロードする必要があります。gpt-4o-transcribeモデルでは音声の長さが最大1,500秒(25分)に制限されているため、それ以上のファイルは音声・動画編集ソフトなどで区切ってからモデルに渡す方法が推奨されています(参照*3)。
分割後のファイルには、日付・会議名・相手先・パート番号を含む命名規則をつけると管理しやすくなります。たとえば「2026-01-Meeting-ClientA-Part1.m4a」のように名前をつけておくと、あとからどのファイルがどの場面に対応するか迷わずに済みます(参照*4)。
分割の際は発話の途中で切らないよう、文や話題の区切りに合わせるのがポイントです。話の途中で切れたファイルをそれぞれ文字起こしすると、前後のつながりが失われて内容の把握が難しくなります。
文字起こし精度を上げるコツ
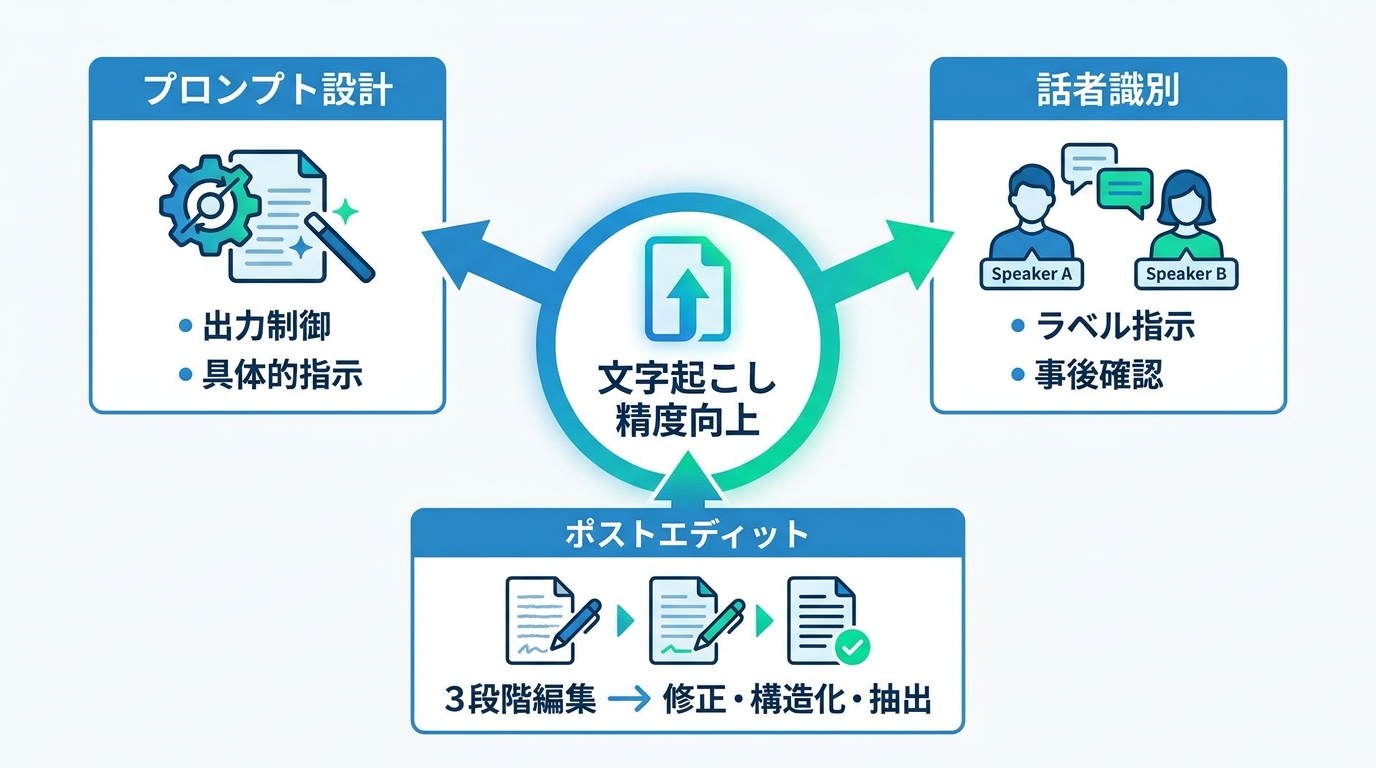
プロンプト設計で出力を制御する方法
ChatGPTに音声データを渡すとき、プロンプトの書き方ひとつで出力の形が大きく変わります。何も指定しなければ要約された文章が返ってくることがあるため、逐語的な書き起こしが欲しい場合は「この音声を逐語で文字起こししてください。要約しないでください」と明示します(参照*4)。AIへの指示は抽象的に「良い感じに」と頼むのではなく、目的、出力形式、禁止事項をセットで渡す。これは文字起こしに限らず、あらゆるAI活用に共通する原則です。
時間の目安を入れたい場合は「30〜60秒ごとにタイムスタンプを挿入してください」、聞き取れなかった箇所を明示させたい場合は「不確かな単語は[unclear]または[word?]と表記してください」と加えます。こうした指示を組み合わせることで、後工程の確認や編集が格段に楽になります(参照*4)。
プロンプトは一度に全部盛り込むより、用途に応じて組み合わせる方が安定した結果を得やすくなります。議事録なら話者ラベルとタイムスタンプ、取材原稿なら逐語書き起こしと不明箇所の明示、というように目的に合わせた構成を意識すると、後の修正量を抑えられます。私自身は「逐語書き起こし」「不明箇所は[unclear]と表記」「句読点を適切に入れる」という3点セットを基本プロンプトとして使っています。
話者識別と発言ラベルの改善
複数人の会話を文字起こしする場合、誰の発言かを区別するラベルが必要です。ChatGPTに「話者の交代を Speaker 1:、Speaker 2: のように表記してください。判別がつかない場合は Speaker A/B としてください」と指示すると、発言ごとにラベルが付きます(参照*4)。
ただし、ChatGPTのファイルアップロードによる話者識別は結果が安定しません。専用ツールのように確実にSpeaker 1、Speaker 2とタグ付けできるわけではなく、話者が入れ替わったり抜け落ちたりすることがあります(参照*2)。
話者識別の精度を上げたい場合は、APIのgpt-4o-transcribe-diarizeモデルを検討する方法があります。また、文字起こし後にチャットで「2番目の話者は誰ですか」「何に合意しましたか」と追加の質問を投げると、内容の確認や補完ができます(参照*2)。
三段階ポストエディットの手順
ChatGPTが出力したテキストをそのまま成果物にすると、句読点の抜けや表記揺れが残りがちです。これはAIの限界というより、確認工程を省いたことのリスクです。文字起こし後の編集を3段階に分けて行うと、効率よく完成度を上げられます。
第1段階は「保守的な修正」です。文言自体は変えず、句読点の追加、明らかな誤字の訂正、段落分けだけを行います。第2段階は「構造化」で、話者の交代ごとにラベルを整え、議題ごとに見出しを入れ、引用部分と数値はそのまま残します(参照*4)。
第3段階は「成果物の抽出」です。決定事項、担当者と期限つきのアクションアイテム、未解決の課題やリスクをテキストから拾い上げます(参照*4)。
この3段階を意識しておくと、最初の修正で原文の正確さを守りつつ、段階を追うごとに読みやすさと実用性を高められます。すべてを一度にやろうとすると、元の発言を歪めてしまうリスクがあるため、段階を踏む方法が有効です。AIの出力をチェックする工程を低コストに組み込む、という発想がここでも重要になります。
専用ツールとの比較・選び方
Otter・Fireflies等との精度比較
ChatGPT以外にも音声データの文字起こしに使えるツールは複数あります。ある大学の情報部門が行った検証では、Zoomの録画をAI Companionで文字起こしした場合の精度は85%で、AI Companionなしでは48%でした。外部の文字起こしアプリを使った場合は75%〜96%の範囲で、ツールによってばらつきがあったと報告されています(参照*5)。
MacWhisperは音声データをローカル(自分のパソコン上)で処理できる無料ツールで、有料のPro版では話者識別やNVIDIA製のParakeetモデルによる高速な文字起こしにも対応しています。ただしParakeetモデルは英語のみに対応しています(参照*6)。
OtterやFirefliesはライブ会議に自動でボットを参加させ、録音から文字起こしまでを一括で処理できる点が強みです。一方、ChatGPTはすでに契約しているユーザーなら追加の設定なしで即座に文字起こしができるという手軽さがあります(参照*2)。ツールを増やすほど管理コストも増えるため、すでにChatGPTを日常的に使っているなら、まずそこから試してみるのが合理的な判断です。
用途別の判断基準
ツール選びで迷ったときは、音声データの量と運用場面で判断するのが実用的です。単発の音声データを今すぐ文字起こししたい場合は、ChatGPTが手早い選択肢です。大量のファイルをまとめて処理したい場合は、複数ファイルの一括処理に対応したTurboScribeのようなツールが候補になります(参照*2)。
ライブ会議の録音・文字起こし・検索を一体で管理したい場合は、OtterやFirefliesのように会議ボットを備えたツールが合っています。費用面では、無料で使えるMacWhisperやNotebookLM(200MBまでのファイルに対応)もあり、有料サービスのAliceは1時間あたり3〜10ドル程度で高品質な文字起こしを提供しています(参照*7)。
どのツールにも得意な場面と苦手な場面があるため、扱う音声データの長さ、話者の人数、セキュリティ要件を軸に比較すると、自分の業務に合った選択肢を絞り込みやすくなります。
プライバシーとセキュリティの注意点
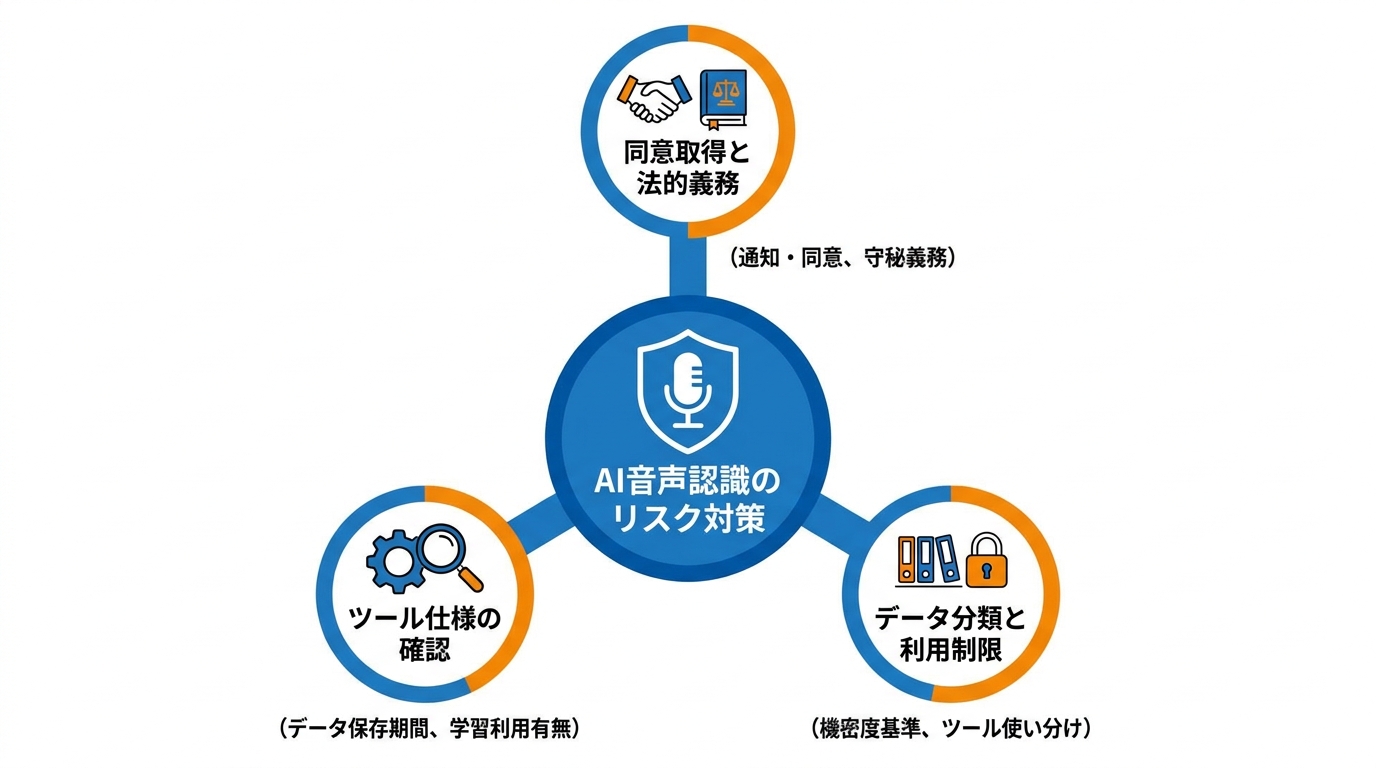
録音の同意取得と法的リスク
音声データをAIで文字起こしする前に、録音対象者への通知と同意取得が欠かせません。ニューヨーク市弁護士会は公式意見書で、AIを用いた録音システムでクライアントとの通話を記録する際は、クライアントへの通知と同意が必要であるとの見解を示しました(参照*8)。
同意見書では、会話の書き起こしを保持することが秘匿特権や守秘義務にどう影響するかを弁護士が理解する必要があるとも指摘しています。さらに、AIツールにどのようなプライバシー・セキュリティ上の保護策があるか、データの保存場所と期間、訴訟時の証拠開示の対象になるか、ツールがデータを学習に使うか、削除権があるかを確認するよう求めています(参照*8)。
弁護士向けの指針ではありますが、この考え方はビジネス全般に通じます。社内会議やクライアントとの打ち合わせを録音・文字起こしする際は、事前に同意を得ておくことがトラブル防止の基本です。「録音しています」と一言伝えるだけで済む話ですが、それを怠ったときのリスクは小さくありません。
データ保持ポリシーと機密分類
音声データの送信先でどのように保存・利用されるかは、ツールごとに異なります。ChatGPTのRecordモードでは、録音した音声は文字起こしにのみ使われ、処理後に削除されます。テキスト化された書き起こしはワークスペースの保持設定に従い、会話を削除すると関連する書き起こしも30日以内にOpenAIのシステムから消去されます。Speech-to-Text APIでは、送信した音声データについてトレーニングへの使用も、不正利用監視のための保持も、現在は行われていないと説明されています(参照*1)。
一方、大学や研究機関ではより厳格なルールが設けられています。ある大学は、機密性の高い研究データや法令で保護される情報(HIPAAやFERPAの対象データなど)について、公開版のChatGPTを含むパブリックAI翻訳ツールの使用を禁止しています(参照*9)。
別の大学でも、Fireflies.ai、Otter.ai、OpenAI(ChatGPT)などの大学未認可のサードパーティAIアプリには、学内のZoom会議へのアクセスやデータの読み書き・削除権限を許可していません(参照*10)。
音声データを外部サービスに送る前に、自社や所属組織のデータ分類基準を確認し、機密度に応じてツールを使い分けることが欠かせません。生成AI導入で最初に詰まるのはプロンプトよりも、こうしたルール整備と責任範囲の定義です。便利だから使う、だけでは組織では通りません。
おわりに
ChatGPTで音声データを文字起こしするには、Recordモード、ファイルアップロード、APIという3つの方法があり、それぞれファイル形式やサイズの制限が異なります。精度を高めるには、録音段階での音質確保、25MB以内への圧縮・分割、そしてプロンプトでの出力形式の指定が有効です。文字起こしそのものはAIに任せられますが、出典確認・事実確認・最終判断は人間が担う、という役割分担を明確にしておくことが実務では重要です。
文字起こし後の三段階編集で実用性を上げつつ、録音の同意取得やデータ保持ポリシーの確認も忘れずに行うことで、業務に安心して活用できる体制が整います。AIを使うことが目的ではなく、議事録や取材メモとして使える成果物を効率よく作ることが目的です。その意識を持って運用すれば、文字起こしはすぐにでも業務改善につながる領域です。
監修者
安達裕哉(あだち ゆうや)
デロイト トーマツ コンサルティングにて品質マネジメント、人事などの分野でコンサルティングに従事しその後、監査法人トーマツの中小企業向けコンサルティング部門の立ち上げに参画。大阪支社長、東京支社長を歴任したのち2013年5月にwebマーケティング、コンテンツ制作を行う「ティネクト株式会社」を設立。ビジネスメディア「Books&Apps」を運営。
2023年7月に生成AIコンサルティング、およびAIメディア運営を行う「ワークワンダース株式会社」を設立。ICJ2号ファンドによる調達を実施(1.3億円)。
著書「頭のいい人が話す前に考えていること」 が、82万部(2025年3月時点)を売り上げる。
(“2023年・2024年上半期に日本で一番売れたビジネス書”(トーハン調べ/日販調べ))
参照
- (*1) VoiceScriber – Can ChatGPT Transcribe Audio? 2026 Limits, File Uploads, Privacy & Offline iPhone Alternative
- (*2) RECAP – Can ChatGPT Transcribe Audio? Yes
- (*3) OpenAI Developer Community – GPT4.0-Transcribe-MAX 1500 SECONDS?
- (*4) TicNote Cloud – Can ChatGPT Transcribe Audio? Record Mode, Uploads, Whisper, Limits, and Best Alternatives
- (*5) Zoom – Transcriptions
- (*6) What can I use for secure transcription of sensitive audio or video?
- (*7) Gear I pack for conferences, plus my AI toolkit for follow-up
- (*8) New York City Bar Association – Formal Opinion 2025-6: Ethical Issues Affecting Use of AI to Record, Transcribe, and Summarize Conversations with Clients
- (*9) Managing Sensitive Research Data at Duke
- (*10) Upcoming change to third-party AI app access
